UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ (ai)
19 апреля 2024, 10:12
2024-04-19
Meta представила Llama 3. Конечно, компания утверждает, что это одна из лучших доступных открытых моделей на сегодняшний день
Компания Meta выпустила последнюю новинку в серии Llama — открытых генеративных моделей искусственного интеллекта: Llama 3. Точнее, компания представила две модели из нового семейства Llama 3, а остальные появятся в будущем, но пока неизвестно когда.
Компания Meta выпустила последнюю новинку в серии Llama — открытых генеративных моделей искусственного интеллекта: Llama 3. Точнее, компания представила две модели из нового семейства Llama 3, а остальные появятся в будущем, но пока неизвестно когда.
Цель описывает новые модели — Llama 3 8B, содержащую 8 млрд параметров, и Llama 3 70B, содержащую 70 млрд параметров — как «большой скачок» по производительности по сравнению с моделями Llama предыдущего поколения — Llama 2 8B и Llama 2 70B, пишет TechCrunch.
Параметры по существу определяют умение модели ИИ решать задачи, например, анализировать и генерировать текст; модели с большим количеством параметров, в общем говоря, более способны, чем модели с меньшим количеством параметров. То есть Цель фактически утверждает, что Llama 3 8B и Llama 3 70B, обученные на двух специально созданных кластерах из 24 000 GPU, являются одними из самых эффективных генеративных моделей искусственного интеллекта, доступных сегодня.
Как же Meta подтверждает свое смелое заявление, что Llama 3 является одной из самых доступных открытых моделей?
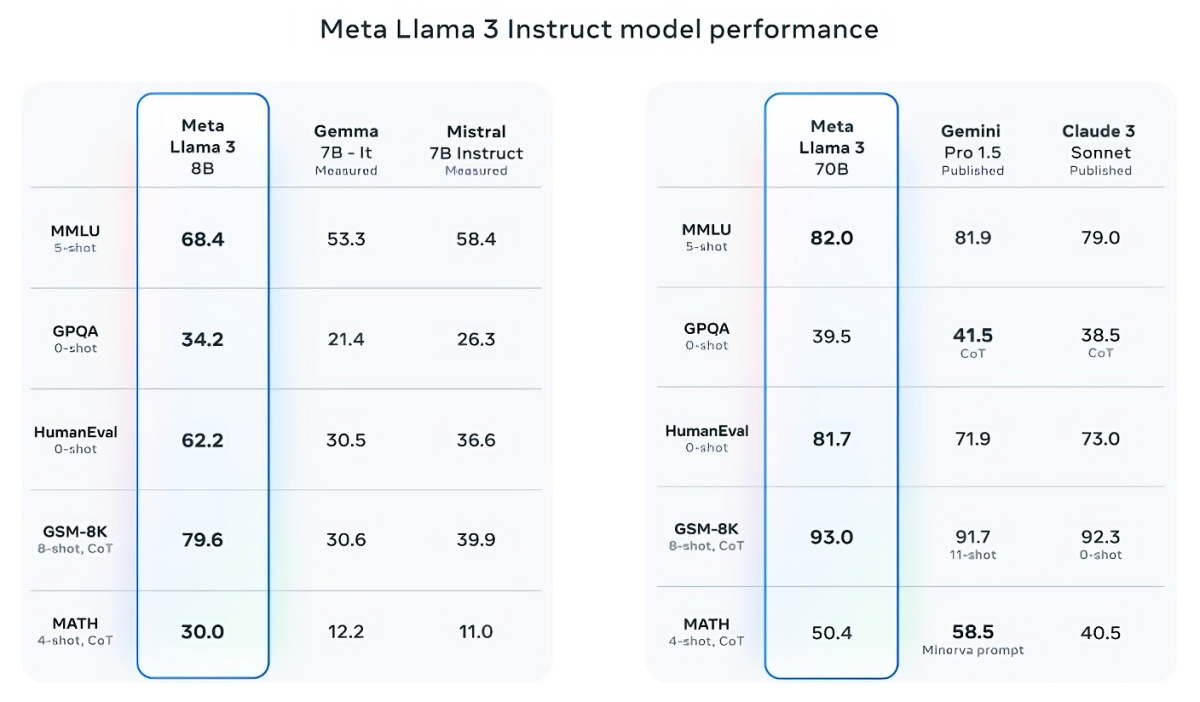
Компания указывает на результаты моделей Llama 3 по таким популярным тестам ИИ, как MMLU для измерения знания, ARC — измеряет приобретение навыков и DROP — тестирует работу модели над фрагментами текста. Эти тесты ИИ остаются одним из немногих стандартизированных способов, с помощью которых игроки в области ИИ оценивают свои модели.
Llama 3 8B превосходит другие открытые модели, такие как Mistral 7B от Mistral и Gemma 7B от Google, обе из которых содержат 7 млрд параметров, по крайней мере, по девяти тестам: MMLU, ARC, DROP, GPQA (набор вопросов по биологии, физике и химии), HumanEval (тест на создание кода), GSM-8K (математические текстовые задачи), MATH (другой математический тест), AGIEval (набор тестов для решения задач) и BIG-Bench Hard (оценка здравого смысла).
Теперь Mistral 7B и Gemma 7B не совсем на передовой (Mistral 7B был выпущен в сентябре прошлого года), и в нескольких тестах, приведенных Meta, Llama 3 8B опережает их всего на несколько процентных пунктов. Но Meta также утверждает, что Llama 3 70B может конкурировать с Gemini 1.5 Pro — последней моделью в серии Gemini от Google.
Фото: TechCrunch
Llama 3 70B побеждает Gemini 1.5 Pro в тестах MMLU, HumanEval и GSM-8K, и хотя она не конкурирует с самой производительной моделью Anthropic, Claude 3 Opus Llama 3 70B показывает лучшие результаты, чем другая самая слабая модель серии Claude 3, Claude 3, в пяти тестах (MMLU, GPQA, HumanEval, GSM-8K и MATH).
Фото: TechCrunch
Meta также разработала собственный набор тестов, охватывающий различные варианты использования: от кодирования и написания текстов до рассуждений и подведения итогов. По данным тестов Llama 3 70B победила модель Mistral Medium от Mistral, GPT-3.5 от OpenAI и Claude Sonnet. Компания Meta утверждает, что она закрыла доступ к набору для своих моделирующих команд, чтобы сохранить объективность, но, очевидно, учитывая, что Meta сама разработала тест, результаты следует воспринимать с определенной долей скептицизма.
Фото: TechCrunch
Цель говорит, что пользователи новых моделей Llama могут ожидать большей «управляемости», меньшей вероятности отказа отвечать на вопросы и большей точности в мелочах, вопросах, касающихся истории и STEM-отраслей, таких, как инженерия и наука, а также общих рекомендаций по кодированию. Частично это стало возможным благодаря гораздо большему набору данных: коллекции из 15 триллионов токенов, или около 750 000 000 000 000 слов — в семь раз больше учебной базы Llama 2. (В сфере ИИ «токенами» называют разделенные биты необработанных данных, как вот слоги «фан», «тас» и «тыч» в слове «фантастический»).
Meta не ответила откуда взялись эти данные, лишь указала, что они были взяты из «общедоступных источников», содержали в четыре раза больше кода, чем в учебном наборе данных Llama 2, и что 5% этого набора содержат неанглийские данные (приблизительно на 30 языках) для улучшения производительности на языках, отличных от английского. Цель также заявила, что использует синтетические данные, то есть данные, сгенерированные искусственным интеллектом, для создания более длинных документов, на которых учатся модели Llama 3, что является несколько противоречивым подходом из-за потенциальных недостатков в производительности.
«Хотя модели, которые мы выпускаем сегодня, настроены только для исходных данных на английском языке, увеличенное разнообразие данных помогает моделям лучше распознавать нюансы и закономерности и эффективно выполнять различные задачи», — пишет компания.
О токсичности и предвзятости Цель заявляет, что разработала новые конвейеры фильтрации данных для повышения качества обучающих данных своих моделей, а также обновила пару пакетов безопасности для генеративного ИИ, Llama Guard и CybersecEval, чтобы предотвратить неправомерное использование и нежелательное генерирование текстов моделями Llama.
Модели Llama 3 уже доступны для скачивания и обеспечивают работу помощника Meta AI в Facebook, Instagram, WhatsApp, Messenger. В скором времени будут размещены в управляемой форме на многих облачных платформах, включая AWS, Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX от IBM, Microsoft Azure, NIM от Nvidia и Snowflake. В будущем будут доступны версии моделей, оптимизированные для оборудования от AMD, AWS, Dell, Intel, Nvidia и Qualcomm.
Модели Llama 3 могут быть широко доступны как для исследовательских, так и для коммерческих приложений. Однако Meta запрещает разработчикам использовать модели Llama для обучения других генеративных моделей, а разработчики приложений из более чем 700 млн пользователей ежемесячно должны запрашивать специальную лицензию от Meta, которую компания предоставит или не предоставит по своему усмотрению.
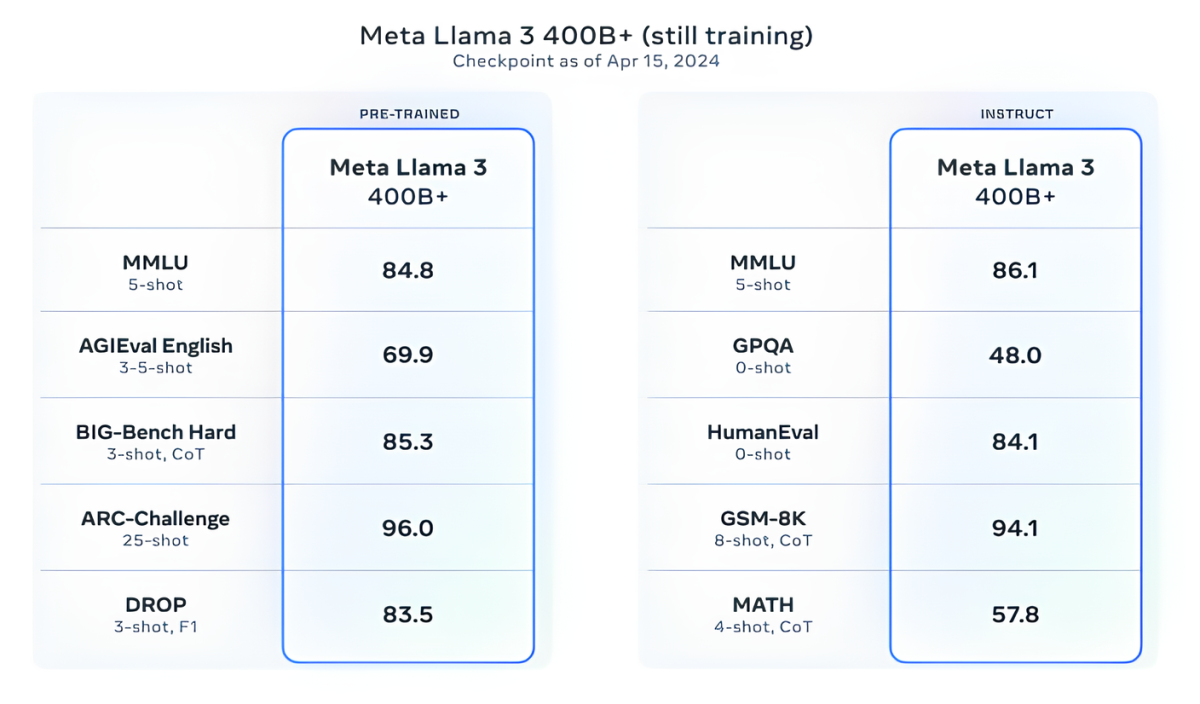
Meta заявляет, что в настоящее время она обучает модели Llama 3 размером более 400 млрд параметров — модели, способные «разговаривать на нескольких языках», принимать больше данных и понимать изображения и другие модальности, а также текст, который приведет серию Llama 3 в соответствие с открытыми релизами, таких как Hugging Face’s Idefics2.
«Есть ли у меня талант, если компьютер может имитировать меня?». Искусственный интеллект пишет книги авторам Amazon Kindle. The Verge пообщался с авторами и обнаружил много интересного
Писатели-романисты используют искусственный интеллект для создания своих произведений. Издание о технологиях The Verge пообщалось с писательницей Дженнифер Лепп, выпускающей новую книгу каждые девять недель, и узнало о том, как работает искусственный интеллект для написания романов. Приводим адаптированный перевод статьи.
Хотите сообщить важную новость? Пишите в Telegram-бот
Главные события и полезные ссылки в нашем Telegram-канале