UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоHot News
13 June 2025, 11:05
2025-06-13
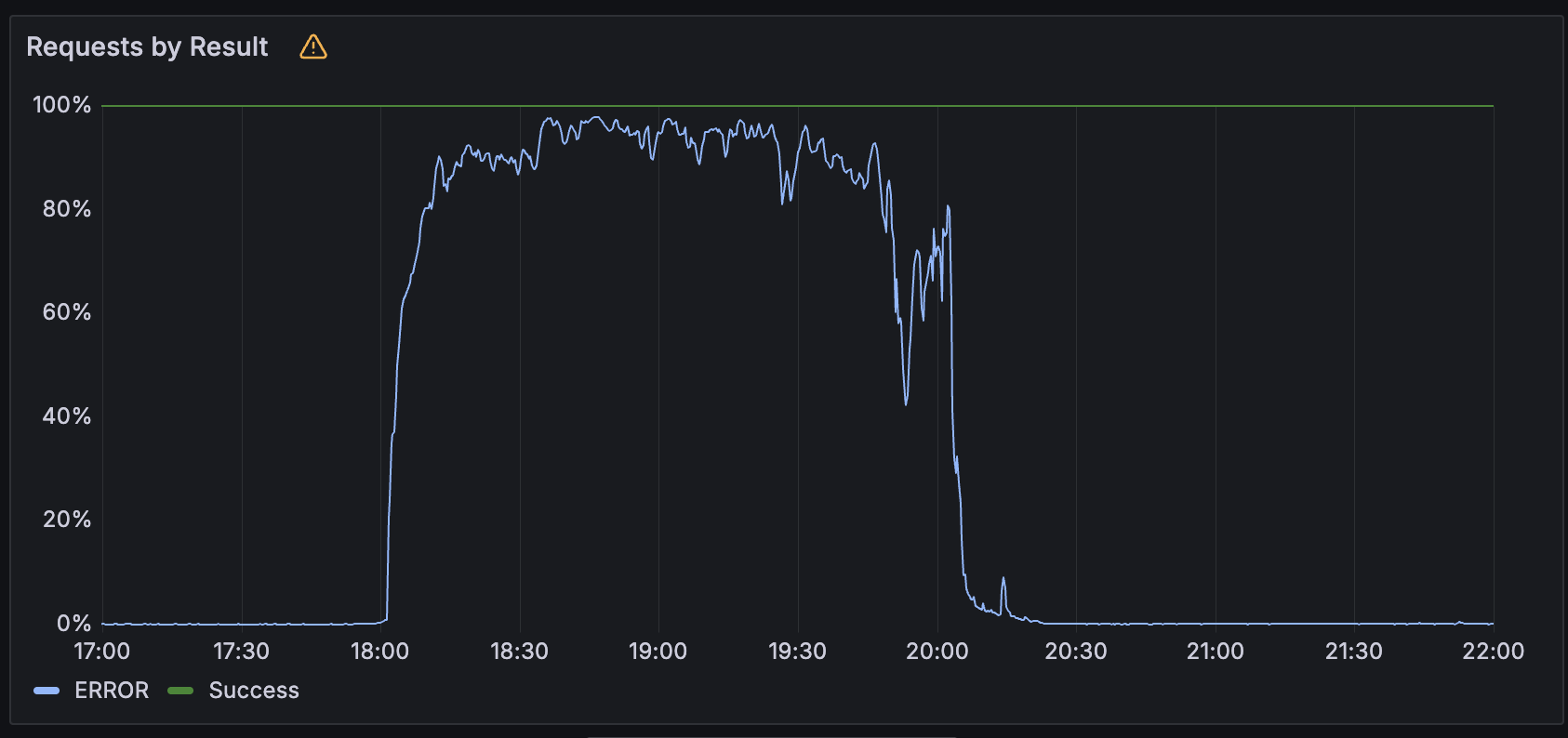
Google Cloud outage causes more than 50 services to fail. The company explains the cause of the incident, which lasted 3 hours
On Thursday, major online platforms experienced major outages due to technical issues with Google’s cloud services. Among those affected were Spotify, Discord, Snapchat, Character.ai, Discord, Cursor, and others.
On Thursday, major online platforms experienced major outages due to technical issues with Google’s cloud services. Among those affected were Spotify, Discord, Snapchat, Character.ai, Discord, Cursor, and others.
On Thursday, thousands of users reported outages across many different apps: Spotify, Discord, Snapchat, Character.AI, Cursor, Replit, which rely on Google’s cloud-managed services and infrastructure.
Among the affected services is global cloud platform Cloudflare, which reported on its website that the outage lasted 2 hours and 28 minutes and globally affected all Cloudflare customers using the relevant services.
«On June 12, 2025, Cloudflare experienced a significant outage that impacted a large set of our critical services, including Workers KV, WARP, Access, Gateway, Images, Stream, Workers AI, Turnstile and Challenges, AutoRAG, Zaraz, and parts of the Cloudflare Dashboard,» the message said.
This was caused by a failure in the underlying storage infrastructure used by the company’s Workers KV service, which is critical to many Cloudflare products and relies on for configuration, authentication, and delivery of resources across the affected services. Part of this infrastructure is supported by third-party cloud provider Google Cloud, which experienced a failure today, directly impacting the availability of the KV service.
«This was not the result of an attack or other security-related event. No data was lost as a result of this incident. Cloudflare Magic Transit and Magic WAN, DNS, cache, proxy, WAF, and related services were not directly impacted by this incident,» the company, whose shares fell 5% on Thursday, said.
According to Down Detector, users reported issues on Discord, Google (Google Cloud, Gmail, Google Meet, and others), Spotify, Twitch, character.ai, Rocket league, Cloudflare, Etsy, the Pokémon Trading game, Snapchat, Anthropic, Shopify, Gemini, Ikea, Marvel, Vimeo, OpenAI, and others.
Google said the incident caused problems for 13 of the company’s cloud services in the US, Europe and Asia.
What happened — Google Cloud explanation
The incident, which the company marked as global, began at 10:49 a.m. Pacific Time and lasted 3 hours.
«Based on our initial analysis, the issue was caused by an invalid automatic quota update in our API management system that was distributed globally, which resulted in external API requests being rejected. To recover, we bypassed the quota check, which allowed us to recover in most regions within 2 hours. However, the quota policy database in us-central1 became overloaded, which resulted in a much longer recovery time in that region. A few products experienced a moderate residual impact (e.g., lag) for an hour after the primary issue was resolved, and a small number of products recovered thereafter. Google will complete a full incident report in the coming days, detailing the root cause,» the company explains .
«We are very sorry for the impact of this service outage/disruption on all our users and their customers. In the coming days, we will publish a full incident report with the root cause, detailed timeline, and actionable remediation measures we will take,» Google Cloud notes.
This outage highlights the widespread reliance of both businesses and consumers on cloud infrastructure, and short-term outages can impact global digital communications, logistics, and productivity tools.
The Google Cloud outage is another reminder that even the largest and most technologically advanced cloud providers are not immune to errors, says Kyrylo Naumenko, the service manager of the Ukrainian cloud operator GigaCloud.
«In this case, the cause was exceeding quotas in the API management subsystem, which led to large-scale unavailability of services in different parts of the world. Such an event immediately affects not only millions of end users, but also businesses, for which even a short downtime means real financial losses. This once again confirms: 100% reliability does not exist,» Naumenko noted in a comment for dev.ua.
In his opinion, dependence on one provider is a high risk.
«Businesses need to think a few steps ahead and implement resilience strategies: redundant environments, hybrid or multi-cloud infrastructure, disaster recovery plans, and solutions like Business Continuity. At GigaCloud, we can clearly see how demand for these services has grown over the past year — by at least 25%. This indicates a change in approach: companies are no longer hoping that „it won’t happen“ — they are preparing for what will definitely happen, the only question is when.»