UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоAI Eng
19 September 2025, 09:13
2025-09-19
Mistral's updated Magistral Small 1.2 reasoning model analyzes images and can fit on a MacBook
French AI company Mistral has released a new pair of models — the Magistral Small 1.2 and Magistral Medium 1.2 LLM. Both models feature a visual encoder that allows them to analyze images sent to them by users. They also feature performance improvements across key benchmarks, as well as enhanced usability features.
French AI company Mistral has released a new pair of models — the Magistral Small 1.2 and Magistral Medium 1.2 LLM. Both models feature a visual encoder that allows them to analyze images sent to them by users. They also feature performance improvements across key benchmarks, as well as enhanced usability features.
As Hugging Face’s head of machine learning development Ahsen Halik noted at X, the most impressive thing is that the 24 billion parameter version of Magistral Small 1.2 — after quantization, i.e. converting its internal settings to fewer bits to save space and reduce power consumption, in exchange for some loss of accuracy — can be deployed locally, “fitting on a single [Nvidia] RTX 4090 [GPU] or an [Apple] MacBook with 32GB of RAM…”.
The code is already available for download on Hugging Face . You can also chat directly with models on Le Chat , a chatbot website from Mistral and a competitor to ChatGPT, VentureBeat writes .
For developers, the models are available via the Mistral API at "magistral-small-2509" and "magistral-medium-2509" respectively.
These models can be considered as options for performing tasks related to language, mathematics, coding, logical analysis, and image analysis.
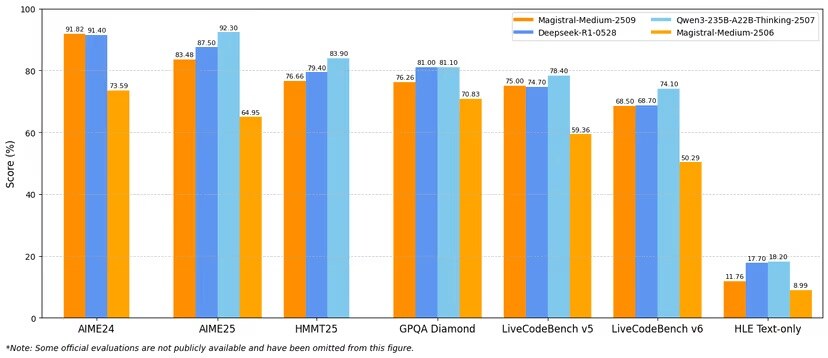
With the release of update 1.2, Mistral AI is showing the highest performance in a number of public benchmarks. This can be seen in the comparison charts below.
Source: VentureBeat
In the AIME24 math benchmark, Magistral Medium 1.2 scored 91.82%, slightly ahead of Deepseek-R1 (91.40%) and significantly outperforming Magistral Medium 1.0 (73.59%).
While Qwen3-235B-A22B-Thinking slightly leads in HMMT25, GPQA Diamond, and LiveCodeBench v6, Magistral Medium 1.2 holds its ground and consistently outperforms its predecessors and most competitors in AIME and LiveCode coding tasks.
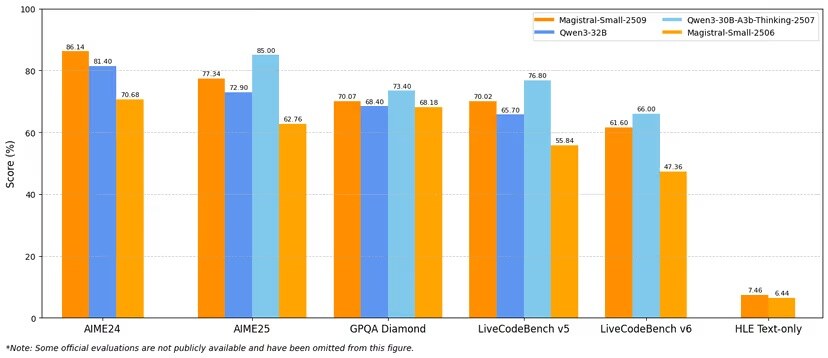
Magistral Small 1.2 also demonstrates clear advantages over versions 1.0 and 1.1 and competes with much larger models.
Source: VentureBeat
While the Qwen3-30B-A3b-Thinking model leads in some tasks, such as AIME25 and GPQA, the Magistral Small 1.2 consistently outperforms its predecessor and competitors, including the Qwen3-32B, especially in code-related tests such as LiveCodeBench.
The main feature of the version 1.2 updates is support for multimodal inputs.
Both models now feature a visual encoder that allows them to interpret and analyze text and images. This addition expands the range of tasks the models can handle, including answering visual questions, interpreting code diagrams, and analyzing layouts.
Mistral highlights improved reasoning structure and output formatting in version 1.2. Answers are now more natural and concise, especially for simple prompts. LaTeX and Markdown support has been improved, reducing the difficulty for developers working on technical tasks.
Models have also become more adept at using external tools such as web search, code interpreters, and image generators, with better logic about when and how to use these tools.
Both models introduce special tokens [THINK] and [/THINK] to denote reasoning traces for easier review by developers, which structures the model's outputs into internal reasoning and then a final answer, which is useful for tracking and debugging.
Magistral 1.2 models support over two dozen languages, including French, German, Arabic, Japanese, and Chinese, and are designed to maintain quality output for context windows up to 128,000 tokens. However, Mistral notes that performance is optimal at 40,000 tokens.
Як нейромережі бачать вільну та незалежну Україну? Тест dev.ua
Нейронні мережі для генерації зображень бачать світ по-своєму, їхню логіку зрозуміти часом зовсім неможливо. Але таки хочеться. На честь Дня Незалежності України редакція dev.ua вирішила провести невеликий експеримент.
Ми задали чотирьом різним нейронним мережам п’ять однакових запитів: «прапор України», «День Незалежності України», «український Крим», «перемога України» та «українці». Отриманими результатами ми ділимося з вами нижче.
У TikTok тепер можна генерувати фон за допомогою нейромережі. Ми протестували її та ділимося результатами
У TikTok з’явилася нова функція «Розумний фон». З її допомогою як фон для тіктоків можна підставляти згенеровані нейромережею зображення. Редакція dev.ua протестувала цю технологію і ділиться своїми враженнями.