UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоAI Eng
12 June 2026, 13:15
2026-06-12
Google's new AI model: DiffusionGemma is 4 times faster and transfers image generation techniques to texts
Google DeepMind has unveiled a new experimental language model. It uses techniques originally developed for AI image generators, allowing it to speed up text generation by up to 4x when running on resource-constrained consumer hardware. The model is available for free download and requires only 18GB of RAM or video memory to run.
Google DeepMind has unveiled a new experimental language model. It uses techniques originally developed for AI image generators, allowing it to speed up text generation by up to 4x when running on resource-constrained consumer hardware. The model is available for free download and requires only 18GB of RAM or video memory to run.
The DiffusionGemma model is the latest addition to Google’s family of open-weight models. However, unlike Gemma 2, which was released this spring, this 26 billion-parameter Mixture of Experts (MoE) architecture model is not a large language model in the classical sense, The Register reports .
In fact, it is closer to image generators like Stable Diffusion or Flux. Instead of the usual step-by-step writing of text (word by word), DiffusionGemma outputs entire paragraphs of text at a time.
The process is very similar to how a diffusion model converts what is essentially static into an image through a series of noise reduction steps.
As Google explains, DiffusionGemma works on the principle of creating a "canvas" of random tokens, which are then gradually improved until the final text is formed.
Unlike classic large language models, which are limited by memory bandwidth and require large amounts of video memory, the workload of diffusion models is largely dependent on computing power. That is why the company is positioning these models for local deployment.
Large language models are autoregressive. During token generation, the active model parameters must be read from memory for each token generated, making memory bandwidth a major bottleneck.
In the cloud, inference service providers balance computing power and memory bandwidth by processing hundreds or thousands of queries in parallel. A typical user running a local model on their laptop cannot do this.
However, many consumer products, such as high-end graphics cards, have a large amount of computing power that DiffusionGemma can use to increase the generation speed.
However, diffuse language models are not perfect, and Google is not the first to explore this technology. Previous models, such as DREAM or Mercury 2, showed significant speedups over classical LLMs, but generally lagged behind them in benchmarks (performance tests) for their size.
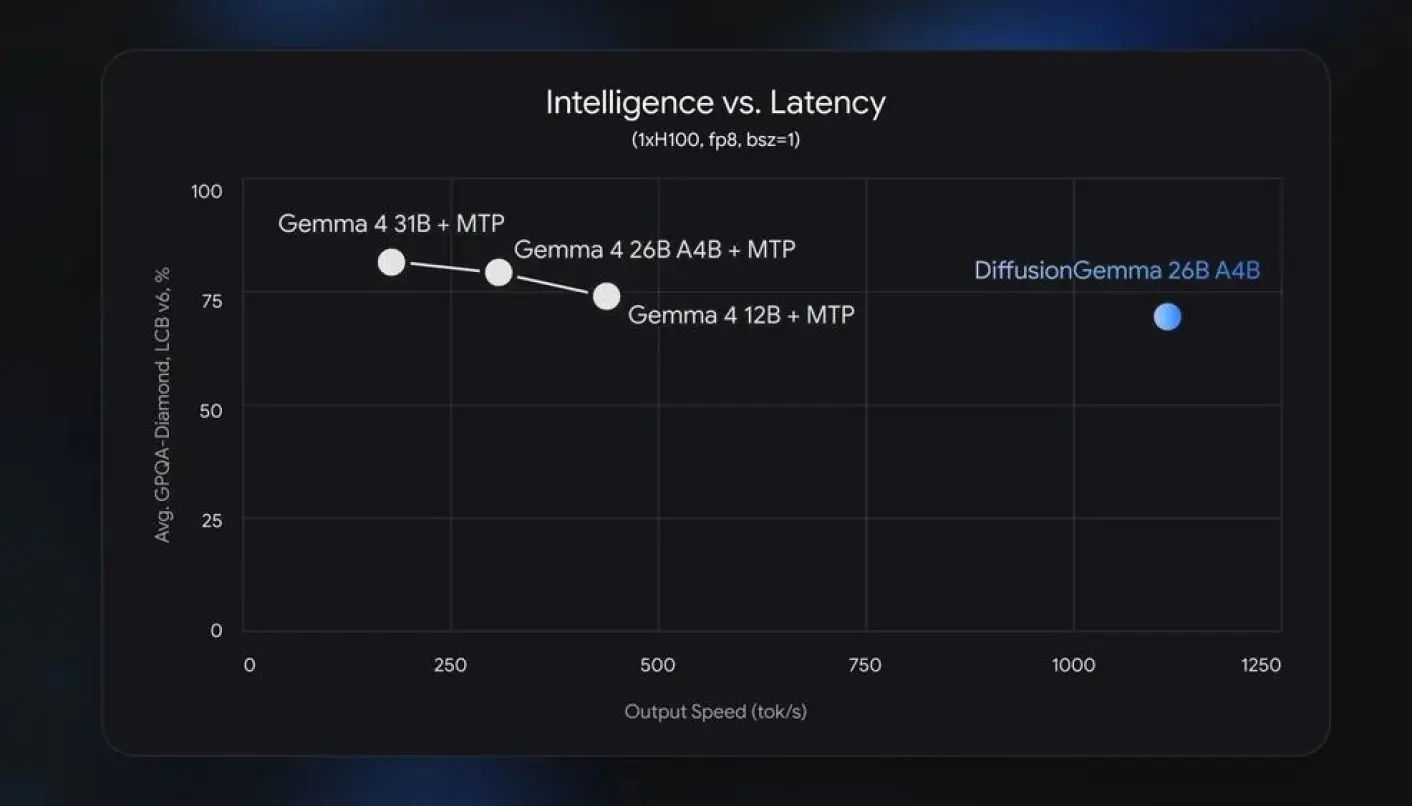
It seems that DiffusionGemma is no exception. According to Google, this model with 26 billion parameters is slightly inferior to Gemma 2 12B in the GPQA-Diamond benchmark. Its main advantage is precisely the speed of text generation, and even that turned out to be not as impressive as Google portrays it.
The graph shows an approximately 2.25x speedup of DiffusionGemma compared to LLM at 12 billion parameters with speculative decoding enabled. When compared to Gemma 2 26B-A4B, the speedup increases by almost 4x when running on a single Nvidia H100 graphics card.
DiffusionGemma is being released as an experimental model, not aimed at the corporate segment, as was the case with Gemma 2.
The model is already available for download on popular repositories like Hugging Face under the very liberal Apache 2.0 license. Support for the new model has already been integrated into such well-known inference engines as vLLM, MLX, and HF Transformers, and support for Llama.cpp will be available soon.
Як нейромережі бачать вільну та незалежну Україну? Тест dev.ua
Нейронні мережі для генерації зображень бачать світ по-своєму, їхню логіку зрозуміти часом зовсім неможливо. Але таки хочеться. На честь Дня Незалежності України редакція dev.ua вирішила провести невеликий експеримент.
Ми задали чотирьом різним нейронним мережам п’ять однакових запитів: «прапор України», «День Незалежності України», «український Крим», «перемога України» та «українці». Отриманими результатами ми ділимося з вами нижче.