UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Марія БровінськаAI Eng
24 June 2026, 09:05
2026-06-24
Empero released an uncensored Qwythos-9B model — and said it trained it on data from the closed Claude Mythos
Empero AI has published an open model, Qwythos-9B, on HuggingFace — a compact reasoning model based on Qwen3.5-9B with full fine-tuning and intentionally disabled constraints. Technically, the model is interesting, but its appearance immediately raised a painful question for the AI industry: is it legal to train models on synthetic data generated by closed commercial systems?
Empero AI has published an open model, Qwythos-9B, on HuggingFace — a compact reasoning model based on Qwen3.5-9B with full fine-tuning and intentionally disabled constraints. Technically, the model is interesting, but its appearance immediately raised a painful question for the AI industry: is it legal to train models on synthetic data generated by closed commercial systems?
What is Qwythos?
Qwythos-9B is a fully fine-tuned version of Qwen3.5-9B, post-trained on over 500 million tokens with chain-of-thought traces generated by Empero using its own rethink tool. Main technical specifications:
Context window of 1,048,576 tokens (~1M) — thanks to YaRN rope-scaling with a factor of ×4 compared to the native architecture. One of the longest windows among open 9B models, allowing you to keep entire codebases, dozens of scientific articles, or long agent sessions in context.
Native function calling according to the Qwen3.5 specification — without additional fine-tuning for instruments.
Self-correction with tools — in Empero’s own tests on 7 complex prompts (mathematics, cybersecurity, clinical pharmacology, biochemistry), the model correctly answered all 7, using Python-executor and web search and citing sources.
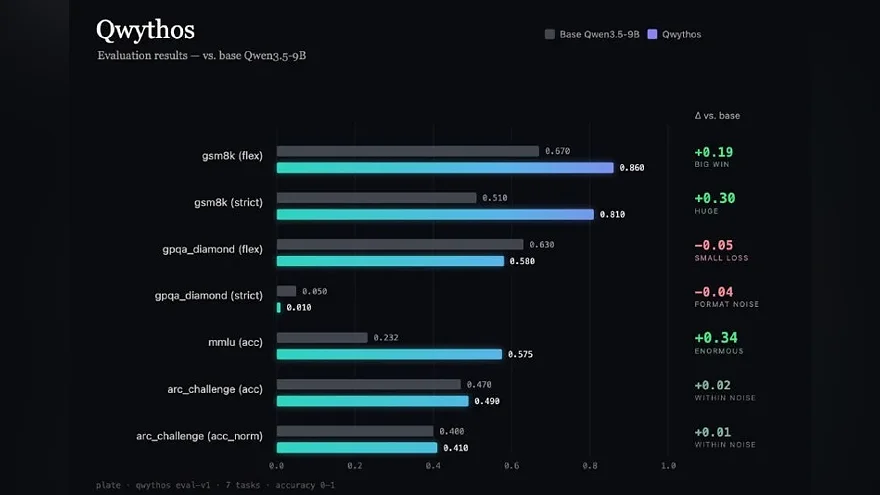
Benchmarks against the base Qwen3.5-9B: +34.3 points MMLU, +30 gsm8k-strict, +19 gsm8k-flex. However, on gpqa_diamond the model showed −5 points compared to the base — which is important not to be silent.
Working with a full 1M context requires a distributed infrastructure: one H100/H200 confidently holds 256k–512k tokens, but a million requires tensor-parallel multi-GPU or aggressive KV-cache offload.
The main contradiction is the data of Claude Mythos
Empero openly states that the model is «post-trained on Claude Mythos and Claude Fable traces.» There is a fundamental problem here.
Claude Mythos is a closed frontier model from Anthropic that has not been made public. Anthropic has not published either the model or the datasets based on it. This means that Empero most likely obtained the «traces» in one of two ways: either through mass generation of synthetic data via the API (i.e., effectively distilling the closed model), or through some unauthorized access.
The first option is a direct violation of Anthropic’s Terms of Service, which prohibit using model responses to train competing systems. This is why OpenAI filed a lawsuit against the companies involved in distilling GPT-4. Empero has not yet commented on how it obtained this data.
«Intentionally uncensored» — for whom and why
Empero positions the lack of restrictions as a key advantage for researchers and developers working in cybersecurity, biomedicine, and pharmacology — that is, in areas where «over-aligned» models often fail or issue meaningless disclaimers instead of a real answer.
This is a real problem: excessive censorship in AI models does limit their usefulness for legitimate tasks—penetrators, medical researchers, toxicologists. But a complete lack of any restrictions is another pole with its own risks, especially if the model is available for download by anyone without verification.
Where available
Qwythos-9B is already available on HuggingFace under a fully open license with no restrictions on commercial use. Harness for reproducing tool use tests Empero promises to publish on GitHub.