
Meta представила нове покоління мультимодальних відкритих моделей штучного інтелекту — Llama 4, яке об'єднує в собі здатність розуміти зображення, відео та текст в одній архітектурі. Ці моделі є першими нативно мультимодальними з відкритими вагами, що дає змогу розробникам і підприємствам працювати з ними для вирішення широкого спектра завдань.
Ключові характеристики Llama 4
-
Llama 4 Scout
-
Модель з 17 мільярдами активних параметрів і 16 експертами (всього 109 мільярдів параметрів).
-
Найкраща мультимодальна модель у своєму класі, перевершує такі моделі як Gemini 3, Gemini 2.0 Flash-Lite та Mistral 3.1.
-
Основна особливість — рекордне контекстне вікно в 10 мільйонів токенів та можливість працювати на одній GPU H100 з квантизацією Int4.
-
-
Llama 4 Maverick
-
Потужна модель з 17 мільярдами активних параметрів та 128 експертами (400 мільярдів параметрів загалом).
-
За заявою Meta, ця модель перевершує GPT-4o та Gemini 2.0 Flash в численних бенчмарках. Вона також демонструє результати, співмірні з DeepSeek v3 у завданнях міркування та кодування, але з удвічі меншою кількістю параметрів.
-
Експериментальна версія для чату досягла ELO 1417 на LMArena.
-
-
Llama 4 Behemoth
-
Учительська модель з 288 мільярдами активних параметрів та 16 експертами (майже 2 трильйони параметрів загалом).
-
Перевершує GPT-4.5, Claude Sonnet 3.7 та Gemini 2.0 Pro за кількома STEM-бенчмарками.
-
Ця модель наразі в процесі навчання і ще не була випущена публічно.
-

Технічні інновації
Архітектура Mixture of Experts (MoE)
Однією з новинок Llama 4 є архітектура Mixture of Experts (MoE), де для обробки кожного токену активується лише частина параметрів моделі. Це дозволяє знижувати обчислювальні витрати та латентність, зберігаючи високу якість роботи. У Llama 4 Maverick кожен токен обробляється загальним експертом та одним зі 128 маршрутизованих експертів.
Нативна мультимодальність
Моделі Llama 4 інтегрують текстові та візуальні токени в єдину модельну архітектуру через метод early fusion, що дозволяє проводити спільне попереднє навчання на великих обсягах текстових, зображувальних та відеоданих. Вдосконалений візуальний енкодер на основі MetaCLIP забезпечує кращу адаптацію до мовних моделей.
Екстремально довгий контекст
Модель Llama 4 Scout підтримує неймовірно довгий контекст у 10 мільйонів токенів завдяки архітектурі iRoPE (interleaved attention layers). Це дає змогу моделі ефективно працювати з великими текстовими масивами.
Нові методики навчання
-
MetaP: техніка, яка забезпечує надійне налаштування критичних гіперпараметрів моделі, таких як швидкість навчання для кожного шару.
-
FP8-precision: використання 8-бітної точності з плаваючою комою, що дає змогу навчати моделі з високою продуктивністю без втрати якості.
-
Кодистиляція: використання Llama 4 Behemoth як вчителя для навчання менших моделей.
-
Повністю асинхронне онлайн-навчання з підкріпленням: нова інфраструктура для масштабного навчання, яка підвищує ефективність на 10 разів.
Результати бенчмарків
1. Llama 4 Behemoth

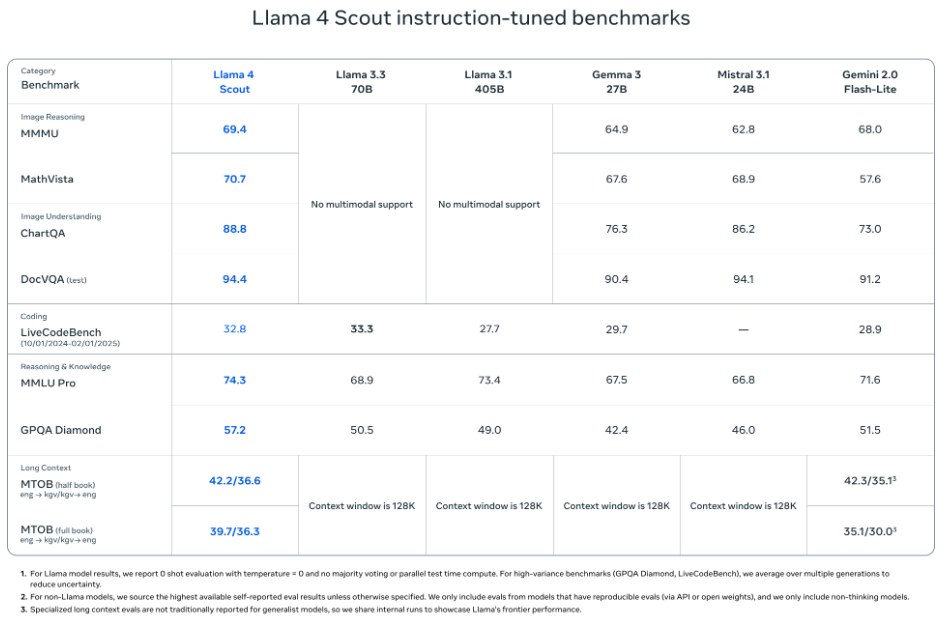
2. Llama 4 Scout
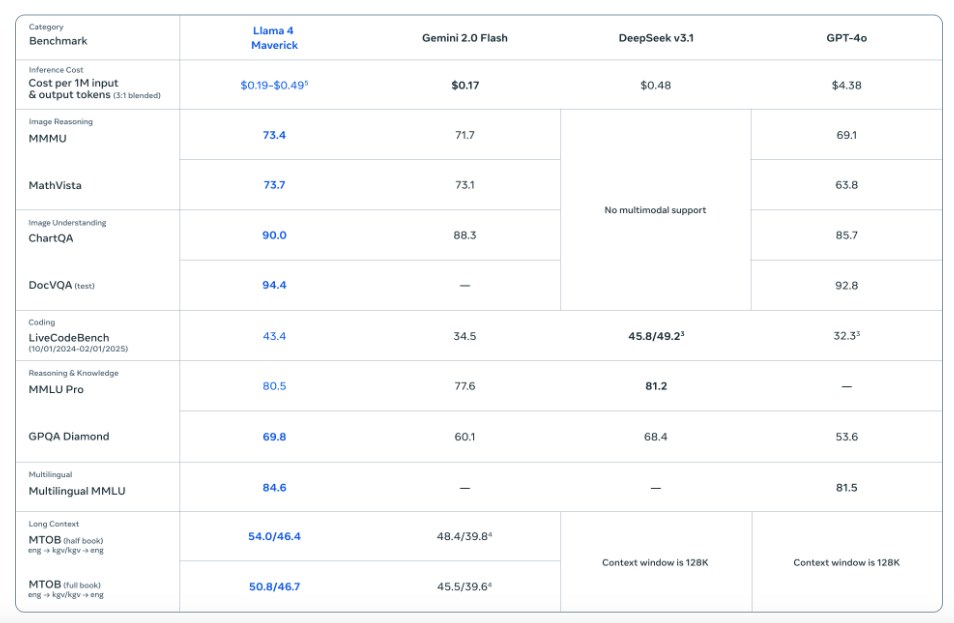
3. Llama 4 Maverick
-
Вартість: $0,19–0.49 за 1 мільйон токенів (залежно від налаштувань), в порівнянні з $4,38 за 1 мільйон токенів у GPT-4o.
-
Обробка зображень:
-
MMMU: 73.4 (проти 71.7 у Gemini 2.0 Flash та 69.1 у GPT-4o).
-
MathVista: 73.7 (проти 73.1 у Gemini та 63.8 у GPT-4o).
-
ChartQA: 90.0 (проти 88.3 у Gemini та 85.7 у GPT-4o).
-
DocVQA: 94.4 (проти 92.8 у GPT-4o).
-
-
Кодинг:
-
LiveCodeBench: 43.4 (лідер — DeepSeek v3.1 з 45.8/49.2).
-
-
Розуміння та знання:
-
MMLU Pro: 80.5 (проти 77.6 у Gemini, DeepSeek лідирує з 81.2).
-
GPQA Diamond: 69.8 (проти 60.1 у Gemini, 68.4 у DeepSeek і 53.6 у GPT-4o).
-
-
Багатомовність:
-
Multilingual MMLU: 84.6 (проти 81.5 у GPT-4o).
-
-
Довгий контекст:
-
MTOB (повна книга): 50.8/46.7 (проти 45.5/39.6 у Gemini).
-
Behemoth проти конкурентів
Модель Llama 4 Behemoth перевершує флагмани інших компаній за багатьма параметрами:
-
LiveCodeBench: 49.4 (проти 36.0 у Gemini 2.0 Pro).
-
MATH-500: 95.0 (проти 82.2 у Claude Sonnet 3.7 та 91.8 у Gemini 2.0 Pro).
-
MMLU Pro: 82.2 (проти 79.1 у Gemini 2.0 Pro).
-
GPQA Diamond: 73.7 (проти 71.4 у GPT-4.5, 68.0 у Claude та 64.7 у Gemini).
Доступність і застосування
Моделі Llama 4 Scout та Llama 4 Maverick вже доступні для завантаження на llama.com і Hugging Face. Вони також інтегровані в Meta AI для використання в WhatsApp, Messenger, Instagram Direct і на вебсайті Meta.AI. Для розробників, підприємств та дослідників ці моделі пропонують чудовий баланс між високою продуктивністю та доступністю.
Безпека та етика
Meta приділила значну увагу безпеці та зменшенню упередженості в нових моделях. Було розроблено низку інструментів для безпеки, таких як Llama Guard, Prompt Guard та CyberSecEval. Крім того, рівень відмов від відповідей на запитання про спірні політичні та соціальні теми значно знижено (з 7% в Llama 3.3 до менш ніж 2%).





