UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
16 вересня 2025, 13:23
2025-09-16
Google представила VaultGemma — свою першу LLM, що зберігає конфіденційність даних
Компаніям, які прагнуть створювати масштабніші моделі ШІ, все більше бракує високоякісних даних для навчання. Оскільки вони активно сканують мережу в пошуках нової інформації для своїх моделей, вони можуть все частіше використовувати потенційно конфіденційні дані користувачів. Команда Google Research вивчає нові методи, щоб знизити ймовірність того, що великі мовні моделі (LLM) «запам’ятають» цей контент.
Компаніям, які прагнуть створювати масштабніші моделі ШІ, все більше бракує високоякісних даних для навчання. Оскільки вони активно сканують мережу в пошуках нової інформації для своїх моделей, вони можуть все частіше використовувати потенційно конфіденційні дані користувачів. Команда Google Research вивчає нові методи, щоб знизити ймовірність того, що великі мовні моделі (LLM) «запам’ятають» цей контент.
Вихідні дані LLM-моделей непередбачувані, тому ви ніколи не знаєте, що саме вони згенерують. Хоча відповіді можуть бути різними, моделі іноді повторюють інформацію, яку використали під час навчання. Якщо серед цих даних була особиста інформація, це може порушити приватність користувачів. Коли в навчальні дані потрапляє інформація, захищена авторським правом, її поява у відповідях може створювати проблеми для розробників. Диференційна конфіденційність дозволяє уникнути цього, додаючи «шум» у процесі навчання, пише Ars Technica.
Додавання диференційної конфіденційності до моделі має свої недоліки: це впливає на точність та обчислювальні потреби. Дотепер ніхто не намагався з’ясувати, якою мірою це змінює закони масштабування моделей ШІ. Команда Google Research виходила з припущення, що продуктивність моделі буде залежати від співвідношення між кількістю доданого шуму та обсягом вихідних даних для навчання.
Проводячи експерименти з різними розмірами моделей і співвідношенням «шуму» до обсягу даних, команда встановила основні закони масштабування диференційної конфіденційності, які залежать від трьох факторів: обчислювальних потужностей, рівня конфіденційності та кількості даних. Коротко кажучи, чим більше шуму, тим гірша якість результатів, якщо не використовувати більше обчислювальних ресурсів або даних. У статті описані ці закони, що допоможе розробникам знайти оптимальний баланс для підвищення конфіденційності моделей.
Ця робота над диференційною конфіденційністю призвела до створення нової відкритої моделі від Google під назвою VaultGemma. Модель використовує диференційну конфіденційність, щоб зменшити ймовірність «запам’ятовування», що може змінити підхід компанії до забезпечення приватності у своїх майбутніх ШІ-агентах. Проте поки що ця модель є експериментальною.
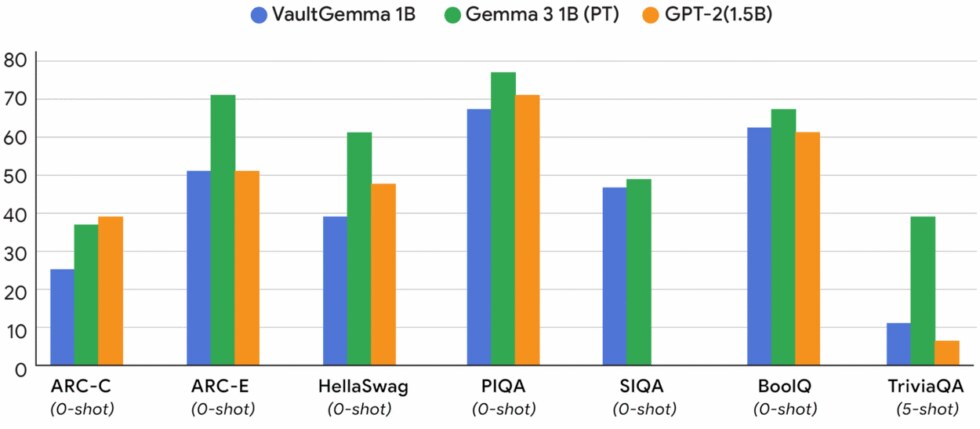
VaultGemma базується на базовій моделі Gemma 2, яка на одне покоління відстає від найновішої відкритої моделі Google. Команда Google використала результати своїх тестів, щоб навчити VaultGemma з найкращим показником диференційної конфіденційності. Модель не дуже велика, вона має лише 1 млрд параметрів. Однак, як стверджують у Google Research, за продуктивністю VaultGemma не поступається моделям такого ж розміру, які не мають функції конфіденційності.
Команда сподівається, що їхні дослідження допоможуть іншим компаніям ефективно використовувати ресурси для створення приватних моделей ШІ. Це навряд чи вплине на найбільші моделі, оскільки для них найважливіша — продуктивність. Проте, згідно з результатами, диференційна конфіденційність є більш ефективною для менших LLM, які використовуються для конкретних функцій.
VaultGemma можна завантажити з Hugging Face та Kaggle. Модель має відкриті ваги, але не є open source. Google дозволяє змінювати й поширювати моделі Gemma, але за умови, що ви не використовуватимете їх для незаконних цілей і завжди додаватимете копію ліцензії Gemma до своїх модифікованих версій.













 поради")