UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоAI Eng
11 April 2025, 09:51
2025-04-11
AI models still can't handle code debugging, Microsoft study shows
Most developers spend a significant portion of their time debugging code, not writing it. It would be great to have an AI tool that could suggest fixes for hundreds of bugs, and all you have to do is approve them. However, a new study from Microsoft Research shows that leading AI models are not yet up to the task.
Most developers spend a significant portion of their time debugging code, not writing it. It would be great to have an AI tool that could suggest fixes for hundreds of bugs, and all you have to do is approve them. However, a new study from Microsoft Research shows that leading AI models are not yet up to the task.
Modern AI coding tools are great at improving productivity and suggesting solutions to bugs based on existing code and error messages. However, unlike human developers, these tools don’t seek out additional information when a solution doesn’t work, leaving some bugs unfixed.
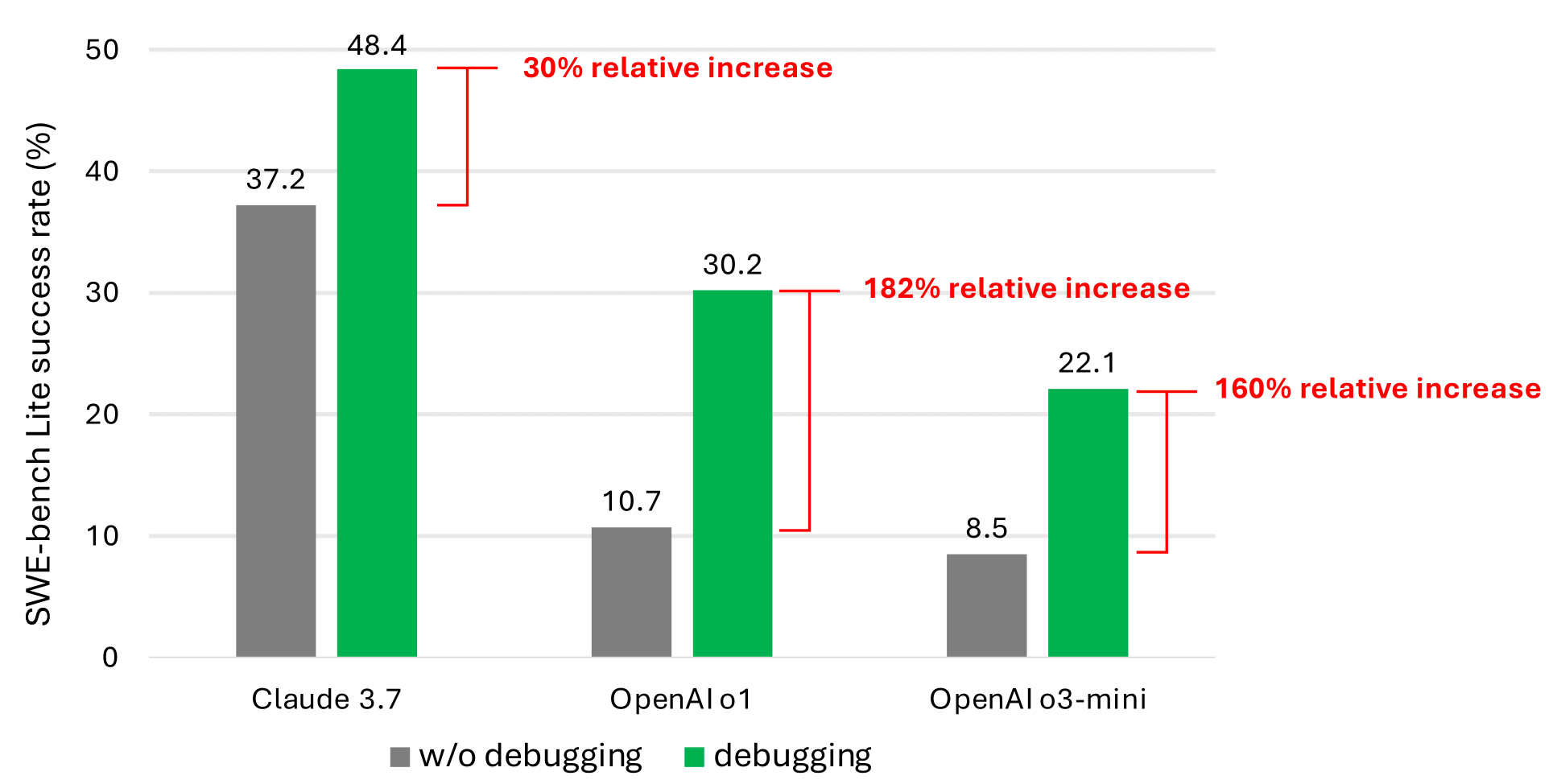
Microsoft Research's study shows that models including Anthropic's Claude 3.7 Sonnet and OpenAI's o3-mini fail to debug many problems in a software development benchmark called SWE-bench Lite.
The study’s co-authors tested nine different models as the basis for an agent that had access to a number of debugging tools, including a Python debugger. They tasked the agent with solving a set of 300 software debugging tasks from SWE-bench Lite, TechCrunch reports .
According to the co-authors, even when using more powerful and modern models, their agent rarely succeeded in more than half of the debugging tasks. Claude 3.7 Sonnet had the highest average success rate (48.4%), followed by OpenAI's o1 (30.2%) and o3-mini (22.1%).
Why such low performance?
Some models had difficulty using the various debugging tools available to them and understanding how they could help solve various problems.
But the bigger problem, the co-authors say, was a lack of data. They suggest that the current training data for the models lacks enough of what represents “sequential decision processes”—that is, traces of human tuning.
“We strongly believe that training or fine-tuning [models] can make them better interactive debuggers,” the co-authors wrote in their study. “However, this will require specific data to perform such model training, such as trajectory data that captures the agents’ interactions with the debugger to gather the necessary information before suggesting bug fixes.”
Як нейромережі бачать вільну та незалежну Україну? Тест dev.ua
Нейронні мережі для генерації зображень бачать світ по-своєму, їхню логіку зрозуміти часом зовсім неможливо. Але таки хочеться. На честь Дня Незалежності України редакція dev.ua вирішила провести невеликий експеримент.
Ми задали чотирьом різним нейронним мережам п’ять однакових запитів: «прапор України», «День Незалежності України», «український Крим», «перемога України» та «українці». Отриманими результатами ми ділимося з вами нижче.
У TikTok тепер можна генерувати фон за допомогою нейромережі. Ми протестували її та ділимося результатами
У TikTok з’явилася нова функція «Розумний фон». З її допомогою як фон для тіктоків можна підставляти згенеровані нейромережею зображення. Редакція dev.ua протестувала цю технологію і ділиться своїми враженнями.