Open Ukrainian language model Lapa LLM has received a public release
A team of Ukrainian researchers presented Lapa LLM v0.1.2 — a large language model based on Gemma-3-12B, optimized for working with the Ukrainian language.

A team of Ukrainian researchers presented Lapa LLM v0.1.2 — a large language model based on Gemma-3-12B, optimized for working with the Ukrainian language.

A team of Ukrainian researchers presented Lapa LLM v0.1.2 — a large language model based on Gemma-3-12B, optimized for working with the Ukrainian language.
Thanks to the new tokenizer, Lapa LLM replaced 80,000 tokens out of 250,000 with Ukrainian ones, while maintaining the quality of the original model. This allowed for a one and a half times reduction in the number of calculations for working with Ukrainian texts compared to the original Gemma 3. Lapa developers claim that Lapa LLM is the fastest Ukrainian NLP model.
Version 0.1.2 showed results close to the market leader MamayLM in the tasks of understanding instructions, translation, summarizing and Q&A. In translation from English to Ukrainian, it achieved 33 BLEU on the FLORES benchmark, becoming the best open translator between these languages.
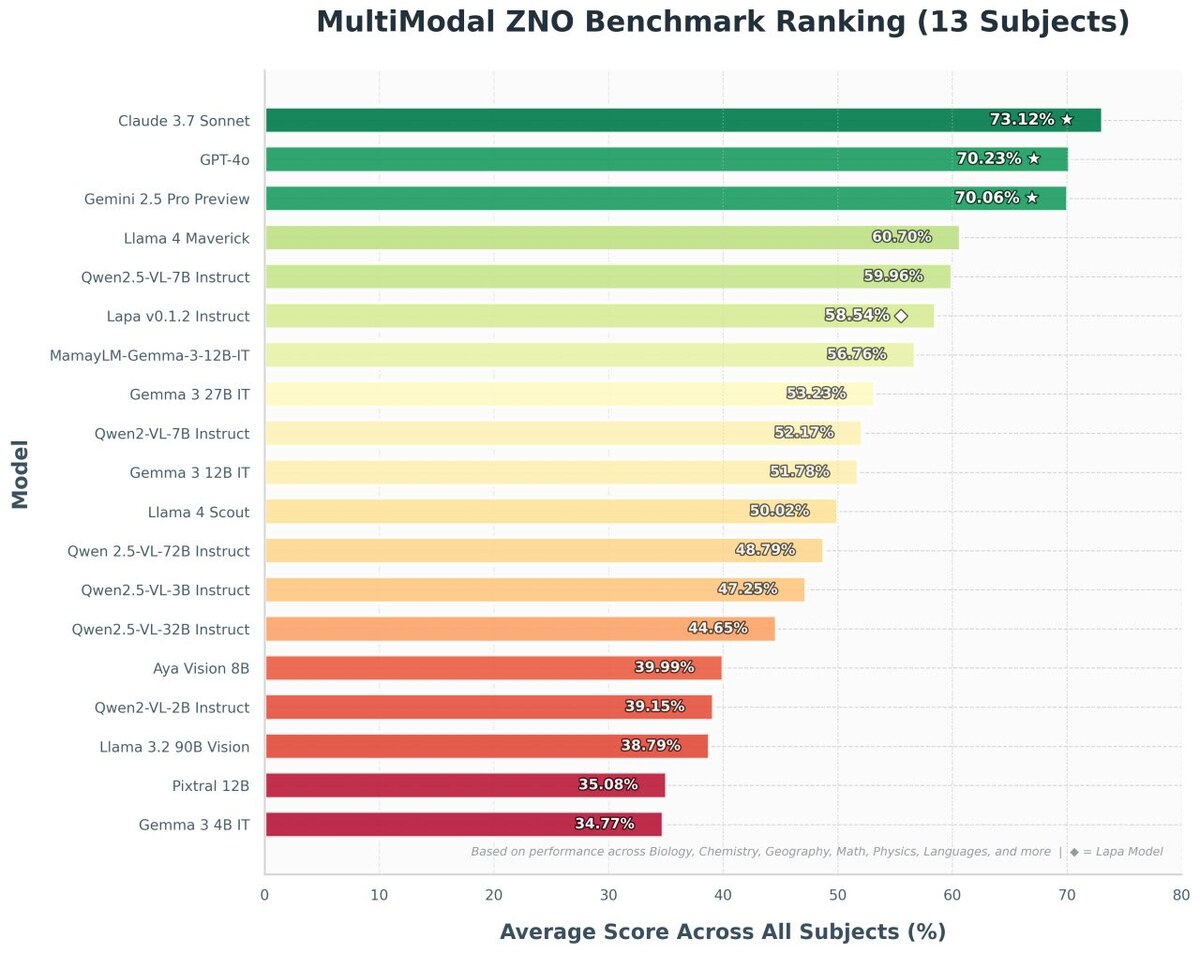
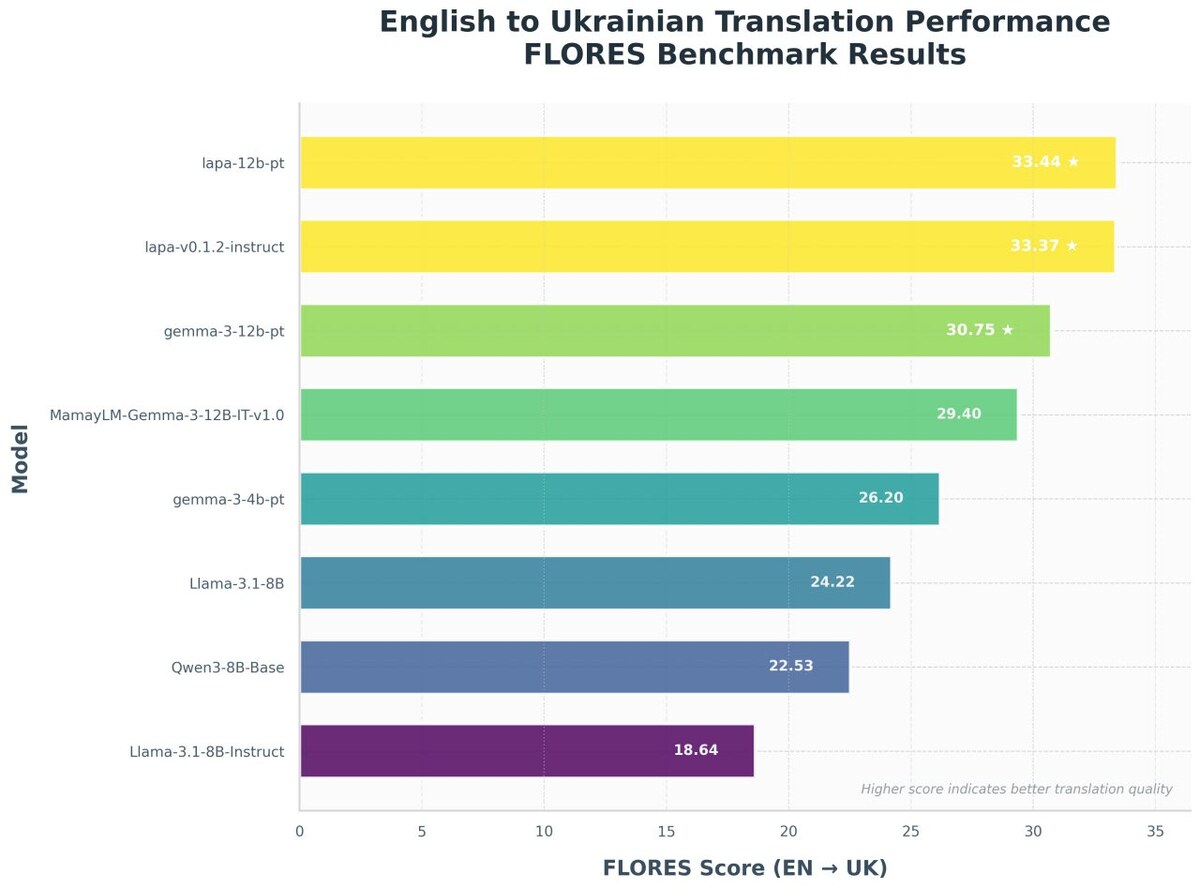
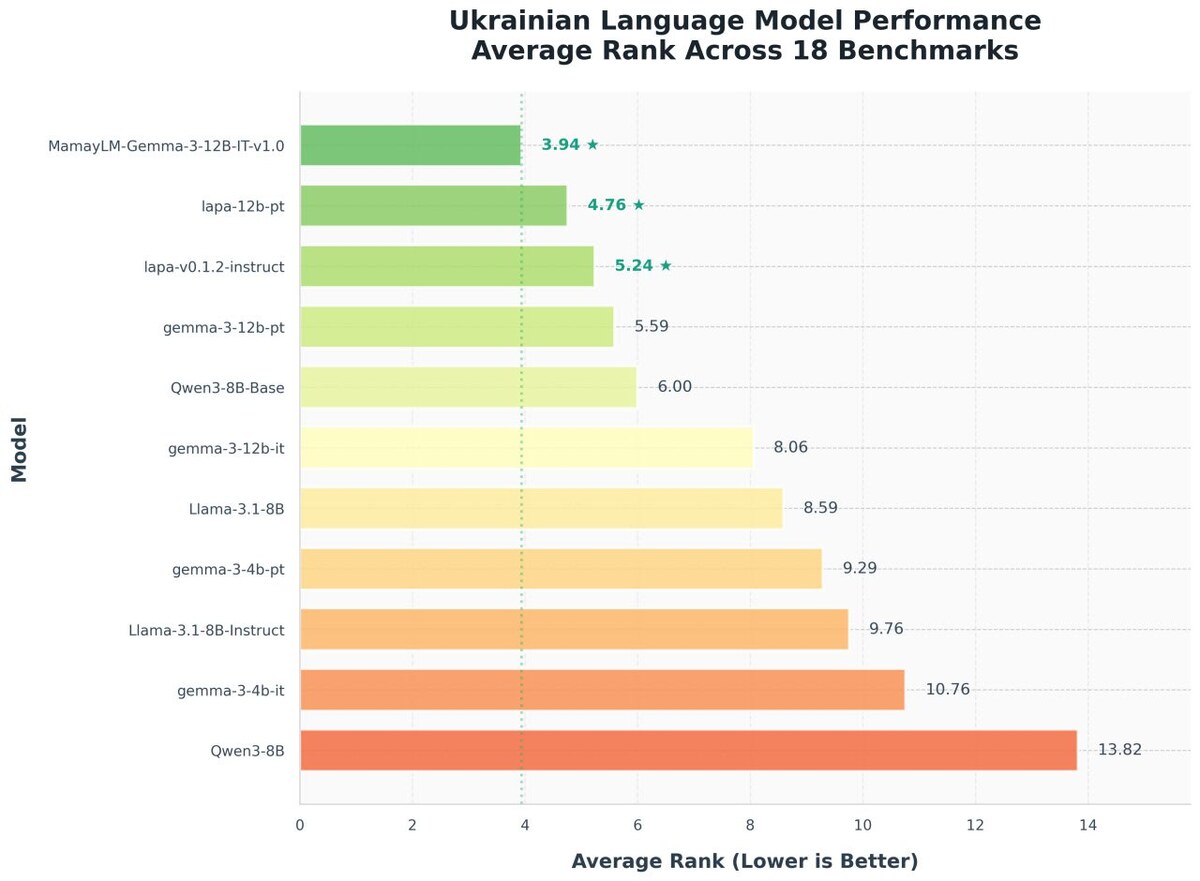
In addition to text tasks, Lapa LLM demonstrates strong results in image processing in Ukrainian, and also successfully passes tests for identifying propaganda and disinformation thanks to special filtering methods.
Lapa LLM is fully open for commercial use. The team has published:
over 25 datasets for training,
model source code,
data filtering and quality assessment techniques,
documentation of the learning process.
The model was trained on verified sources, including materials from the Harvard Library, and its quality was confirmed by evaluations of other AI models.
In the future, the development team plans to complete the development of the reasoning model and add new text and graphic datasets.
You can try the model at the Hugging Face link, and the code is available on GitHub .