Українська відповідь ChatGPT. Як «Київстар» із Мінцифри будуватимуть національну LLM для України: інсайти й міжнародний ШІ-досвід VEON
Наміри Мінцифри створити власний штучний інтелект, який розумітиме українців краще за ChatGPT, на початку викликали тільки подив та усмішки, але від слів до реальних дій пройшло лише кілька місяців і схоже цей потяг не зупинити. Чи дійсно Україні потрібна власна велика мовна модель? Яку користь із цього отримають громадяни? Чому розробку віддали приватній компанії? На всі ці питання dev.ua відповідає в новому великому мовному матеріалі.
Наміри Мінцифри створити власний штучний інтелект, який розумітиме українців краще за ChatGPT, на початку викликали тільки подив та усмішки, але від слів до реальних дій пройшло лише кілька місяців і схоже цей потяг не зупинити. Чи дійсно Україні потрібна власна велика мовна модель? Яку користь із цього отримають громадяни? Чому розробку віддали приватній компанії? На всі ці питання dev.ua відповідає в новому великому мовному матеріалі.
Мінцифри має амбітні плани до 2030 року потрапити в трійку світових лідерів за ступенем готовності впровадження штучного інтелекту, наразі ми посідаємо 63-тє місце. Мова йде не тільки про престиж, але й про ефективність державного апарату, інформаційну безпеку, розвитку освіти та науки.
Велика мовна модель — це основа для чатботів, ШІ-асистентів, які будуть використовуватися в державних послугах.
Михайло Федоров лаконічно окреслив ціль створення продуктів на основі національної мовної моделі: «Інтегруємо їх у „Дію“, „Мрію“ та армію». Тобто ШІ має стати повноцінним помічником для держави та громадян і стати такою ж буденною і незамінною річчю як «Дія».
Попри важливість та амбітність прагнень Мінцифри рішення створити власну велику мовну модель викликало багато занепокоєнь щодо бюджету й масштабності проєкту. Мінцифри одразу повідомило, що з нуля створювати LLM ніхто не планує, а будуть брати готове рішення, яке потім вдосконалюватиметься під потреби держави. Саме для цього було створено AI Center Excellence, який курує розробку національної LLM. Так, саме курує, оскільки керівництво держави вирішило не витрачати й без того обмежені кошти, а залучити приватну компанію в особі телеком-оператора «Київстар».
Чому обрали саме «Київстар» і скільки коштуватиме розробка?
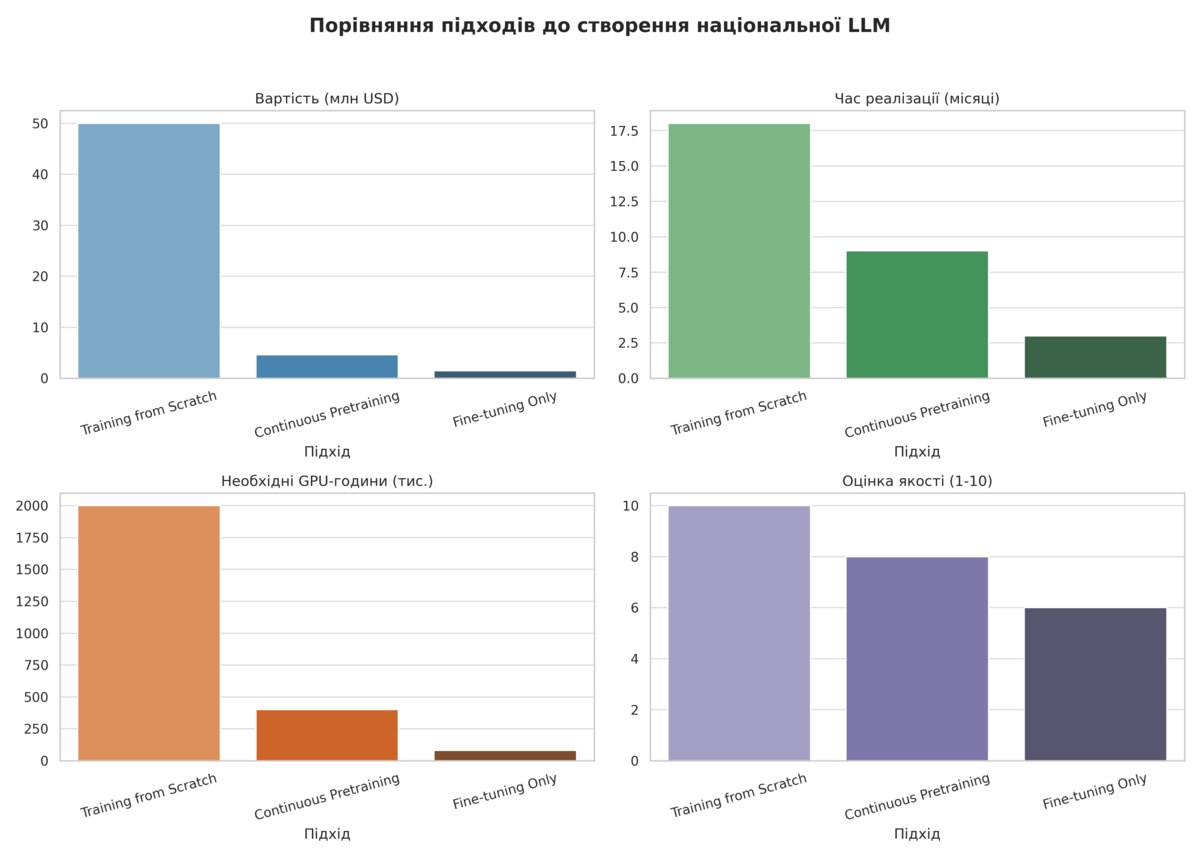
Мінцифри запевняє, що «Київстар» володіє необхідними ресурсами, як фінансовими, так і технічними для втілення проєкту національної LLM. Дійсно, розробка моделі вимагає чималих фінансових вливань, наприклад Болгарія витратила $100 млн на розробку першої в Європі національної LLM. Оскільки Мінцифри обрало метод continuous pretraining із подальшим fine-tuning (використання наявних open-source моделей та їхнього навчання на корпусах української мови) кошторис моделі значно знижується. «Київстар» готова вкласти $1,5–2 млн початкових інвестицій. Для компанії, яка нещодавно відзвітувала про загальний операційний дохід на рівні $255 млн такі витрати майже непомітні. За необхідності «Київстар» готова додатково інвестувати, але в яких обсягах і чиє гранична стеля невідомо, проте на наш запит компанія запевнила, що повністю покриє фінансову частину розробки.
«Цей проєкт є класичною R&D ініціативою, по суті розробкою чогось, чого ще ніхто в такому вигляді не створював. Це можна порівняти з науковим експериментом. Як у будь-яких R&D проєктах, можуть виникнути складнощі, що вимагатимуть додаткових ресурсів, або ж навпаки — ідеї, що пришвидшать і здешевлять роботу. Водночас „Київстар“ взяв на себе зобов’язання повністю покрити фінансову частину розробки LLM», — прокоментували в «Київстар» питання про фінансування проєкту LLM.
Якщо орієнтуватися на оцінку, яку дав CTO AI Center Excellence Дмитро Овчаренко загальний кошторис може скласти від $1,5 до $8 млн. Це дуже оптимістичні суми, якщо порівнювати з болгарським бюджетом, чи навіть бразильським, на мовну модель якої виділено $200 млн.
Михайло Федоров та Олександр Комаров підписують документ про стратегічне партнерство
Важливо зауважити, що материнська компанія «Київстар» VEON вже втілювала проєкти зі створення великої мовної моделі Казахстану KazLLM спільно з Barcelona Computing Center та іншими приватними компаніями. Тому вибір Мінцифри орієнтувався не тільки на привабливий фінансовий складник, а й на експертність VEON у цій сфері.
«„Київстар» має прямий доступ до міжнародної експертизи через материнську компанію VEON, яка вже володіє успішним досвідом реалізації національних AI-проєктів. Ми використовуємо експертизу групи для того, щоб уникати характерних складнощів — як технічних, так і організаційних. Це дозволяє «Київстар» виступити надійним технологічним партнером на етапі пілотного запуску, забезпечивши швидкий старт процесу та якісний фундамент для створення LLM, максимально адаптованої до лінгвістичних рис та культури України».
Як зазначалося раніше, не тільки Україна пішла методом залучень приватних підрядників у створенні власної LLM. Загалом великі корпорації такі як Mistral у Франції, Fujitsu в Японії чи Samsung у Республіці Корея не цураються інвестувати в державні LLM ініціативи. У Таїланді та Греції залучали всіх в кого були гроші, навіть міжнародні, а не локальні компанії. Так, є випадки, коли держава намагається створити велику мовну модель власними силами, як от в Нідерландах, де до створення моделі, планується залучити три неприбуткові організації, пов’язані з урядом. Однак це виняток, що підтверджує правило, оскільки одна з найбагатших країн Саудівська Аравія теж звернулася до приватних організацій.
«Це є нормальною практикою під час розробки національної мовної моделі, тому що дійсно витрачати великі державні кошти на такий проєкт було б не зовсім доцільно, особливо враховуючи потреби Сил оборони в умовах повномасштабної війни», — дав свою оцінку партнерству Мінцифри та «Київстар» ШІ-експерт Олексій Мінаков для dev.ua.
Для навчання великої мовної моделі потрібні три основні апаратні компоненти: високопродуктивні графічні процесори, достатній обсяг пам’яті та масштабоване сховище даних. Основною вимогою є обчислювальна потужність, яка забезпечується сучасними графічними процесорами, призначеними для паралельної обробки. Графічні процесори NVIDIA A100 або H100 є поширеним вибором завдяки тензорним ядрам і високій пропускній здатності пам’яті, які прискорюють матричні операції, критичні для навчання нейронних мереж.
За словами Овчаренка зараз локально тестуються тензорні відеокарти Nvidia на чипах H100 і менш потужні GPU. На запит dev.ua «Київстар» підтвердила використання чипів А100 або Н100 для першої фази навчання LLM, а для фінальної моделі будуть використовуватися Н100 або Н200 від Nvidia, однак поки що невідомо звідки братимуться ці потужності.
«За попередніми оцінками, перевіреними з кількома командами, що мають досвід подібних проєктів, на піку буде використовуватися щонайменше 8 DGX, це 64 потужних GPU, кожен DGX по суті є готовим суперкомпʼютером, створеним спеціально для складних завдань, таких як навчання LLM. Ми маємо різні варіанти залучення подібних потужностей. Фінальну конфігурацію ми оголосимо, коли буде прийняте відповідне рішення», — повідомила «Київстар».
На чому базуватиметься національна LLM?
Наразі є безліч open-source моделей готових до використання як основу для кастомної національної великої мовної моделі. У Мінцифри поки що не назвали, яка саме модель буде використана, швидше за все вибір впаде на Google Gemma-2, як це зробила Болгарія у своїй моделі BgGPT, оскільки вона чудово впоралася з болгарською мовою, що використовує кирилицю.
У цьому аспекті ключову роль відіграє токенізатор, який розбиває текст на менші частини, які називаються токенами.
Токени — це слова, частини слів або їх окремі символи, що робить дані зрозумілими для моделі. Важливо мати ефективний токенізатор, щоб могти вдало представити слова у зрозумілому для моделі виді, та не витрачати зайві кошти, оскільки, у що меншу кількість токенів модель перетворює текст, тим менше обчислень їй необхідно зробити, відповідно тим дешевша вартість її роботи.
Токенізатори популярних LLM на кшталт ChatGPT, Llama, Claude, Gemini й інших насамперед розроблені для роботи з англійською мовою, тому коли користувач робить запити українською, вартість цього запиту набагато вища.
Наступним важливим етапом буде обсяг даних (корпусів), на яких тренуватимуть модель.
«Технічні виклики починаються від збору якісного датасету і продовжуються визначенням конкретних цілей, які має виконувати національна LLM. Навіть найкращий датасет не дасть необхідного результату, якщо він не адаптований під специфічні завдання моделі», — розповів dev.ua засновник першого web3 університету Михайло Пацан.
Найбільшим ресурсом вважається «Корпус української мови», що містить понад 100 млн слововживань. Chief AI Officer Мінцифри Данило Цьвок, визнав, що цього недостатньо навіть для моделі середнього розміру. Для прикладу Llama навчена на 1,4 трлн токенів. Дмитро Овчаренко звертає увагу на корпус «Малюк» обсягом 113 ГБ, який містить 17 млрд токенів, який активно використовується для створення токенізаторів для української мови.
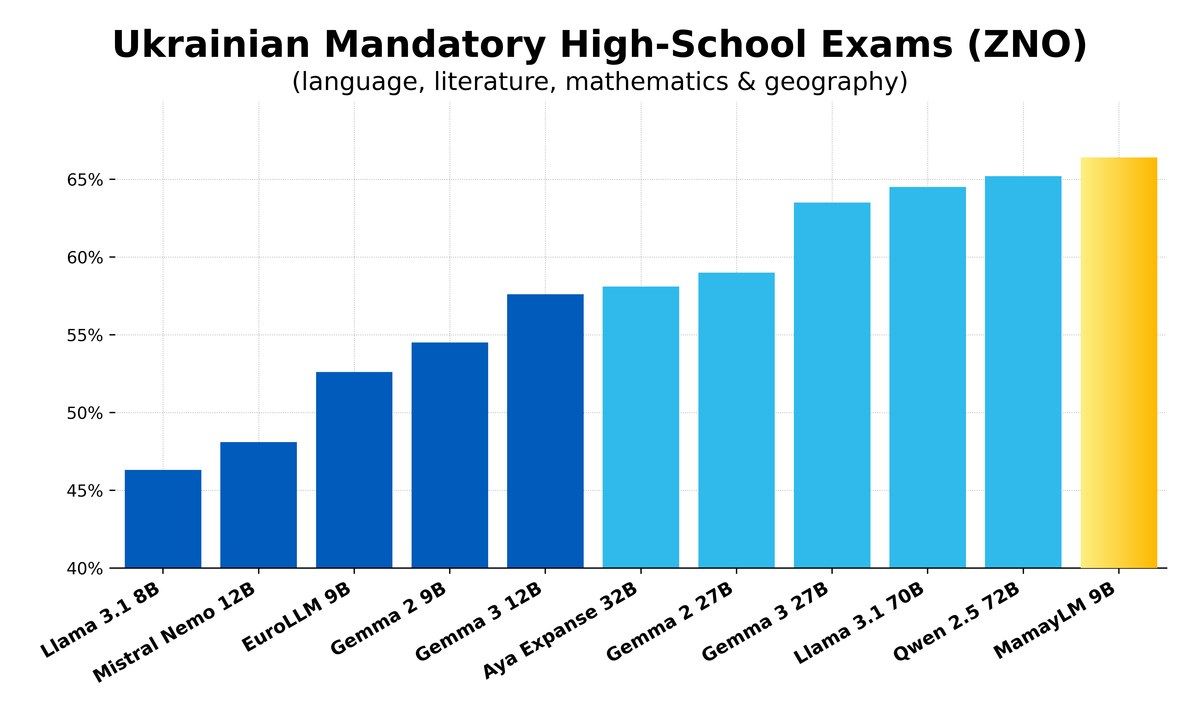
Цікавим є факт, що у світі вже створена перша українська мовна модель, але це сталося не в Україні та не українцями. Компанія розробник BgGPT INSAIT створила модель MamayML, яка розроблялася спеціально під українську мову. Водночас модель тренована на значно меншому корпусі, серед яких є вищезазначений «Малюк». MamayML показала найкращі результати у бенчмарку зі складання ЗНО серед моделей аналогічного розміру, при цьому випереджаючи набагато більші моделі, включно з Gemma2 27B, Llama 3.1 70B і Qwen 2.5 72B.
Для Мінцифри й «Київстар» як мінімум встановили планку якості, яку треба перевершити
Де використовуватимуть національну LLM?
За всіма гучними заявами й намірами Мінцифри щодо важливості національної великої мовної моделі для державної безпеки, історичної пам’яті та руху у світле цифрове майбутнє України варто справді розуміти, що з цього матимуть українські громадяни.
У березні цього року прем’єр-міністр Денис Шмигаль повідомив, що за три роки уряд скоротив 30% чиновників зокрема завдяки цифровізації послуг. Мінцифри зі свого боку наголошує, що українська LLM автоматизує безліч процесів у спілкуванні громадянина з державою. Для прикладу візьмемо «Дію», до якої щомісяця надходить близько 100 000 запитів від громадян, що створює велике навантаження для команди підтримки. Власна LLM дозволить віддати ці операції ШІ агентам розроблених на основі національної LLM і відповідно скоротить штат працівників, які займалися цим функціоналом. Чатбот «Наталка» вже консультує партнерів, що інтегрують «Дію», і за три місяці роботи віртуальна помічниця опрацювала понад 1500 запитів, що зменшило навантаження на менеджерів на 30%. Так, ШІ й тут забирає роботу.
Звісно, частину працівників переведуть на інші задачі, а нових фахівців із LLM й ШІ треба буде найняти, причому їхній рейт значно вищий, ніж у фахівців із технічної підтримки «Дії». Однак, за словами Дмитра Овчаренка, це не тільки зменшить бюджетні витрати, але й підніме ефективність команди в цілому. Тобто ми йдемо до сценарію, де рішення на основі LLM витіснятиме надлишковий штат чиновників, спрощуватиме комунікацію між громадянином і державою, і економитиме бюджетні кошти.
Оскільки національна LLM буде open-source — це дасть змогу використовувати її безплатно, але не для всіх. Некомерційні установи й бізнес матимуть змогу заплатити за доступ до моделі, однак на яких умовах поки що не ясно. У меморандумі між Мінцифри й «Київстар» наголошується, що вартість буде значно дешевшою за інші аналоги банально через кращу токенізацію запитів українською мовою. Комерціалізація проєкту для бізнесу дасть додаткові кошти в бюджет, які, для прикладу, можна витрати на підсилення обороноздатності країни.
«Після тестового періоду модель буде передана державі й буде доступна open source. Водночас „Київстар“ планує надалі будувати комерційні рішення з використанням моделі, що будуть доступні як через АРІ, так і з можливістю розгортання на власній інфраструктурі наших клієнтів. Так, інші бізнеси зможуть отримати доступ в тому числі до Kyivstar Cloud та створених на її основі продуктів від „Київстар“ через API, з хостингом в Kyivstar Cloud», — розповіли про подальше використання національної LLM українськими бізнесами після запуску.
На безпеці теж варто зупинитися, тому що це хвилює зараз кожного українця. Загалом, коли розробляють якесь окреме рішення за запитом будь-якої держави — це в першу питання не фінансової вигоди, а національної безпеки. Уряди всіх країн витрачають космічні суми на контракти з приватними підрядниками. З останнього США уклали угоду з OpenAI на $200 млн для впровадження ChatGPT в державні структури, зокрема для військових цілей. ScaleAI, яку нещодавно придбала Meta за рекордні $14,3 млрд, взагалі натренував мовну модель на основі Llama, яка здатна відповідати на запитання, що пов’язані з обороною.
Цифровий суверенітет. Як боротьба за контроль над даними перетворилася в повноцінний вимір геополітичного протистояння
Що стосується інформаційної безпеки, головна перевага власної LLM моделі — вона повністю тренована на українському контексті. Цю важливість підтверджують усі без винятку ШІ експерти. І хоча в мережі жартують, що модель вітатиметься гаслом «Слава Україні», навіть у Мінцифри зазначають, що на запитання «Чий Крим?» національна LLM має дати чітку проукраїнську відповідь. Наразі інші популярні мовні моделі використовують безліч датасетів зокрема російських для генерування відповідей для кириличної мовної групи. Максим Корженевський в інтерв’ю dev.ua пояснив, які ризики несе ця проблема.
Варто наголосити, що розробка національної мовної моделі стане складовою частиною цифрового суверенітету країни. Що більше даних залишатиметься та оброблятиметься всередині країни тим більш захищеною вона буде. «Це питання цифрового суверенітету, зокрема, суверенітету в штучному інтелекті. І щоб не залежати від забаганок і упереджень розробників американських та інших ШІ-моделей. Плюс питання безпеки даних — щоб дані оброблялися всередині країни, а не десь на закордонних серверах», — зауважив ШІ експерт Олексій Мінаков.
Що далі?
9 місяців — саме такий термін озвучили Мінцифри й «Київстар» для створення першої версії національної LLM. За цей час модель у режимі бета-тесту тренуватимуть як технічні, так і лінгвістичні фахівці для закладання основи. Після тестування українську LLM почнуть поступово інтегрувати в державні послуги, зокрема «Дію» і дадуть доступ до API бізнесам. За ефективної взаємодії держави та приватного сектору українська LLM може стати важливим інструментом для розвитку ШІ-сервісів, покращення державних послуг та зміцнення технологічної незалежності країни. Але чи вистачить українцям сил створити справді якісний продукт, а не чергову «галюцинаційну» модель, покаже лише час.
«Ми зробили те, про що самі не мріяли у 2022». Як штучний інтелект змінює державу й армію зсередини — інтерв’ю з творцем ШІ-рішення Avengers, що автоматично ідентифікує військову техніку
Зайшов лише для того щоб залишити коментар про те, що треба руки відбивати за подібні заголовки. Що потрібно зробити, щоб нарешті припинили писати оце "наш атвєт" чи "український/ке щось"?!
Скільки ще буде продовжуватися цей тренд на меншовартість?! Просто хочеться ригати, коли читаєш такий заголовок.
















Зайшов лише для того щоб залишити коментар про те, що треба руки відбивати за подібні заголовки. Що потрібно зробити, щоб нарешті припинили писати оце "наш атвєт" чи "український/ке щось"?!
Скільки ще буде продовжуватися цей тренд на меншовартість?! Просто хочеться ригати, коли читаєш такий заголовок.
Veon? Це той, що був Вимпілкомом Фрідмана? Це точно про україномовну модель? А не крадіжку інформації?