UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Олег ОнопрієнкоAI Eng
3 July 2025, 09:00
2025-07-03
Ukrainian answer ChatGPT. How Kyivstar and the Ministry of Digital Economy will build a national LLM for Ukraine: insights and international AI experience VEON
The Ministry of Digital Affairs’s intentions to create its own artificial intelligence that would understand Ukrainians better than ChatGPT initially caused only surprise and smiles, but only a few months have passed from words to real actions and it seems that this desire cannot be stopped. Does Ukraine really need its own large-scale language model? What benefits will citizens receive from this? Why was the development given to a private company? dev.ua answers all these questions in a new large-scale language material.
The Ministry of Digital Affairs’s intentions to create its own artificial intelligence that would understand Ukrainians better than ChatGPT initially caused only surprise and smiles, but only a few months have passed from words to real actions and it seems that this desire cannot be stopped. Does Ukraine really need its own large-scale language model? What benefits will citizens receive from this? Why was the development given to a private company? dev.ua answers all these questions in a new large-scale language material.
The Ministry of Digital Affairs has ambitious plans to become one of the top three global leaders in terms of readiness for the implementation of artificial intelligence by 2030; we currently rank 63rd. This is not only about prestige, but also about the efficiency of the state apparatus, information security, and the development of education and science.
The large language model is the basis for chatbots, AI assistants that will be used in government services.
Mykhailo Fedorov succinctly outlined the goal of creating products based on the national language model: «We integrate them into Diya, Mriya, and the army.» That is, AI should become a full-fledged assistant for the state and citizens and become as everyday and indispensable a thing as «Diya.»
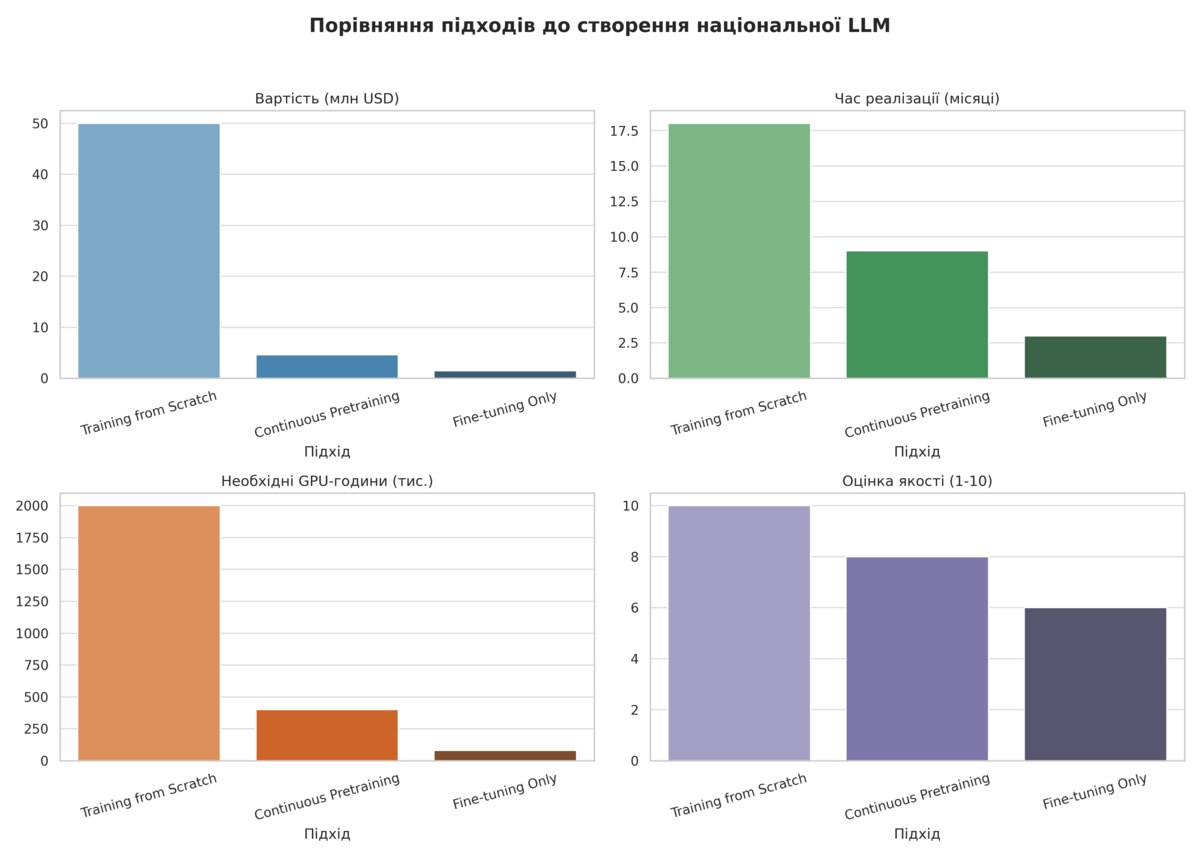
Despite the importance and ambition of the Ministry of Digital Affairs’s aspirations, the decision to create its own large-scale language model has raised many concerns regarding the budget and scale of the project. The Ministry of Digital Affairs immediately announced that no one plans to create an LLM from scratch, but will take a ready-made solution, which will then be improved to meet the needs of the state. It is for this purpose that the AI Center Excellence was created, which oversees the development of the national LLM. Yes, it oversees it, since the state leadership decided not to spend the already limited funds, but to involve a private company in the person of the telecom operator Kyivstar.
Why was Kyivstar chosen and how much will the development cost?
The Ministry of Digital Affairs assures that Kyivstar has the necessary resources, both financial and technical, to implement the national LLM project. Indeed, the development of the model requires considerable financial investments, for example, Bulgaria spent $100 million on the development of the first national LLM in Europe. Since the Ministry of Digital Affairs chose the continuous pretraining method with subsequent fine-tuning (using existing open-source models and training them on Ukrainian language corpora), the model’s cost estimate is significantly reduced. Kyivstar is ready to invest $1.5-2 million in initial investments. For a company that recently reported total operating income of $255 million, such costs are almost imperceptible. If necessary, Kyivstar is ready to invest additionally, but in what volumes and whose maximum ceiling is unknown, however, upon our request, the company assured that it will fully cover the financial part of the development.
«This project is a classic R&D initiative, essentially the development of something that no one has ever created in this form. It can be compared to a scientific experiment. As in any R&D projects, difficulties may arise that will require additional resources, or vice versa — ideas that will speed up and make the work cheaper. At the same time, Kyivstar has undertaken to fully cover the financial part of the LLM development,» Kyivstar commented on the issue of financing the LLM project.
Based on the estimate given by the CTO of AI Center Excellence, Dmytro Ovcharenko, the total budget could range from $1.5 to $8 million. These are very optimistic amounts when compared to the Bulgarian budget, or even the Brazilian one, which allocated $200 million for its language model.
Mykhailo Fedorov and Oleksandr Komarov sign a document on strategic partnership
It is important to note that Kyivstar’s parent company VEON has already implemented projects to create a large language model of Kazakhstan KazLLM together with the Barcelona Computing Center and other private companies. Therefore, the Ministry of Digital Affairs' choice was based not only on the attractive financial component, but also on VEON’s expertise in this area.
«Kyivstar has direct access to international expertise through its parent company VEON, which already has successful experience in implementing national AI projects. We use the group’s expertise to avoid typical difficulties — both technical and organizational. This allows Kyivstar to act as a reliable technological partner at the pilot launch stage, ensuring a quick start to the process and a high-quality foundation for creating an LLM that is maximally adapted to the linguistic features and culture of Ukraine.»
As noted earlier, it is not only Ukraine that has resorted to the method of involving private contractors in creating its own LLM. In general, large corporations such as Mistral in France, Fujitsu in Japan, or Samsung in the Republic of Korea do not shy away from investing in state LLM initiatives. In Thailand and Greece, everyone who had money was involved, even international, not local, companies. Yes, there are cases when the state tries to create a large language model on its own, such as in the Netherlands, where it is planned to involve three non-profit organizations associated with the government in creating the model. However, this is an exception that proves the rule, since one of the richest countries, Saudi Arabia, has also turned to private organizations.
«This is normal practice when developing a national language model, because it would not be entirely appropriate to spend large amounts of public funds on such a project, especially considering the needs of the Defense Forces in a full-scale war,» AI expert Oleksiy Minakov gave his assessment of the partnership between the Ministry of Digital Affairs and Kyivstar for dev.ua.
Training a large language model requires three main hardware components: high-performance GPUs, sufficient memory, and scalable data storage. The primary requirement is the computational power provided by modern GPUs designed for parallel processing. NVIDIA A100 or H100 GPUs are a common choice due to their tensor cores and high memory bandwidth, which accelerate matrix operations critical for training neural networks.
According to Ovcharenko, Nvidia’s tensor graphics cards based on H100 chips and less powerful GPUs are currently being tested locally. In response to a request from dev.ua, Kyivstar confirmed the use of A100 or H100 chips for the first phase of LLM training, and the final model will use Nvidia’s H100 or H200, but it is not yet known where this power will come from.
«According to preliminary estimates, verified with several teams with experience in similar projects, at least 8 DGX will be used at the peak, which is 64 powerful GPUs, each DGX is essentially a ready-made supercomputer created specifically for complex tasks, such as LLM training. We have various options for attracting such capacities. We will announce the final configuration when the appropriate decision is made,» Kyivstar reported.
What will the national LLM be based on?
There are currently many open-source models ready to be used as the basis for a custom national large language model. The Ministry of Digital Affairs has not yet announced which model will be used, most likely the choice will fall on Google Gemma-2, as Bulgaria did with its BgGPT model, as it coped excellently with the Bulgarian language, which uses the Cyrillic alphabet.
In this aspect, a key role is played by a tokenizer, which breaks the text into smaller parts called tokens.
Tokens are words, parts of words, or individual characters that make data understandable to the model. It is important to have an efficient tokenizer to be able to successfully represent words in a form that is understandable to the model, and not to waste unnecessary money, because the fewer tokens the model converts text into, the fewer calculations it needs to perform, and accordingly, the cheaper the cost of its work.
Tokenizers of popular LLMs such as ChatGPT, Llama, Claude, Gemini, and others are primarily designed to work with the English language, so when a user makes requests in Ukrainian, the cost of this request is much higher.
The next important step will be the amount of data (corpora) on which the model will be trained.
«Technical challenges begin with collecting a high-quality dataset and continue with defining specific goals that the national LLM should fulfill. Even the best dataset will not produce the necessary results if it is not adapted to the specific tasks of the model,» Mykhailo Patsan, founder of the first web3 university, told dev.ua.
The largest resource is considered to be the «Ukrainian Language Corpus», which contains over 100 million word usages. Chief AI Officer of the Ministry of Digital Affairs Danylo Tsvok admitted that this is not enough even for a medium-sized model. For example, Llama was trained on 1.4 trillion tokens. Dmytro Ovcharenko draws attention to the «Malyuk» corpus with a volume of 113 GB, which contains 17 billion tokens, which is actively used to create tokenizers for the Ukrainian language.
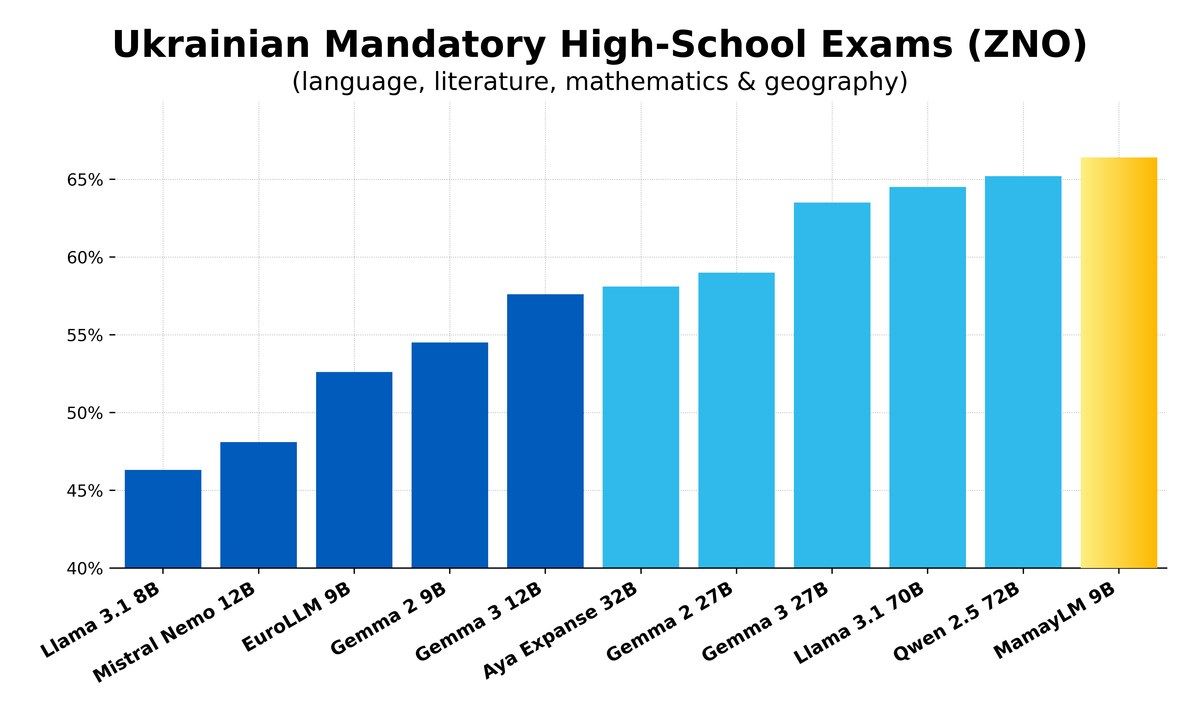
It is interesting that the first Ukrainian language model has already been created in the world, but it did not happen in Ukraine and not by Ukrainians. The developer company BgGPT INSAIT created the MamayML model, which was developed specifically for the Ukrainian language. Moreover, the model was trained on a much smaller corpus, among which is the aforementioned «Malyuk». MamayML showed the best results in the ZNO benchmark among models of similar size, while outperforming much larger models, including Gemma2 27B, Llama 3.1 70B and Qwen 2.5 72B.
For the Ministry of Digital Economy and Kyivstar, at least they have set a quality bar that must be exceeded.
Where will the national LLM be used?
For all the loud statements and intentions of the Ministry of Digital Affairs about the importance of a national large language model for state security, historical memory, and movement into a bright digital future of Ukraine, it is worth really understanding what Ukrainian citizens will gain from this.
In March of this year, Prime Minister Denys Shmyhal announced that over the past three years, the government has reduced the number of officials by 30%, in particular due to the digitalization of services. The Ministry of Digital Affairs, for its part, emphasizes that the Ukrainian LLM automates many processes in the communication of citizens with the state. For example, let’s take «Diya», which receives about 100,000 requests from citizens every month, which creates a large workload for the support team. Its own LLM will allow these operations to be assigned to AI agents developed on the basis of the national LLM and, accordingly, will reduce the number of employees who were engaged in this functionality. The chatbot «Natalka» is already advising partners integrating «Diya», and in three months of operation, the virtual assistant has processed more than 1,500 requests, which has reduced the workload on managers by 30%. Yes, AI is taking away work here too.
Of course, some employees will be transferred to other tasks, and new LLM and AI specialists will have to be hired, and their rate is significantly higher than that of Diya’s technical support specialists. However, according to Dmytro Ovcharenko, this will not only reduce budget costs, but also increase the efficiency of the team as a whole. That is, we are moving towards a scenario where a solution based on LLM will replace the redundant staff of officials, simplify communication between citizens and the state, and save budget funds.
Since the national LLM will be open-source, this will allow it to be used for free, but not for everyone. Non-profit institutions and businesses will be able to pay for access to the model, but on what terms it is not yet clear. The memorandum between the Ministry of Digital and Kyivstar emphasizes that the cost will be significantly cheaper than other analogues, simply due to better tokenization of requests in the Ukrainian language. Commercialization of the project for business will provide additional funds to the budget, which, for example, can be spent on strengthening the country’s defense capabilities.
«After the test period, the model will be transferred to the state and will be available as open source. At the same time, Kyivstar plans to continue building commercial solutions using the model, which will be available both via API and with the ability to deploy on our clients' own infrastructure. Thus, other businesses will be able to access Kyivstar Cloud and Kyivstar products created on its basis via API, with hosting in Kyivstar Cloud,» they said about the further use of the national LLM by Ukrainian businesses after the launch.
It is also worth stopping at security, because it worries every Ukrainian now. In general, when developing a separate solution at the request of any state, it is primarily a matter of national security, not financial gain. Governments of all countries spend huge sums on contracts with private contractors. Most recently, the US signed a $200 million deal with OpenAI to implement ChatGPT in government structures, including for military purposes. ScaleAI, which was recently acquired by Meta for a record $14.3 billion, has even trained a language model based on Llama that can answer questions related to defense.
Digital sovereignty: How the struggle for data control has become a full-fledged geopolitical confrontation
As for information security, the main advantage of our own LLM model is that it is fully trained in the Ukrainian context. This importance is confirmed by all AI experts without exception. And although the network jokes that the model will be greeted with the slogan «Glory to Ukraine», even the Ministry of Digital Affairs notes that the national LLM should give a clear pro-Ukrainian answer to the question «Whose Crimea?». Currently, other popular language models use many data sets, including Russian, to generate answers for the Cyrillic language group. Maksym Korzhenevskyi explained in an interview with dev.ua what risks this problem poses.
It is worth emphasizing that the development of a national language model will become an integral part of the country’s digital sovereignty. The more data remains and is processed within the country, the more protected it will be. «This is a question of digital sovereignty, in particular, sovereignty in artificial intelligence. And so as not to depend on the whims and prejudices of the developers of American and other AI models. Plus the issue of data security — so that the data is processed within the country, and not somewhere on foreign servers,» noted AI expert Oleksiy Minakov.
What’s next?
9 months — this is the term announced by the Ministry of Digital and Kyivstar for the creation of the first version of the national LLM. During this time, the model, in beta test mode, will be trained by both technical and linguistic specialists to lay the foundation. After testing, the Ukrainian LLM will begin to be gradually integrated into state services, in particular «Diya» and will provide access to the API to businesses. With effective interaction between the state and the private sector, the Ukrainian LLM can become an important tool for the development of AI services, improving state services and strengthening the country’s technological independence. But only time will tell whether it will be enough for Ukrainians to create a really cool product, and not another «hallucinatory» model.
«We did something we never dreamed of in 2022.» How artificial intelligence is changing the state and the army from within — an interview with the creator of the Avengers AI solution that automatically identifies military equipment
Kyivstar will create a Ukrainian national large-scale language model. Why did the Ministry of Digital Affairs delegate this to a private company and how much money is needed for this
Зайшов лише для того щоб залишити коментар про те, що треба руки відбивати за подібні заголовки. Що потрібно зробити, щоб нарешті припинили писати оце "наш атвєт" чи "український/ке щось"?!
Скільки ще буде продовжуватися цей тренд на меншовартість?! Просто хочеться ригати, коли читаєш такий заголовок.
















Зайшов лише для того щоб залишити коментар про те, що треба руки відбивати за подібні заголовки. Що потрібно зробити, щоб нарешті припинили писати оце "наш атвєт" чи "український/ке щось"?!
Скільки ще буде продовжуватися цей тренд на меншовартість?! Просто хочеться ригати, коли читаєш такий заголовок.
Veon? Це той, що був Вимпілкомом Фрідмана? Це точно про україномовну модель? А не крадіжку інформації?