UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
19 квітня 2024, 10:12
2024-04-19
Meta представила Llama 3. Звісно, компанія стверджує, що це одна з найкращих доступних відкритих моделей на сьогодні
Компанія Meta випустила останню новинку в серії Llama — відкритих генеративних моделей штучного інтелекту: Llama 3. Точніше, компанія представила дві моделі з нового сімейства Llama 3, а решта з’являться в майбутньому, але поки що невідомо коли.
Компанія Meta випустила останню новинку в серії Llama — відкритих генеративних моделей штучного інтелекту: Llama 3. Точніше, компанія представила дві моделі з нового сімейства Llama 3, а решта з’являться в майбутньому, але поки що невідомо коли.
Мета описує нові моделі — Llama 3 8B, яка містить 8 млрд параметрів, і Llama 3 70B, яка містить 70 млрд параметрів — як «великий стрибок» за продуктивністю у порівнянні з моделями Llama попереднього покоління — Llama 2 8B і Llama 2 70B, пише TechCrunch.
Параметри, по суті, визначають вміння моделі ШІ вирішувати завдання, наприклад, аналізувати та генерувати текст; моделі з більшою кількістю параметрів, загалом кажучи, більш здібні, ніж моделі з меншою кількістю параметрів. Тобто Мета фактично стверджує, що Llama 3 8B і Llama 3 70B, які навчені на двох спеціально створених кластерах із 24 000 GPU, є одними з найефективніших генеративних моделей штучного інтелекту, доступних сьогодні.
Як же Meta підтверджує свою сміливу заяву, що Llama 3 є однією з найкращих доступних відкритих моделей?
Компанія вказує на результати моделей Llama 3 за такими популярними тестами ШІ, як MMLU для вимірювання знання, ARC — вимірює набуття навичок і DROP — тестує роботу моделі над фрагментами тексту. Ці тести ШІ залишаються одним з небагатьох стандартизованих способів, за допомогою яких гравці в галузі ШІ оцінюють свої моделі.
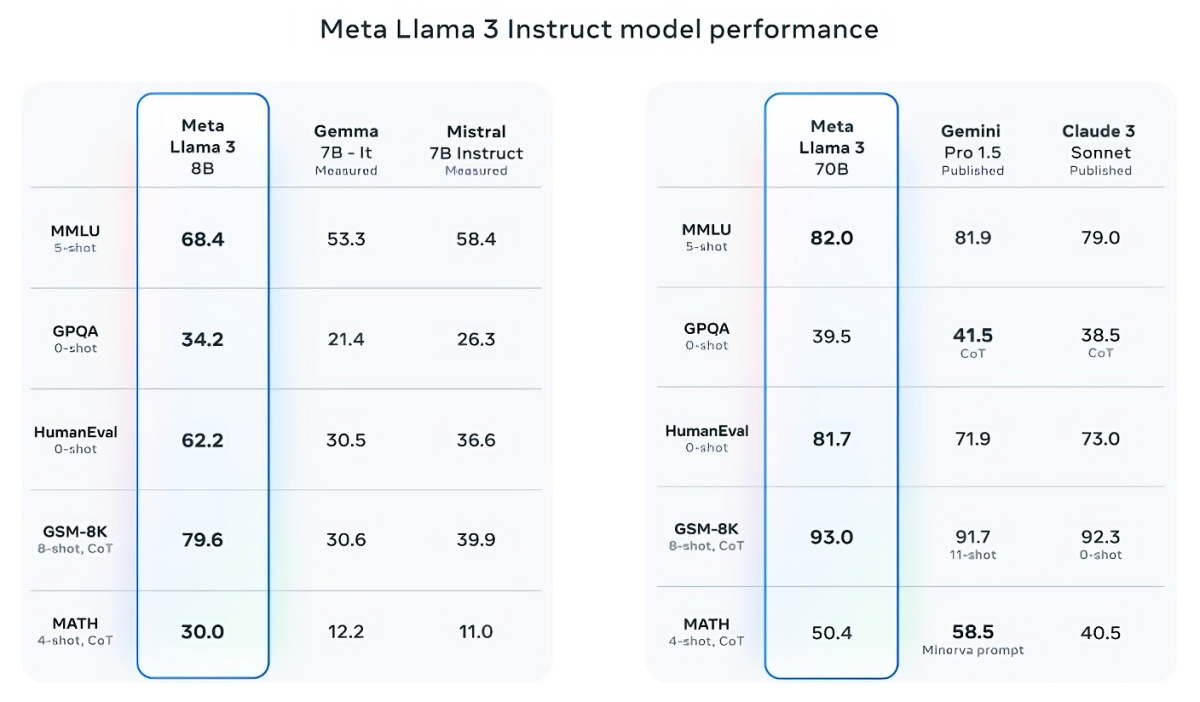
Llama 3 8B перевершує інші відкриті моделі, такі як Mistral 7B від Mistral і Gemma 7B від Google, обидві з яких містять 7 млрд параметрів, принаймні за дев’ятьма тестами: MMLU, ARC, DROP, GPQA (набір питань з біології, фізики та хімії), HumanEval (тест на створення коду), GSM-8K (математичні текстові задачі), MATH (інший математичний тест), AGIEval (набір тестів для розв’язування задач) і BIG-Bench Hard (оцінка здорового глузду).
Тепер Mistral 7B і Gemma 7B не зовсім на передовій (Mistral 7B був випущений у вересні минулого року), і в кількох тестах, наведених Meta, Llama 3 8B випереджає їх лише на кілька відсоткових пунктів. Але Meta також стверджує, що Llama 3 70B може конкурувати з Gemini 1.5 Pro — останньою моделлю в серії Gemini від Google.
Фото: TechCrunch
Llama 3 70B перемагає Gemini 1.5 Pro в тестах MMLU, HumanEval і GSM-8K, і — хоча вона не конкурує з найпродуктивнішою моделлю Anthropic, Claude 3 Opus — Llama 3 70B показує кращі результати, ніж інша найслабша модель серії Claude 3, Claude 3 Sonnet, у п’яти тестах (MMLU, GPQA, HumanEval, GSM-8K і MATH).
Фото: TechCrunch
Meta також розробила власний набір тестів, що охоплює різні варіанти використання: від кодування та написання текстів до міркувань та підбиття підсумків. За цими тестами Llama 3 70B перемогла модель Mistral Medium від Mistral, GPT-3.5 від OpenAI та Claude Sonnet. Компанія Meta стверджує, що вона закрила доступ до набору для своїх команд моделювання, щоб зберегти об'єктивність, але, очевидно, враховуючи, що Meta сама розробила тест, результати слід сприймати з певною часткою скептицизму.
Фото: TechCrunch
Мета каже, що користувачі нових моделей Llama можуть очікувати більшої «керованості», меншої ймовірності відмови відповідати на запитання і більшої точності у дрібницях, питаннях, що стосуються історії та STEM-галузей, таких як інженерія і наука, а також загальних рекомендацій щодо кодування. Частково це стало можливим завдяки набагато більшому набору даних: колекції з 15 трильйонів токенів, або близько 750 000 000 000 000 слів — у сім разів більшому за навчальну базу Llama 2. (У сфері ШІ «токенами» називають розділені біти необроблених даних, як-от склади «фан», «тас» і «тич» у слові «фантастичний»).
Meta не відповіла звідки взялися ці дані, лише зазначила, що вони були взяті з «загальнодоступних джерел», містили в чотири рази більше коду, ніж у навчальному наборі даних Llama 2, і що 5% цього набору містять неанглійські дані (приблизно 30 мовами) для поліпшення продуктивності на мовах, відмінних від англійської. Мета також заявила, що використовує синтетичні дані, тобто дані, згенеровані штучним інтелектом, для створення довших документів, на яких навчаються моделі Llama 3, що є дещо суперечливим підходом через потенційні недоліки в продуктивності.
«Хоча моделі, які ми випускаємо сьогодні, налаштовані тільки для вихідних даних англійською мовою, збільшене розмаїття даних допомагає моделям краще розпізнавати нюанси та закономірності та ефективно виконувати різноманітні завдання», — пише компанія.
Щодо токсичності та упередженості Мета заявляє, що розробила нові конвеєри фільтрації даних для підвищення якості навчальних даних своїх моделей, а також оновила пару пакетів безпеки для генеративного ШІ, Llama Guard і CybersecEval, щоб запобігти неправомірному використанню та небажаній генерації текстів моделями Llama 3 та іншими.
Моделі Llama 3 вже доступні для завантаження та забезпечують роботу помічника Meta AI у Facebook, Instagram, WhatsApp, Messenger. Незабаром будуть розміщені в керованій формі на багатьох хмарних платформах, включно з AWS, Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX від IBM, Microsoft Azure, NIM від Nvidia та Snowflake. У майбутньому також будуть доступні версії моделей, оптимізовані для обладнання від AMD, AWS, Dell, Intel, Nvidia та Qualcomm.
Моделі Llama 3 можуть бути широко доступними як для дослідницьких, так і для комерційних застосувань. Однак Meta забороняє розробникам використовувати моделі Llama для навчання інших генеративних моделей, а розробники додатків з більш ніж 700 млн користувачів щомісяця повинні запитувати спеціальну ліцензію від Meta, яку компанія надасть — або не надасть — на свій розсуд.
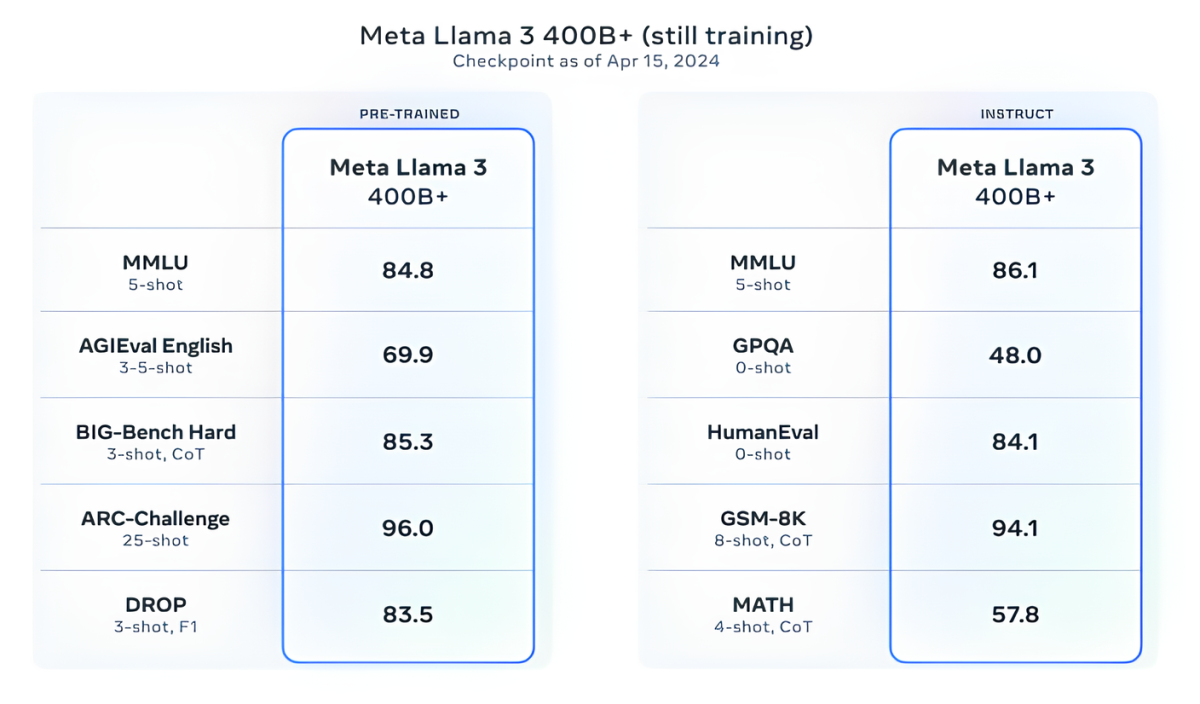
Meta заявляє, що наразі вона навчає моделі Llama 3 розміром понад 400 млрд параметрів — моделі, здатні «розмовляти кількома мовами», приймати більше даних і розуміти зображення та інші модальності, а також текст, що приведе серію Llama 3 у відповідність до відкритих релізів, таких як Hugging Face’s Idefics2.
«Чи є у мене талант, якщо комп’ютер може імітувати мене?». Штучний інтелект пише книги авторам Amazon Kindle. The Verge поспілкувався з авторами та виявив багато цікавого
Письменники-романісти використовують штучний інтелект для створення своїх творів. Видання про технології The Verge поспілкувалося з письменницею Дженніфер Лепп, яка випускає нову книгу кожні дев’ять тижнів, й дізналося про те, як працює штучний інтелект для написання романів. Наводимо адаптований переклад статті.
Хочете повідомити важливу новину? Пишіть у Telegram-бот
Головні події та корисні посилання в нашому Telegram-каналі