UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
15 квітня 2025, 17:13
2025-04-15
Надмірне навчання LLM може призвести до зниження її продуктивності, показало нове дослідження
Протягом останніх кількох років вважалося, чим більше тренується ШІ-модель, тим краще будуть її результати. Але група дослідників із кількох університетів США може тепер із цим посперечатись.
Протягом останніх кількох років вважалося, чим більше тренується ШІ-модель, тим краще будуть її результати. Але група дослідників із кількох університетів США може тепер із цим посперечатись.
Дослідники штучного інтелекту Університету Карнегі-Меллона, Стенфордського, Гарвардського та Принстонського університетів виявили, що надмірне навчання великих мовних моделей може негативно впливати на їхню продуктивність.
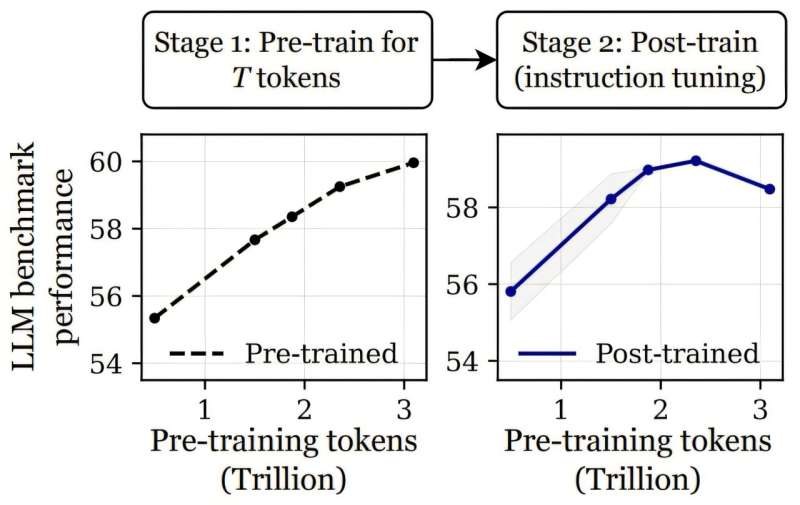
Вони прийшли до такого висновку, коли перевіряли віддачу ШІ під час навчання двох різних версій LLM OLMo-1B: одну модель навчали, використовуючи 2,3 трлн токенів, іншу — 3 трлн токенів. Потім протестували їх за допомогою кількох тестів, таких як ARC і AlpacaEval. Вони виявили, що результат другої ШІ-моделі був гіршим на 3% за першу, пише Tech Xplore.
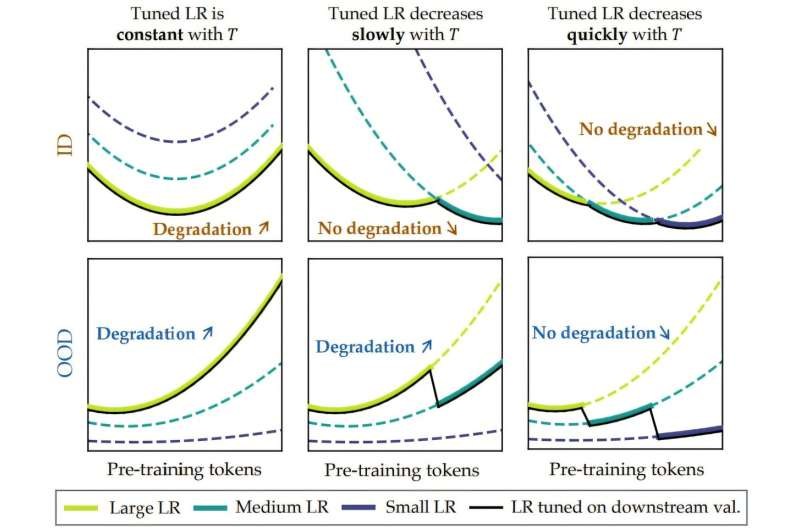
Здивовані своїми висновками, дослідники провели більше тестів і отримали подібні результати, що свідчить про те, що існує певний момент, коли більше навчання починає робити моделі менш «інтелектуальними». Дослідницька група називає це «катастрофічним перетренуванням» і припускає, що це пов’язано з тим, що вони описують як «прогресуюча чутливість».
Вони також припускають, що зі збільшенням кількості токенів модель стає більш крихкою. Це означає, що точне налаштування, яке можна розглядати як додавання шуму, починає зводити нанівець поліпшення, які спостерігалися раніше.
Щоб перевірити свою теорію, вони додали гаусівський шум до деяких моделей і виявили, що це призвело до того самого типу зниження продуктивності, свідками якого вони були раніше. Вони назвали точку неповернення «точкою перегину». Вони припускають, що після цього моменту будь-яке подальше навчання знизить стабільність моделі, що ускладнює її налаштування, яке є корисним для бажаного набору застосувань.
У висновку дослідники припускають, що в майбутньому розробникам LLM-моделей, можливо, доведеться оцінювати наскільки рівень навчання є достатнім або шукати інші методи для додаткового навчання, щоб не потрапити у точку неповернення.