UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
11 квітня 2025, 09:51
2025-04-11
Моделі штучного інтелекту все ще не справляються з процесом налагодження коду, показує дослідження Microsoft
Більшість розробників витрачають значну частину свого часу на налагодження коду, а не на його написання. Було б чудово мати такий ШІ-інструмент, який може запропонувати виправлення для сотень помилок, і все що потрібно зробити, це схвалити їх. Проте, нове дослідження Microsoft Research показало, що провідним ШІ-моделям поки ще не під силу таке завдання.
Більшість розробників витрачають значну частину свого часу на налагодження коду, а не на його написання. Було б чудово мати такий ШІ-інструмент, який може запропонувати виправлення для сотень помилок, і все що потрібно зробити, це схвалити їх. Проте, нове дослідження Microsoft Research показало, що провідним ШІ-моделям поки ще не під силу таке завдання.
Сучасні інструменти штучного інтелекту для кодування підвищують продуктивність і чудово пропонують рішення для помилок на основі наявного коду та повідомлень про помилки. Однак, на відміну від розробників-людей, ці інструменти не шукають додаткову інформацію, коли рішення не спрацьовує, залишаючи деякі помилки невиправленими.
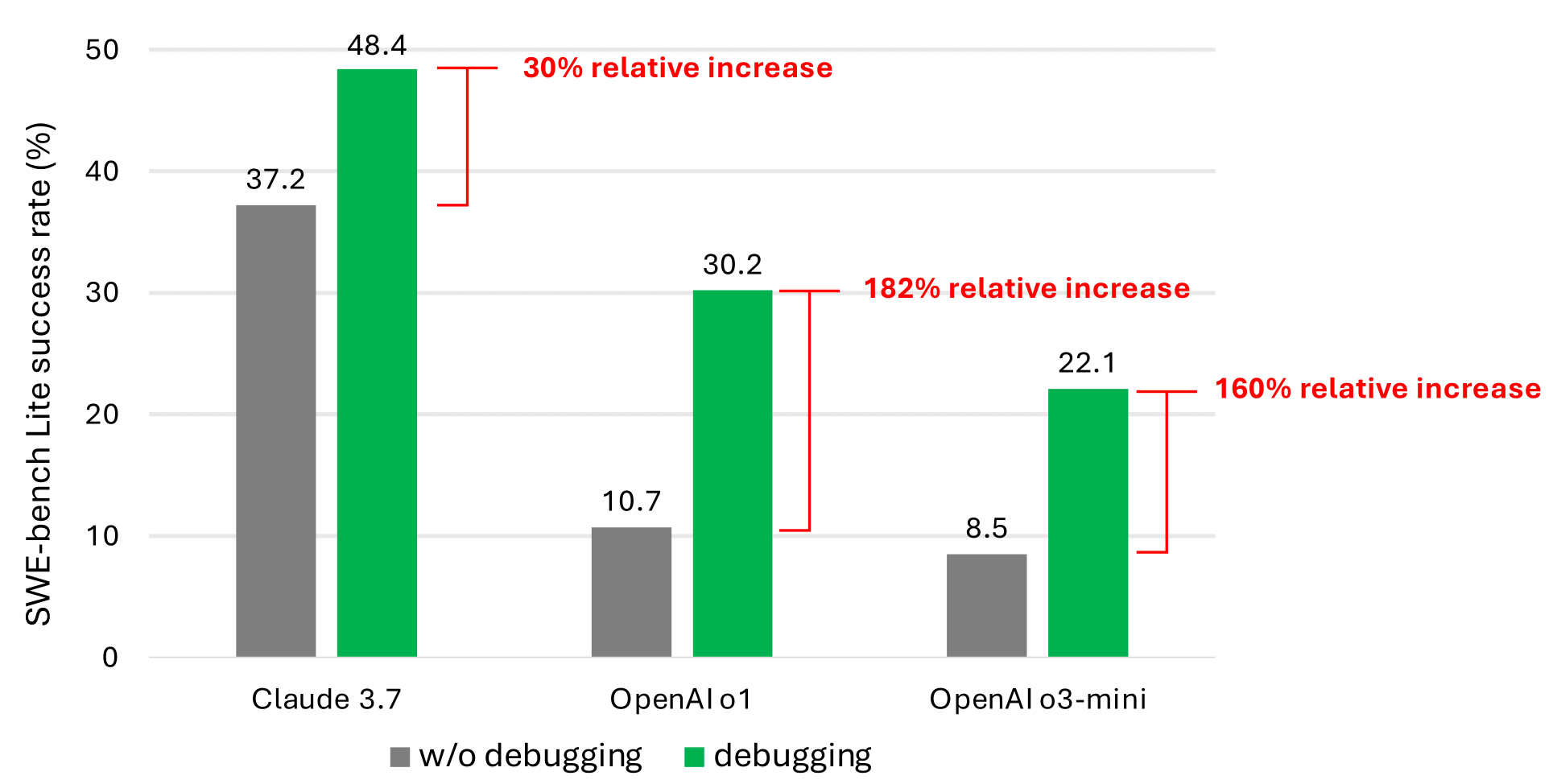
Дослідження Microsoft Research показує, що моделі, включно з Claude 3.7 Sonnet від Anthropic і o3-mini від OpenAI, не можуть налагодити багато проблем у тесті для розробки програмного забезпечення під назвою SWE-bench Lite.
Співавтори дослідження протестували дев’ять різних моделей як основу для агента, який мав доступ до ряду інструментів налагодження, включаючи налагоджувач Python. Вони доручили цьому агенту розв’язати набір із 300 завдань із налагодження програмного забезпечення від SWE-bench Lite, пише TechCrunch.
За словами співавторів, навіть при використанні більш потужних і сучасних моделей, їхній агент рідко успішно виконував понад половини завдань з налагодження. Claude 3.7 Sonnet мав найвищий середній показник успішності (48.4%), за ним йшли o1 від OpenAI (30.2%) та o3-mini (22.1%).
Чому така низька продуктивність?
Деяким моделям було важко використовувати доступні їм різні інструменти налагодження і зрозуміти, як вони можуть допомогти у розв’язанні різних проблем.
Проте більшою проблемою, на думку співавторів, була нестача даних. Вони припускають, що в нинішніх навчальних даних моделей недостатньо того, що представляють «послідовні процеси прийняття рішень» — тобто, сліди налагодження саме людиною.
«Ми твердо віримо, що навчання або тонке налаштування [моделей] може зробити їх кращими інтерактивними налагоджувачами», — написали співавтори у своєму дослідженні. «Однак для цього знадобляться спеціальні дані для виконання такого навчання моделі, наприклад дані траєкторії, які фіксують взаємодію агентів з налагоджувачем для збору необхідної інформації перед тим, як запропонувати виправлення помилки».
«Швидкість, яку ви можете отримати порівняно з самостійним програмуванням, просто божевільна». 3 поради з вайб-кодингу від провідних інженерів-програмістів
Репост новин змушує нас вважати себе розумнішими, але це не так. З лідерами думок теж працює, показує нове дослідження
Обмін новинними статтями з друзями та підписниками в соціальних мережах спонукає людей думати, що вони знають про теми цих статей більше, ніж вони знають насправді. І це працює з активними користувачами Facebook, що ставить під сумнів обізнаність ваших улюблених лідерів думок. Про це свідчить дослідження вчених з Техаського університету в Остіні. До речі, обов’язково покажіть цю статтю своїм друзям і репостніть у соцмережах.