UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
6 серпня 2025, 11:16
2025-08-06
OpenAI запускає дві відкриті моделі ШІ міркування: як вони показали себе у тестах
OpenAI у вівторок оголосила про запуск двох моделей ШІ міркування у двох розмірах: більша та потужніша модель gpt-oss-120b, яка може працювати на одному графічному процесорі Nvidia, та легша модель gpt-oss-20b, яка може працювати на споживчому ноутбуці з 16 ГБ пам’яті.
OpenAI у вівторок оголосила про запуск двох моделей ШІ міркування у двох розмірах: більша та потужніша модель gpt-oss-120b, яка може працювати на одному графічному процесорі Nvidia, та легша модель gpt-oss-20b, яка може працювати на споживчому ноутбуці з 16 ГБ пам’яті.
Це перший запуск відкритої моделі OpenAI з часів GPT-2, яка була випущена понад 5 років тому, пише TechCrunch. Їх можна вільно завантажити з онлайн-платформи розробників Hugging Face.
На брифінгу OpenAI заявила, що її відкриті моделі здатні надсилати складні запити моделям ШІ в хмарі. Це означає, що якщо відкрита модель не може виконати певне завдання, наприклад, обробку зображення, розробники можуть приєднати її до однієї з більш потужних закритих моделей компанії.
Як себе показали моделі
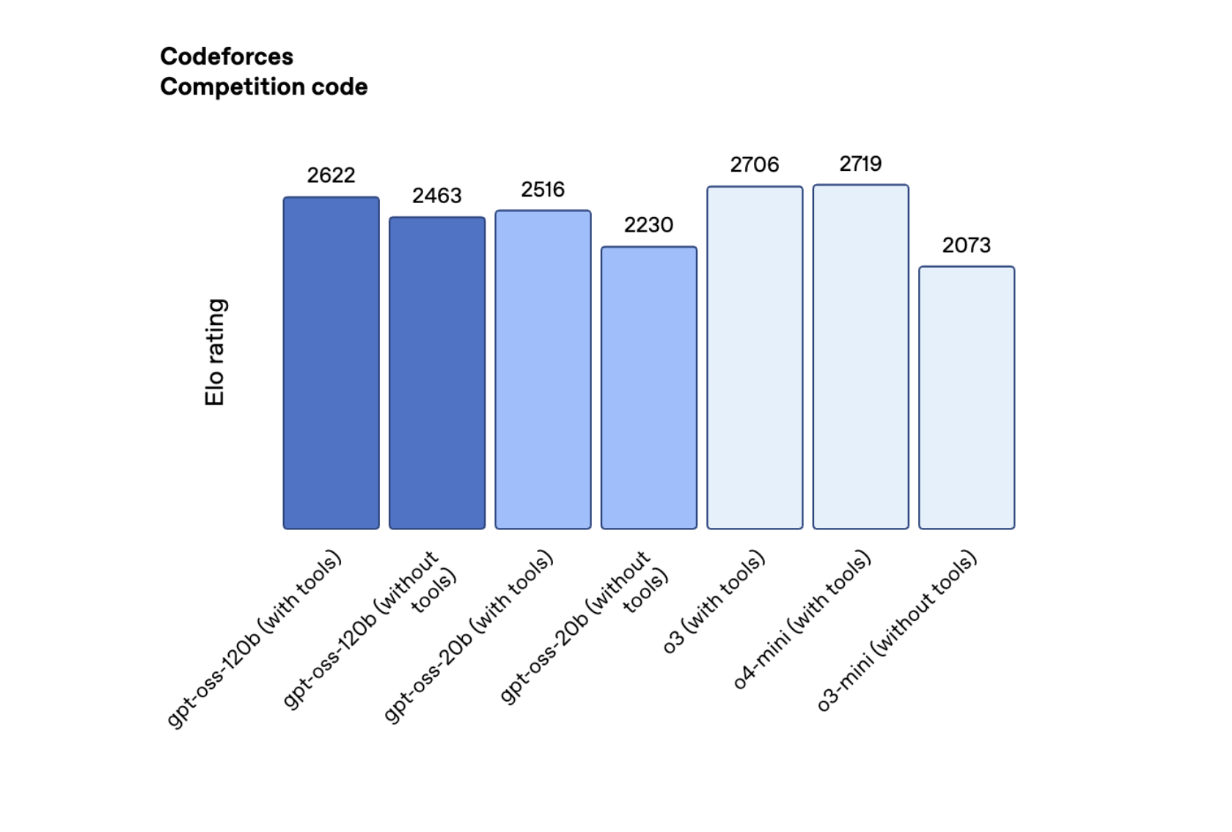
У Codeforces, тесті кодування, gpt-oss-120b та gpt-oss-20b отримали 2622 та 2516 балів відповідно, перевершивши R1 DeepSeek, але поступаючись o3 та o4-mini.
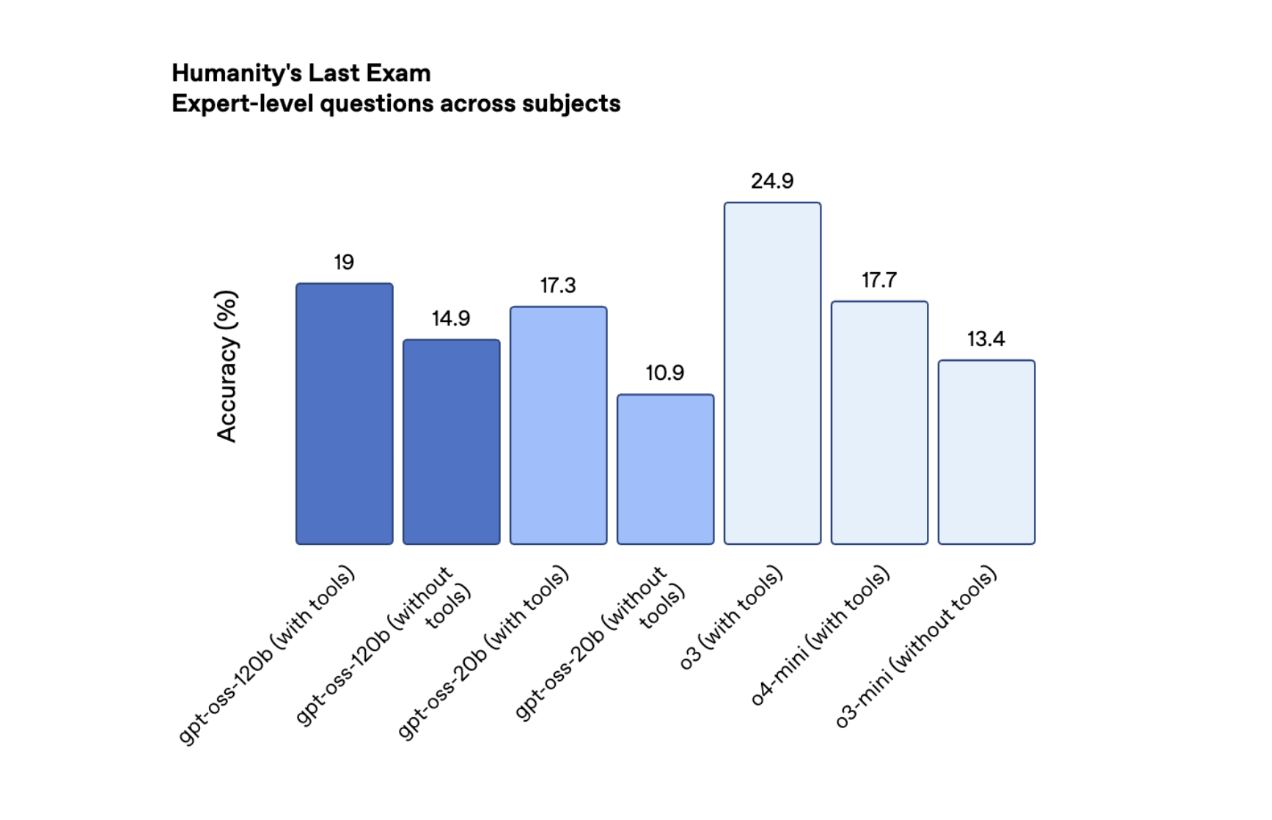
На Humanity’s Last Exam (HLE) — складному тесті, що складається з краудсорсингових запитань на різні теми — gpt-oss-120b і gpt-oss-20b отримали 19% і 17,3% відповідно. Ці результати поступаються o3, але перевершують провідні відкриті моделі від DeepSeek і Qwen.
Примітно, що відкриті моделі OpenAI викликають значно більше галюцинацій, ніж останні моделі мислення ШІ, o3 та o4-mini.
OpenAI виявила, що gpt-oss-120b та gpt-oss-20b галюцинували у відповідь на 49% та 53% запитань відповідно у тесті PersonQA — власному бенчмарку компанії для вимірювання точності знань моделі про людей. Це більш ніж утричі перевищує рівень галюцинацій моделі OpenAI o1, яка показала 16%, і вище, ніж у моделі o4-mini, що отримала 36%.
Навчання нових моделей
OpenAI стверджує, що її відкриті моделі були навчені за схожими процесами, як і її власні моделі. Кожна відкрита модель використовує архітектуру Mixture-of-Experts (MoE), щоб залучати меншу кількість параметрів для конкретного запитання, що робить її роботу ефективнішою. Наприклад, у моделі gpt-oss-120b, яка має загалом 117 млрд параметрів, OpenAI каже, що для кожного токена модель активує лише 5,1 млрд параметрів.
Компанія також заявляє, що її відкриту модель було навчено за допомогою високопродуктивного навчання з підкріпленням (RL) — процесу, що відбувається після попереднього навчання, щоб навчити моделі ШІ відрізняти правильне від неправильного в симульованих середовищах, використовуючи великі кластери GPU від Nvidia. Цей метод також застосовувався для навчання моделей серії o від OpenAI, і відкриті моделі мають схожий процес «ланцюжка міркувань» (chain-of-thought), коли вони витрачають додатковий час та обчислювальні ресурси, щоб обдумати свої відповіді.
Її відкриті моделі ШІ чудово підтримують агентів ШІ та здатні викликати такі інструменти, як вебпошук або виконання коду Python, як частину свого процесу ланцюга думок. Однак, OpenAI стверджує, що її відкриті моделі доступні лише в текстовому форматі, тобто вони не зможуть обробляти або генерувати зображення та аудіо, як інші моделі компанії.
OpenAI випускає gpt-oss-120b і gpt-oss-20b за ліцензією Apache 2.0, яка загалом вважається однією з найбільш дозвільних. Ця ліцензія дозволить підприємствам монетизувати відкриті моделі OpenAI, не сплачуючи за це і не отримуючи дозволу від компанії.
Однак, на відміну від повністю відкритих пропозицій від лабораторій штучного інтелекту, таких як AI2, OpenAI заявляє, що не публікуватиме навчальні дані, що використовуються для створення її відкритих моделей.
«Чи є у мене талант, якщо комп’ютер може імітувати мене?». Штучний інтелект пише книги авторам Amazon Kindle. The Verge поспілкувався з авторами та виявив багато цікавого
Письменники-романісти використовують штучний інтелект для створення своїх творів. Видання про технології The Verge поспілкувалося з письменницею Дженніфер Лепп, яка випускає нову книгу кожні дев’ять тижнів, й дізналося про те, як працює штучний інтелект для написання романів. Наводимо адаптований переклад статті.
Хочете повідомити важливу новину? Пишіть у Telegram-бот
Головні події та корисні посилання в нашому Telegram-каналі