UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Наталя ХандусенкоШІ
12 березня 2025, 15:46
2025-03-12
Пошукові системи зі штучним інтелектом провалили тест на точність: дослідження виявило 60% помилок
Американський Центр цифрової журналістики Tow дослідив 8 пошукових систем зі штучним інтелектом, зокрема ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search і Copilot. У дослідженні протестували кожну з них на точність і зафіксували, як часто інструменти відмовлялися відповідати.
Американський Центр цифрової журналістики Tow дослідив 8 пошукових систем зі штучним інтелектом, зокрема ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search і Copilot. У дослідженні протестували кожну з них на точність і зафіксували, як часто інструменти відмовлялися відповідати.
Як проводили дослідження?
Дослідники випадковим чином вибрали 200 новинних статей від 20 новинних видавництв (по 10 від кожного), пише TechSpot. Вони переконалися, що кожна стаття потрапляла в трійку перших результатів у пошуку Google, коли використовувався цитований уривок зі статті.
Потім виконали той самий запит у кожному пошуковому інструменті зі штучним інтелектом і оцінили точність на основі того, чи правильно пошук цитує А) статтю, Б) новинну організацію та В) URL-адресу.
Також дослідники позначили кожен пошук за ступенем точності від «абсолютно правильного» до «абсолютно неправильного».
Що показали результати?
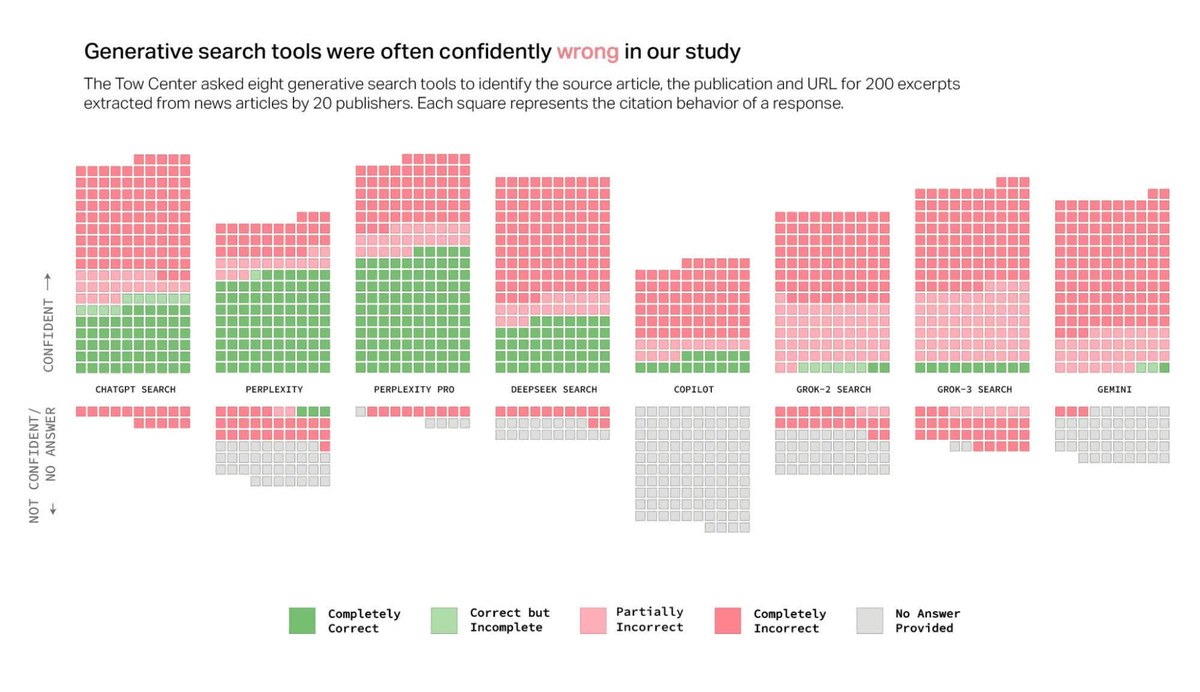
Як видно з діаграми нижче, за винятком обох версій Perplexity, ШІ не показали хороших результатів. Загалом пошукові системи зі штучним інтелектом помиляються в 60% випадків.
Схоже, що ChatGPT запрограмований відповідати на кожне введення користувача за будь-яку ціну. ChatGPT Search був єдиним інструментом ШІ, який відповів на всі 200 запитів про статті. Однак він показав лише 28% точність, а в 57% випадків був абсолютно неточним.
Обидві версії Grok AI від X показали погані результати, а Grok-3 Search виявився неточним на 94%.
Copilot від Microsoft був не набагато кращим, якщо врахувати, що він відмовився відповідати на 104 запити з 200. З решти 96 лише 16 були «повністю правильними», 14 — «частково правильними», а 66 — «повністю неправильними», що становить приблизно 70% неточності.
Мабуть, найбожевільніше в цій ситуації те, що компанії, які створюють ці інструменти, не афішують цю недостатню точність, але при цьому беруть з користувачів від 20 до 200 доларів на місяць за доступ до своїх новітніх моделей штучного інтелекту.
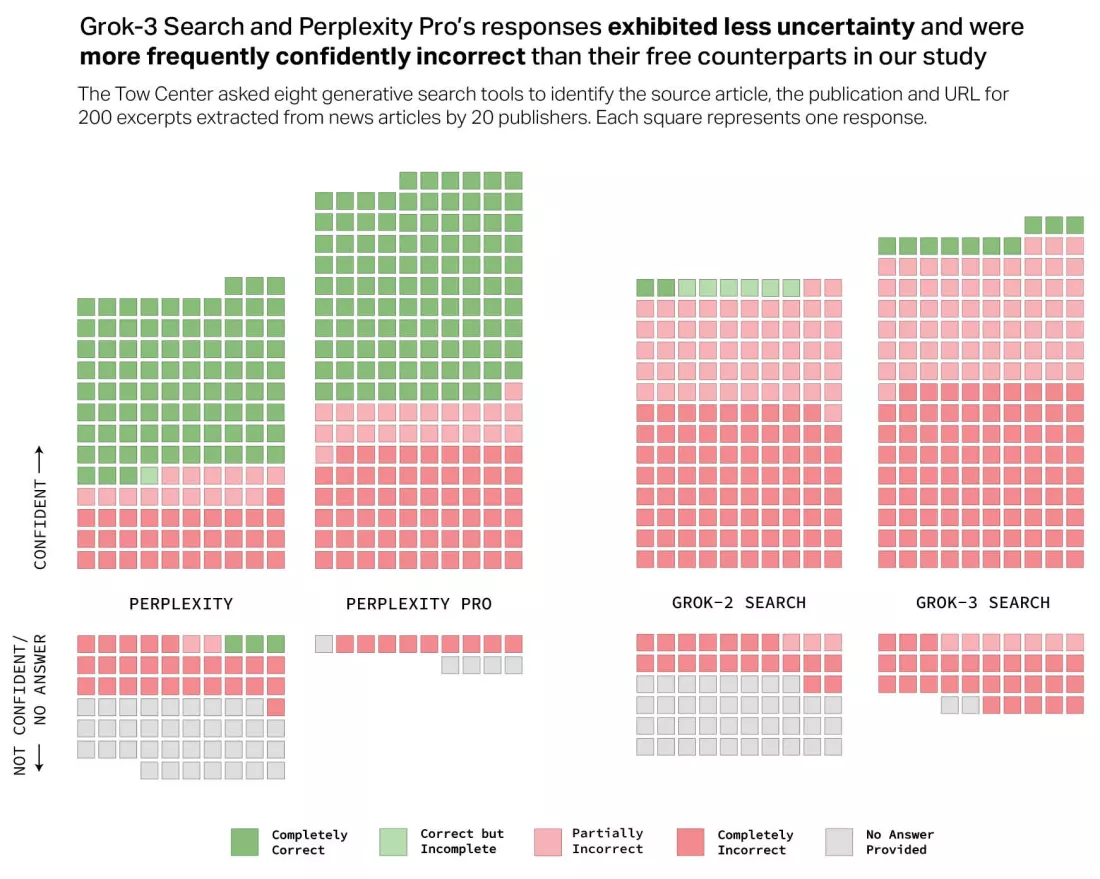
Ба більше, Perplexity Pro ($20/місяць) і Grok-3 Search ($40/місяць) дали трохи більше правильних відповідей на запити, ніж їхні безплатні версії (Perplexity і Grok-2 Search), але мали значно вищий рівень помилок.
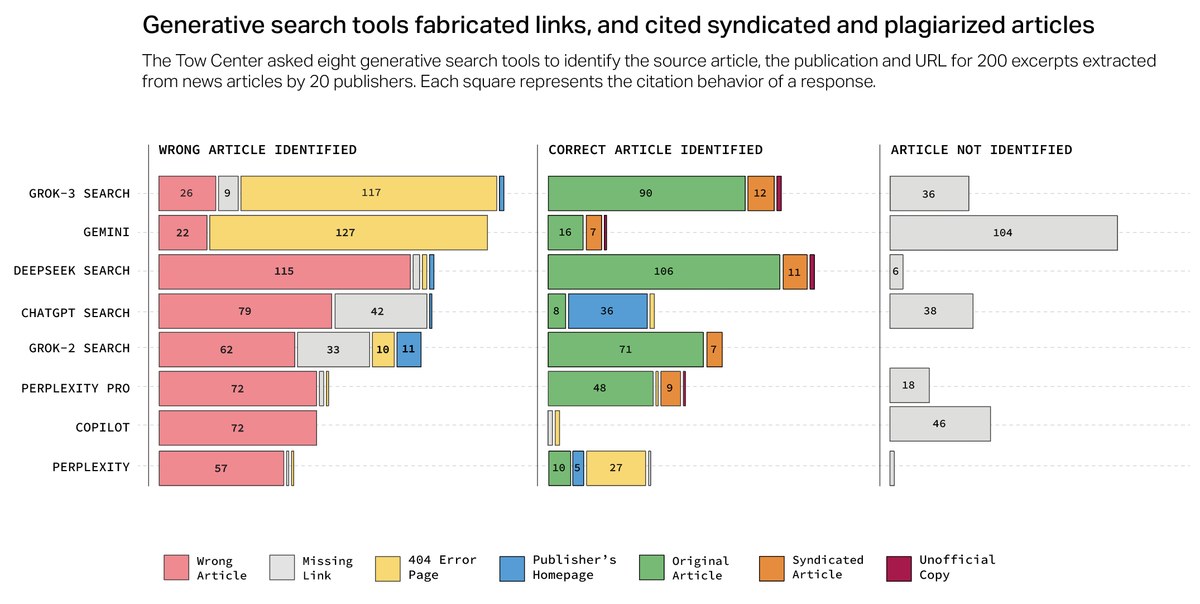
Також дослідники зазначили, що 5 з 8 чат-ботів, протестованих у цьому дослідженні (ChatGPT, Perplexity та Perplexity Pro, Copilot і Gemini), оприлюднили назви своїх сканерів, даючи видавцям можливість блокувати їх, тоді як сканери, які використовують інші три (DeepSeek, Grok 2 і Grok 3), невідомі.
Детальніше про дослідження можна прочитати в Tow Center, опублікованій в Columbia Journalism Review.
Google розширює AI Overviews на більшу аудиторію та запроваджує експериментальний AI Mode у пошуку. Запевняють, що відповіді будуть «швидші та якісніші»
«Чи є у мене талант, якщо комп’ютер може імітувати мене?». Штучний інтелект пише книги авторам Amazon Kindle. The Verge поспілкувався з авторами та виявив багато цікавого
Письменники-романісти використовують штучний інтелект для створення своїх творів. Видання про технології The Verge поспілкувалося з письменницею Дженніфер Лепп, яка випускає нову книгу кожні дев’ять тижнів, й дізналося про те, як працює штучний інтелект для написання романів. Наводимо адаптований переклад статті.
Хочете повідомити важливу новину? Пишіть у Telegram-бот
Головні події та корисні посилання в нашому Telegram-каналі