UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Марія БровінськаШІ
24 червня 2026, 09:05
2026-06-24
Empero випустила нецензуровану модель Qwythos-9B — і заявила, що навчала її на даних закритої Claude Mythos
Компанія Empero AI опублікувала на HuggingFace відкриту модель Qwythos-9B — компактну reasoning-модель на базі Qwen3.5-9B із повним файн-тюнінгом і навмисно відключеними обмеженнями. Технічно модель цікава, але її поява одразу порушила болюче питання для AI-індустрії: чи законно навчати моделі на синтетичних даних, згенерованих закритими комерційними системами?
Компанія Empero AI опублікувала на HuggingFace відкриту модель Qwythos-9B — компактну reasoning-модель на базі Qwen3.5-9B із повним файн-тюнінгом і навмисно відключеними обмеженнями. Технічно модель цікава, але її поява одразу порушила болюче питання для AI-індустрії: чи законно навчати моделі на синтетичних даних, згенерованих закритими комерційними системами?
Що таке Qwythos
Qwythos-9B — це повністю файн-тюнінгована версія Qwen3.5-9B, пост-натренована на понад 500 мільйонах токенів із chain-of-thought трейсами, які Empero генерувала власним інструментом rethink. Головні технічні характеристики:
Контекстне вікно 1 048 576 токенів (~1M) — завдяки YaRN rope-scaling із коефіцієнтом ×4 відносно нативної архітектури. Одне з найдовших вікон серед відкритих 9B-моделей, що дозволяє тримати в контексті цілі кодові бази, десятки наукових статей або довгі агентні сесії.
Нативний function calling за специфікацією Qwen3.5 — без додаткового файн-тюнінгу під інструменти.
Самокорекція з інструментами — у власних тестах Empero на 7 складних промптах (математика, кібербезпека, клінічна фармакологія, біохімія) модель коректно відповіла на всі 7, використовуючи Python-executor і web search та наводячи джерела.
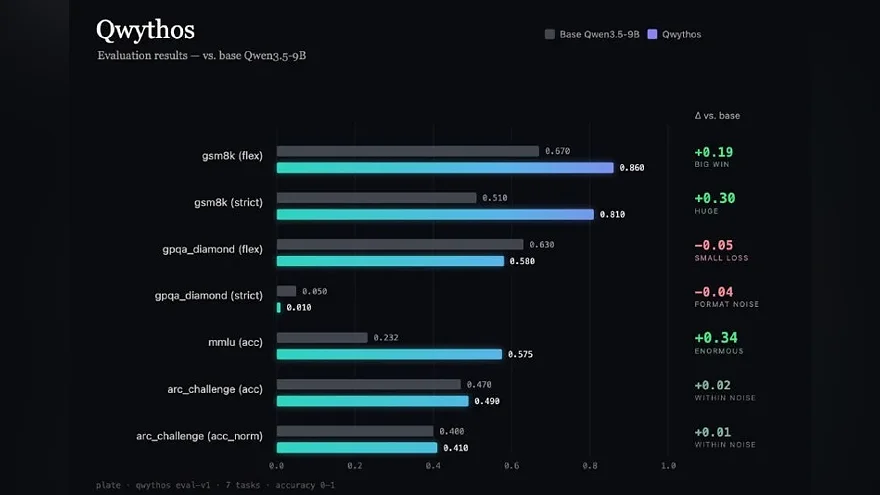
Бенчмарки проти базової Qwen3.5-9B: +34.3 бали MMLU, +30 gsm8k-strict, +19 gsm8k-flex. Втім, на gpqa_diamond модель показала −5 балів відносно бази — що важливо не замовчувати.
Для роботи з повним 1M-контекстом потрібна розподілена інфраструктура: один H100/H200 впевнено тримає 256k–512k токенів, але мільйон вимагає tensor-parallel multi-GPU або агресивного KV-cache offload.
Головна суперечність — дані Claude Mythos
Empero відкрито заявляє, що модель «пост-натренована на трейсах Claude Mythos і Claude Fable». Тут є принципова проблема.
Claude Mythos — це закрита frontier-модель Anthropic, яка не виходила у відкритий доступ. Anthropic не публікувала ні модель, ні датасети на її основі. Це означає, що Empero, найімовірніше, отримала «трейси» одним із двох способів: або через масову генерацію синтетичних даних через API (тобто фактично дистиляцію закритої моделі), або через якийсь несанкціонований доступ.
Перший варіант — пряме порушення Terms of Service Anthropic, які забороняють використовувати відповіді моделей для навчання конкуруючих систем. Саме через це OpenAI подавала позов проти компаній, що займались дистиляцією GPT-4. Empero поки що не прокоментувала, яким саме чином отримала ці дані.
«Intentionally uncensored» — для кого і навіщо
Empero позиціонує відсутність обмежень як ключову перевагу для дослідників і розробників, що працюють у кібербезпеці, біомедицині та фармакології — тобто в областях, де «надмірно вирівняні» моделі часто відмовляють або видають беззмістовні disclaimers замість реальної відповіді.
Це реальна проблема: надмірна цензура в AI-моделях дійсно обмежує їхню корисність для легітимних завдань — пентестерів, медичних дослідників, токсикологів. Але повна відсутність будь-яких обмежень — це вже інший полюс із власними ризиками, особливо якщо модель доступна для завантаження будь-ким без верифікації.
Де доступна
Qwythos-9B вже доступна на HuggingFace під повністю відкритою ліцензією без обмежень на комерційне використання. Harness для відтворення тестів на tool use Empero обіцяє опублікувати на GitHub.
«Чи є у мене талант, якщо комп’ютер може імітувати мене?». Штучний інтелект пише книги авторам Amazon Kindle. The Verge поспілкувався з авторами та виявив багато цікавого
Письменники-романісти використовують штучний інтелект для створення своїх творів. Видання про технології The Verge поспілкувалося з письменницею Дженніфер Лепп, яка випускає нову книгу кожні дев’ять тижнів, й дізналося про те, як працює штучний інтелект для написання романів. Наводимо адаптований переклад статті.
Хочете повідомити важливу новину? Пишіть у Telegram-бот
Головні події та корисні посилання в нашому Telegram-каналі