Відкрита українська мовна модель Lapa LLM отримала публічний реліз
Команда українських дослідників презентувала Lapa LLM v0.1.2 — велику мовну модель на базі Gemma-3-12B, оптимізовану для роботи з українською мовою.

Команда українських дослідників презентувала Lapa LLM v0.1.2 — велику мовну модель на базі Gemma-3-12B, оптимізовану для роботи з українською мовою.

Команда українських дослідників презентувала Lapa LLM v0.1.2 — велику мовну модель на базі Gemma-3-12B, оптимізовану для роботи з українською мовою.
Завдяки новому токенізатору Lapa LLM замінила 80 000 токенів із 250 000 на українські, зберігши якість оригінальної моделі. Це дозволило у півтора раза зменшити кількість обчислень для роботи з українськими текстами у порівнянні з оригінальною Gemma 3. Розробники Lapa стверджують, що Lapa LLM є найшвидшою моделлю українського NLP.
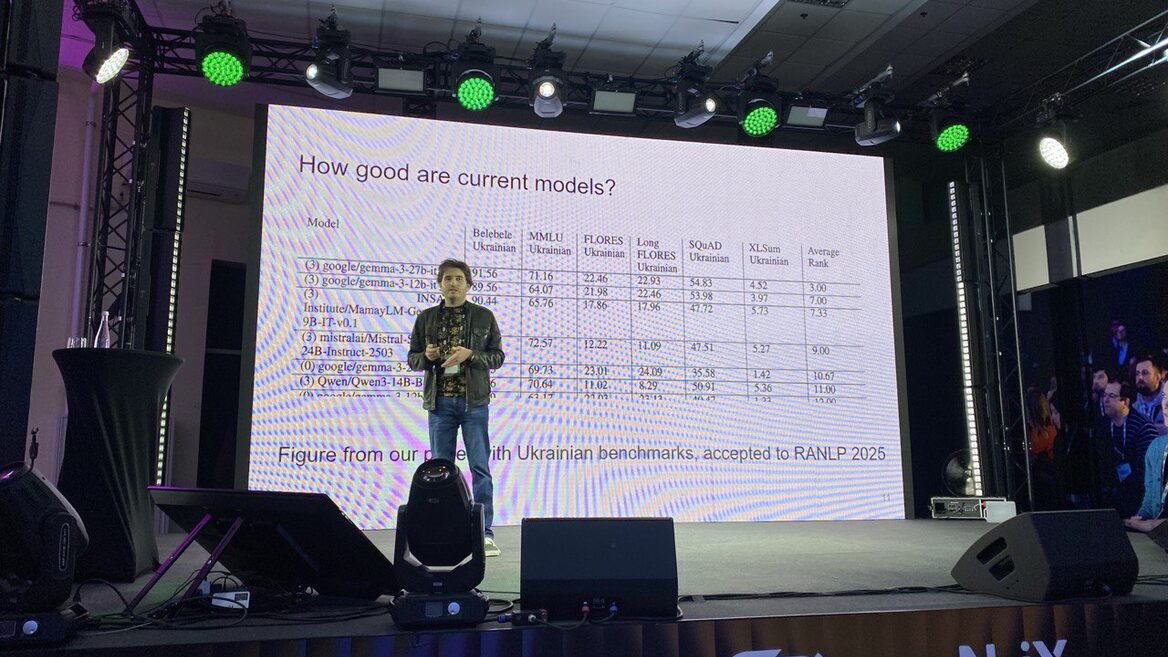
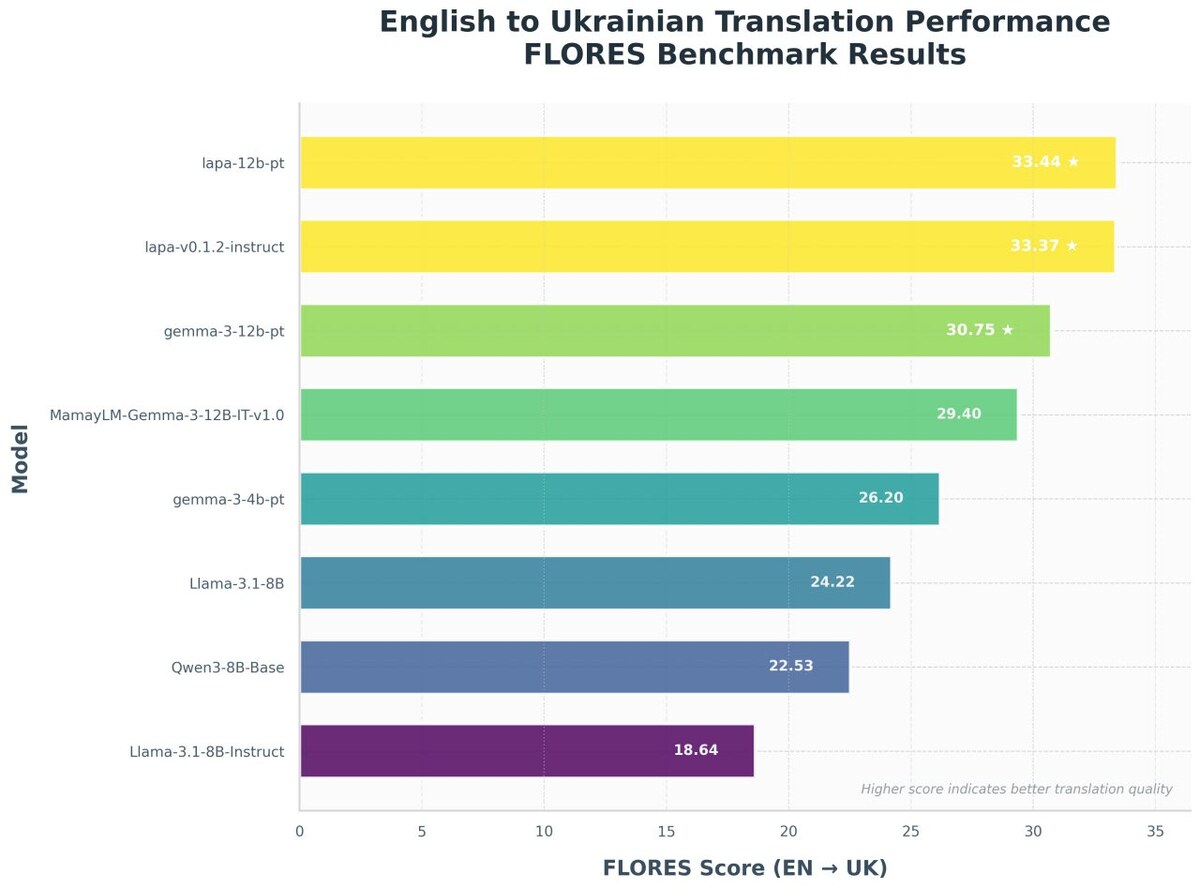
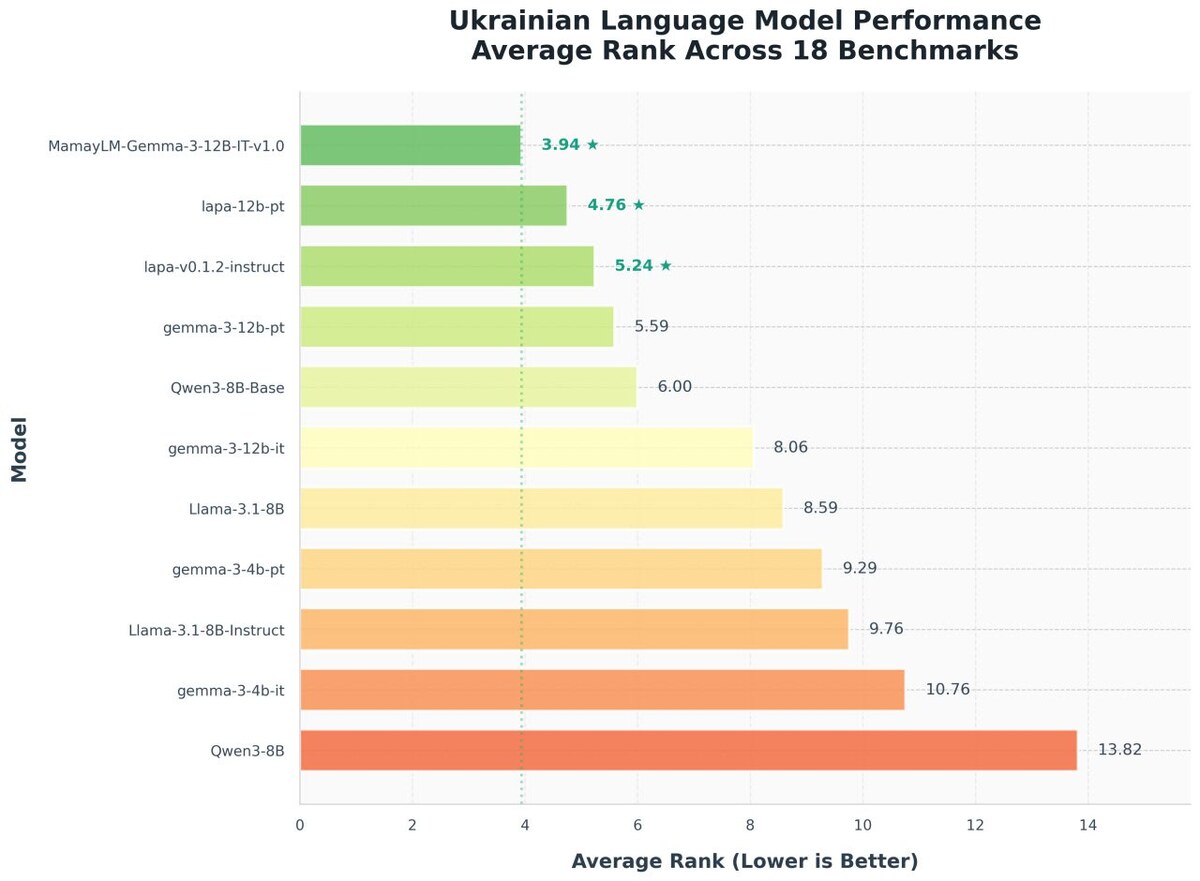
Версія 0.1.2 показала результати, близькі до лідера ринку MamayLM, у завданнях на розуміння інструкцій, переклад, резюмування та Q&A. У перекладі з англійської на українську вона досягла 33 BLEU на бенчмарку FLORES, ставши найкращим відкритим перекладачем між цими мовами.
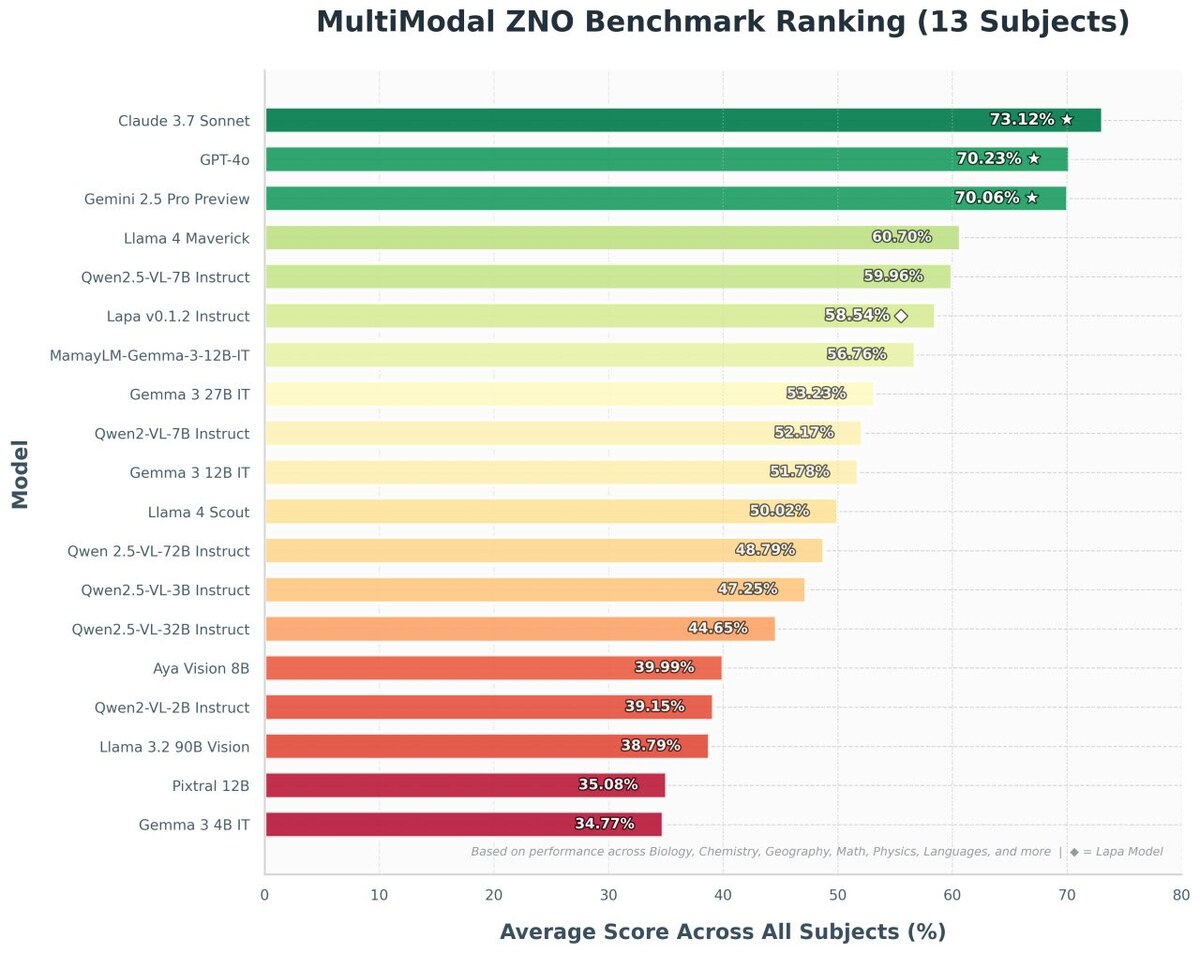
Окрім текстових завдань, Lapa LLM демонструє сильні результати в обробці зображень українською, а також успішно проходить тести на визначення пропаганди й дезінформації завдяки спеціальним фільтраційним методам.
Lapa LLM — повністю відкрита для комерційного використання. Команда опублікувала:
понад 25 датасетів для тренування,
вихідний код моделі,
методики фільтрації та оцінки якості даних,
документацію процесу навчання.
Модель натреновано на перевірених джерелах, зокрема матеріалах Бібліотеки Гарварду, а її якість підтверджено оцінками інших ШІ-моделей.
Надалі команда розробників планує завершити розробку міркувальної моделі та додати нові текстові та графічні датасети.
Спробувати модель можна за посиланням на Hugging Face, а код доступний на GitHub.