UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Олег ОнопрієнкоAI Eng
24 November 2025, 09:00
2025-11-24
One and a half times faster than Gemma 3. Interview with the leader of the Lapa LLM project — the most effective large language model for the Ukrainian language
Lapa LLM is already being called the best Ukrainian language model. It was trained by leading Ukrainian researchers in their free time, and it has become one of the most effective LLMs for the Ukrainian language. We spoke with Yuriy Paniv about the creation of Lapa LLM, working with data, and the challenges of artificial intelligence hallucinations.
Lapa LLM is already being called the best Ukrainian language model. It was trained by leading Ukrainian researchers in their free time, and it has become one of the most effective LLMs for the Ukrainian language. We spoke with Yuriy Paniv about the creation of Lapa LLM, working with data, and the challenges of artificial intelligence hallucinations.
— Tell us about your background. Who are you and what do you do?
My name is Yuriy Paniv. I am a graduate student at UCU in computer science. The topic of my dissertation is devoted to studying how to train large language models (LLM) on the smallest possible amount of data. In addition to my graduate studies, I work as a data scientist at Nortal and am the leader of the Lapa LLM project.
As part of this project, we trained a large Ukrainian language model. All datasets we worked on are as open as possible, and all model files are also publicly available, including the possibility of commercial use.
— How was the team of researchers who created Lapa formed, given that it was an international collaboration that included several universities?
Our collaboration is the result of social capital accumulated over many years. I have been working in Open Source since 2020, starting with a project for the Ukrainian text to speech project (speech synthesis). We met through profile groups.
After 2022, when large language models appeared, most of the team switched to natural language processing. The older part of the team met through Open Source work, while the younger part are students we worked with during their master's or bachelor's theses.
In total, the team consists of about 15 people. If we talk about those who work full-time, it's about 12.
— Tell us more about the name Lapa and the researcher after whom it was named.
The name is a tribute to our team member Bohdan Didenko. We named the model after Valentyn Lapa, a Ukrainian researcher who, together with Oleksiy Ivakhnenko, created the group argumentation method in the 1950s. This method is a precursor to Deep Learning. Although it was developed for an optimization problem, its importance is emphasized in research. For example, the famous AI researcher Jurgen Schmidhuber advocates mentioning Ivakhnenko and Lapa's method as one of the precursors of deep learning.
— What are the advantages of Lapa LLM and how did you achieve the fact that it is considered one of the best models for the Ukrainian language?
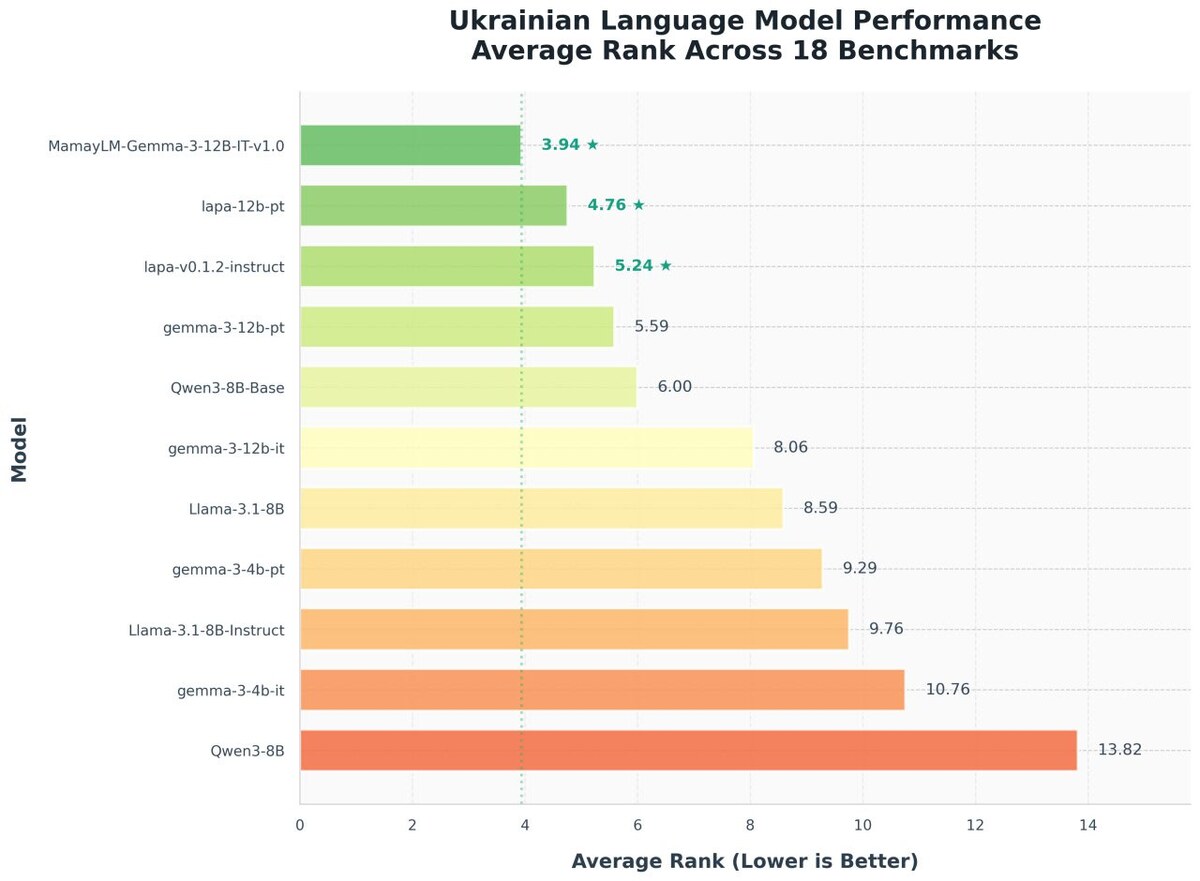
The first major achievement of the project is the efficiency of tokenization. To put it very simply: every large language model does not operate on text as such, it operates on predefined word fragments (tokens), converting them into numbers. The better the text is compressed into these numbers, the faster the model will produce results and the better the model will train, because the longer the context, the worse the model learns as a result. Changing the tokenizer itself is not a problem, but most of the known methods before this led to a loss of model quality. Our team, in particular Mykola Galtyuk, developed a method to adapt the existing tokenizer for the Ukrainian language without losing quality. As a result, we can convert Ukrainian text into tokens one and a half times more efficiently. This means that the model generation itself is one and a half times faster than in the original Gemma 3, on which we trained.
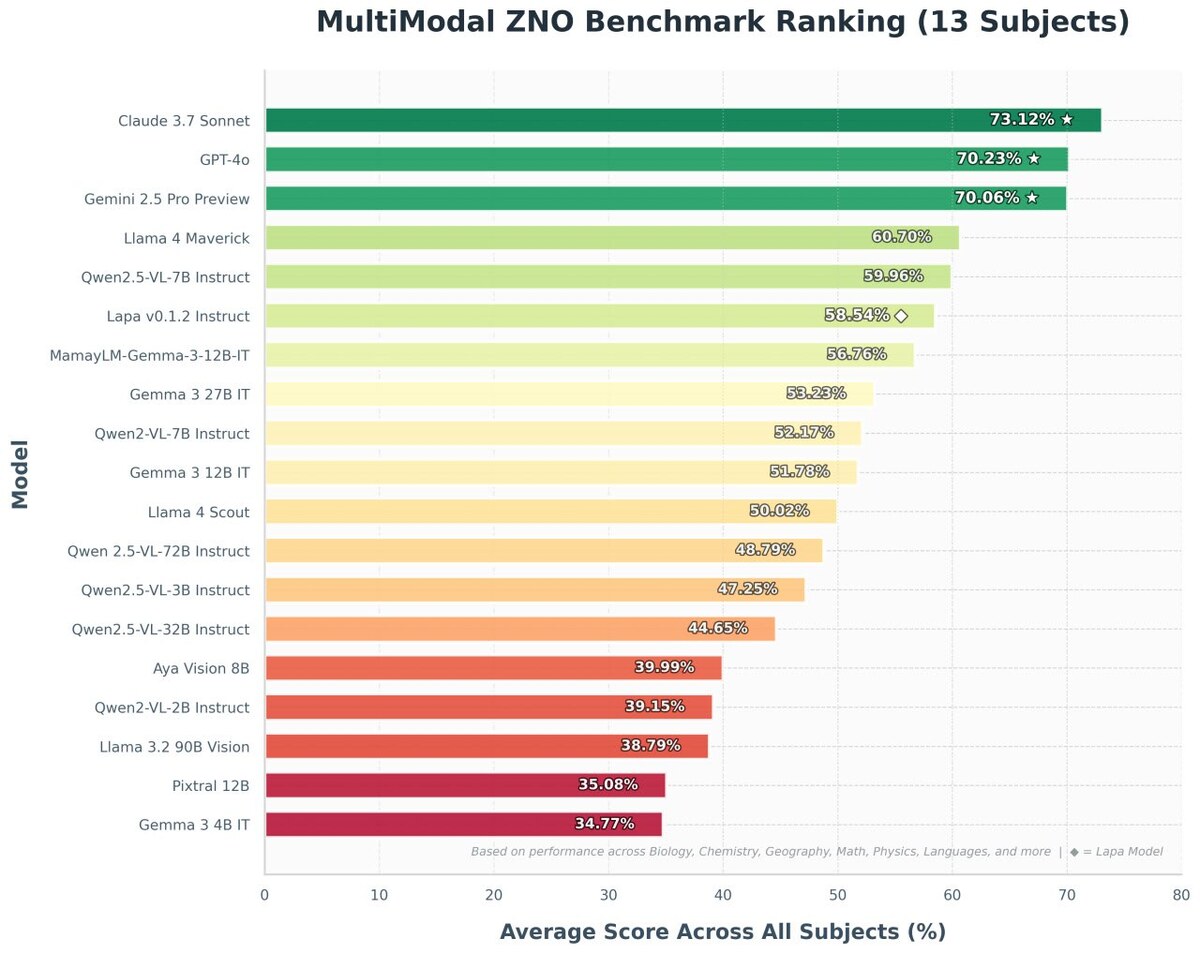
The second achievement is open datasets for various tasks. Thanks to high-quality open datasets for translations, Lapa is the best translator in the English-Ukrainian pair. We conducted measurements on various domains, including encyclopedic text, social networks, and working documents. We trained the model for legal translations using parallel corpora of EU and Ukrainian legislation. According to some calculations, if the adaptation of Ukrainian legislation to EU standards were performed only by humans, it would take about nine years. Our model can significantly speed up this process by working in a secure, closed environment, and produce great legal translations.
We also trained the model to summarize texts and answer questions from text. This is important for chatbots, document analysis, and RAG systems.
— Did representatives of the Ministry of Digital Affairs contact you with proposals for cooperation after learning about the development of such a powerful Ukrainian-language model?
We are actively communicating with everyone, since we made a model, but we cannot guess all the use cases that people may have. Now we are actively collecting feedback through demos and in personal communication. The Ministry of Digital Affairs has already tried the model, running its tests. We received feedback from them, which we will take into account for the next iteration.
— What percentage of hallucinations does Lapa currently have and what steps are you taking to reduce them? I myself encountered a hallucination when the model attributed the authorship of fictional “horror tales” to Taras Shevchenko.
This is an active phase 2 project, and frankly, we don't know how to fully fix it yet. We had a problem where when we asked the model what its name was, it would answer anything except its actual name, even though we had given it enough data to remember it. Even large API providers like OpenAI, who train models on massive amounts of data, have the hallucination problem.
For example, there was a recent scandal with the model Gemma, who was removed from Google AI Studio due to a hallucination about criminal proceedings against a congresswoman.
Currently, the most workable way is to train the model on all the information available. To solve the problem of incorrect contexts, as in the fairy tale example, we need to refine the dataset and analyze the data we got from the web demo.
— It is noted that Lapa can work with confidential data and be used in the defense sector. How safe is this, given that the team is small and resources are few?
Security has several dimensions:
First, sending military or sensitive documents via API is dangerous. Since Lapa is a local and open model, it can be downloaded and used in a closed loop, which eliminates this risk.
Secondly, before any use, it is imperative to perform measurements (benchmarking) to make sure how well the model works for a specific use case.
Third, there may be vulnerabilities in the training data. For example, the original Gema was trained on 6 trillion tokens, which is unrealistic to check manually. We, on our part, train the model on top of these trillions, adding 35 billion tokens. We are confident in this data because we have made it publicly available on Hugging Face. Other researchers can check this data, as we assessed its quality, and give feedback. This ensures that the model is safe in terms of transparency of the training data.
— How is Lapa protected from Russian propaganda and disinformation, which often finds its way into major language models?
This was at the top of our priority list, and we approached the problem in several stages. First, we created several datasets based on sources where, for example, disinformation specialists had already marked up existing hostile narratives. One of the sources we used was the very cool VoxCheck, which contained pairs of “propaganda label” and “counterargument.” We used these pairs to generate similar pairs through other models. So we had a narrative and two answers: the correct one based on facts and the answer from a propaganda perspective.
Next, we developed a classifier that gives an estimate of how true or false a text is. We then ran this classifier on our pretraining dataset and filtered out all cases where there was propaganda. We used these pairs as conditional discussion questions and correct, fact-based answers. Our tests confirmed that the model works well with disinformation, and we are pleased with this result.
— What was the most difficult and resource-intensive stage in developing and training the model?
80% of the work is data processing, and 10% is engineering decisions and training the model. The largest amount of resources was spent on data processing, not training itself. In particular, during pretraining, the model learns to guess the next most likely word on a huge array of texts. At this stage, we filtered and assessed the quality of 35 billion tokens. We measured: ease of reading, educational value, grammatical correctness, which excluded gibberish, and manipulability. This stage took a little over two months (instead of the expected one) due to engineering problems related to scale. Even the available resource of 64 H100 video cards was not enough.
Next, the model is trained to respond in a chat format. That is, the existing datasets were converted to a chat format, and the rest was translated. The translation of 1.5 billion tokens of the datasets for instructions alone took about 15 days.
— Where did you start, what computing power did you have at the beginning, and how did you attract additional funding?
Unfortunately, there was no funding for salaries. The entire team worked as volunteers in their free time. Thank you to the entire team for joining such a large project and in their free time, after the shelling, people answered our regular calls and did this model. It is very nice to understand that there are many people who want to do something useful for the entire community.
We started with UCU servers, which had two A6000 video cards. We received these servers thanks to the support of Eleks as part of the Oleksiy Skrypnyk Memorial Grant and they are shared for use by graduate students. We developed a scope plan for the project, what we would develop first: datasets, benchmarks, and this plan was already being pitched everywhere.
Then, through acquaintances, we came across the French startup Comand AI. They were interested in a Ukrainian model capable of working with documents in a closed loop (mainly for military US cases). It was mutually beneficial: they for their needs, and we for the model to be open and commercially available.
Hugging Face supported us by providing an enterprise subscription. This allowed us to easily work, store datasets and models, and host them.
We would be happy to receive any support and partnership. The main thing we are looking for is computing resources, as this is our main bottleneck at the moment.
— Are there any restrictions, for example, for small businesses that want to use Lapa LLM in their systems?
No restrictions. The model is covered by the standard Gema license. The only restrictions specified in the license relate to the spread of disinformation. There are no restrictions on either military or civilian use.
— Are the 25 datasets you used enough, or do you need to create new ones?
There is always room to add data. We don't see Lapa LLM as the final model. There is a paper by researchers called Chinchilla Scaling Laws that calculates how much data needs to be added to train the model to the state we want.
Even by calculations, there is still room for improvement. We added 37 billion tokens, while Google trained on 6 trillion. The main goal of the project is to accelerate the community so that other researchers can add their own datasets and train the model to their needs, already having a cool Ukrainian-language base.
— What unexpected requests for Lapa LLM have you received in the month after the public launch?
We are still analyzing the feedback. Among the most frequent and, probably, funny queries, there are two leaders. The first is “Who holds this district?” (approximately 40% of queries to LLM). You could say that I helped popularize this question. I tested all the new models on “who holds this district,” while at Mamay LLM Hanna Yukhymenko, who worked on this model, under this inspiration, I understand, added this question to the dataset.
And the second popular request is the generation of various jokes, so far we are thinking about how to finalize this use case.
— Tell us about your future plans for Lapa LLM.
Our plans for the next month of active development include:
Taking feedback into account.
Working on generalization and reinforcement learning. That is, when the model does not learn to remember, but only receives an assessment of whether the answer is correct or not.
Image processing: recognition of printed and handwritten texts. In fact, many businesses and not only, work with handwritten documents that need to be somehow converted into text and analyzed.
Creating a programming assistant that can work in a closed loop with the Ukrainian language.
You can try the model at the Hugging Face link, and the code is available on GitHub .
Ukrainian answer ChatGPT. How Kyivstar and the Ministry of Digital Economy will build a national LLM for Ukraine: insights and international AI experience VEON