UNIT.City — місце, де люди працюють... КРАЩЕ! Обирай свій простір просто зараз 👉
Олег ОнопрієнкоГаряченьке
18 грудня 2025, 13:19
2025-12-18
Тепер ШІ говоритиме українською ліпше. Дослідники з УКУ та КНУ значно покращили якість синтезу українського мовлення
Розробка спрямована на вирішення однієї з найскладніших проблем обробки української мови — коректного відтворення слів я з правильними наголосами залежно від змісту речення.
Розробка спрямована на вирішення однієї з найскладніших проблем обробки української мови — коректного відтворення слів я з правильними наголосами залежно від змісту речення.
Команда науковців з Українського католицького університету та Київського національного університету імені Тараса Шевченка представила нове комплексне рішення для систем перетворення тексту на мовлення (Text-to-Speech).
Дослідники Анастасія Сеник, Михайло Лук’янчук, Валентина Робейко та Юрій Панів розробили інноваційний підхід, що поєднує контекстно-залежне передбачення наголосів із новим фонемайзером. Про новий прорив в синтезі мовлення повідомив Юрій Панів у своєму блозі.
Зокрема дослідники зробили наступну роботу:
Розмічений вручну бенчмарк методів наголошення тексту і, відповідно, заміри наявних методів наголошення.
Модель для розпізнавання наголосів у тексті для авторозмітки омографів.
Модель, яка проставляє наголоси у контексті, гібридний підхід зі словником — це тепер SOTA.
Фонемізатор на основі методу з «Сучасна українська літературна мова: Лексикологія. Фонетика» Мойсієнка, код якого зробив Михайло Лук’янчук під керівництвом Валентини Робейко.
Головною перепоною для створення природного українського «голосу» роботів завжди була складна фонологія та недетермінована система наголосів. В українській мові існують омографи — слова, які пишуться однаково, але мають різне значення та звучання залежно від наголосу (наприклад, «зАмок» та «замОк», «дорОга» та «дорогА»).
Попередні системи часто помилялися, оскільки покладалися лише на словники без розуміння контексту, або використовували правила, що надмірно узагальнювали вимову. Новий підхід науковців вперше пропонує модель, яка аналізує все речення, щоб визначити правильний наголос та фонеми.
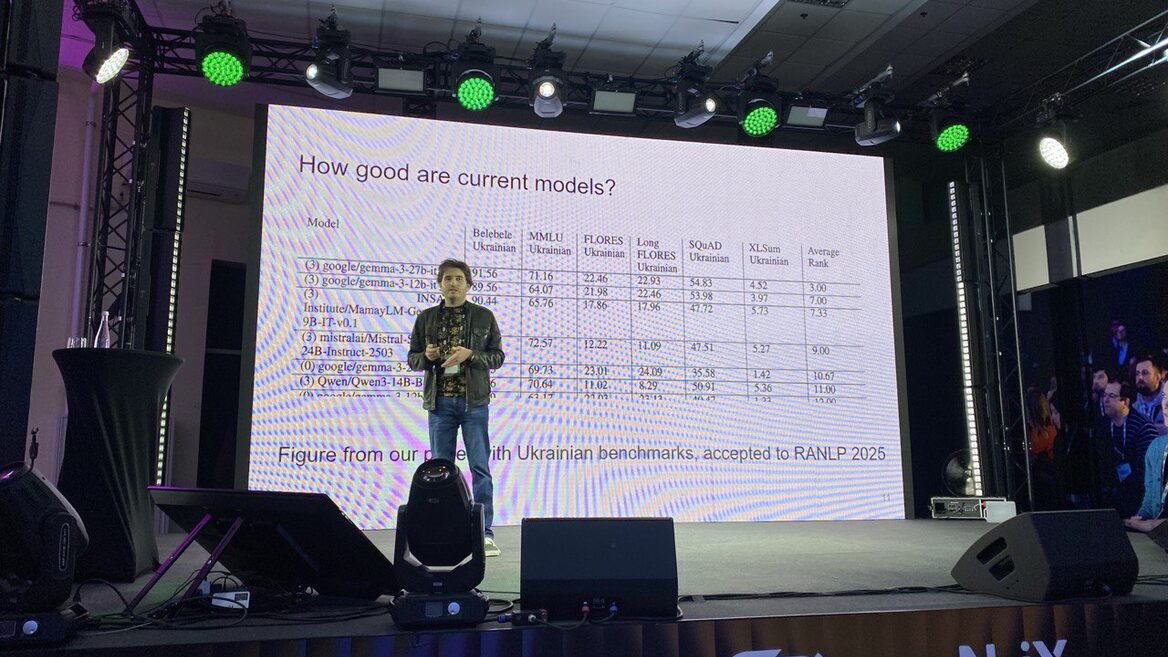
Технічне рішення базується на гібридній архітектурі, яка використовує нейромережу ByT5 для аналізу контексту та детально прописані лінгвістичні правила для перетворення букв у звуки. Крім самої моделі, команда створила та виклала у відкритий доступ перший бенчмарк для оцінки систем прогнозування наголосів, який складається з понад 1000 анотованих речень.
Експерименти показали, що новий фонемайзер досягає низького рівня помилок (WER) — всього 1,23% на тестовому наборі даних, а комбінована система передбачення наголосів перевершує наявні нейромережеві аналоги, досягаючи точності 92,5%.
Для кінцевих користувачів ці зміни означають значне підвищення якості звучання україномовних віртуальних асистентів, навігаційних систем та засобів для читання екрана.
Завдяки новій технології синтезований голос звучатиме більш природно та «по-людськи», правильно інтонуючи складні речення та рідкісні слова. Всі напрацювання, включно з кодом та даними, автори зробили публічно доступними, що дозволить іншим розробникам інтегрувати ці покращення у свої продукти.
Нагадаємо раніше Юрій Панів в ексклюзивному інтерв’ю для dev.ua про розробку великої мовної моделі для української мови Lapa LLM розповів, що модель у півтора раза швидша за Gemma 3.
Нещодавно український ШІ-стартап Respeecher, відомий за технологією клонування голосів для Netflix, HBO, Paramount, запустив україномовний Text-to-speech сервіс, який, на відміну від іноземних аналогів, не має «пластмасового» акценту та вміє спілкуватися суржиком.