Мене звати Діана, я розробниця програмного забезпечення в продуктовій компанії BOTMAKERS LLC. Певний час я активно працювала над Instafill.ai технологією, основна задача якої — позбавити юристів і звичайних користувачів від рутинного заповнення PDF-форм. У цій статті я хочу розкрити, яке рішення стало фундаментом для нашого проєкту, та покажу, як ми вдосконалювали його на практиці.
Моє завдання — не просто розповісти про власний досвід, а й показати еволюцію ідеї Instafill.ai: від початкового концепту у вигляді простого Python-скрипта до сучасного інструменту. Цей матеріал буде корисним для розробників, які хочуть оптимізувати роботу з документацією та створювати інтелектуальні системи для автоматизації. Хто знає — можливо, наш досвід розробки Instafill.ai стане для відправною точкою для ваших експериментів!
Передісторія та виклики
Інтерактивні PDF-документи стали невід’ємною частиною бізнес-процесів і освітніх систем, проте їхнє ручне заповнення залишається виснажливим. Монотонність, висока ймовірність помилок під час ручної обробки та постійне марнування ресурсів — усе це робить автоматизацію не просто зручним інструментом, а критично важливим кроком для оптимізації роботи з документами.
Наша команда вирішила зосередитися на болючих точках користувачів, сформулювавши три ключові питання:
- Чи пропонують сучасні рішення на ринку дійсно ефективні механізми для автоматизації PDF-форм?
- Якщо так, то що ми можемо запропонувати клієнтам поверх існуючих інструментів, щоб надати їм додаткові переваги?
- Чи реально залучити штучний інтелект для цілковитого виконання цього завдання без участі людини?
Наразі останнє питання залишається найбільш дискусійним. Однак динамічний прогрес у сфері великих мовних моделей дає підстави вважати, що роль людини в заповненні шаблонних PDF-документів може бути практично мінімізована. Саме на цій ідеї й ґрунтується основа нашого рішення, яке детальніше розкриється в наступних частинах статті.
Структура рішення: від парсингу PDF до інтелектуального заповнення даних
Перейдемо до технічної частини. Наше рішення розбите на три ключові фази:
- Парсинг PDF-документа: читання тексту та інтерактивних полів форми.
- Аналіз та генерація даних: застосування AI-моделі для інтерпретації інформації та підбору відповідних значень.
- Генерація оновленого файлу: інтеграція заповнених даних у PDF із подальшим експортом.
На перший погляд — логічно та просто. Реалізувати це можна будь-якою мовою, проте наш вибір зупинився на Python. Чому?
- Універсальність: широка бібліотечна база (наприклад, PyPDF2, pdfplumber) для роботи з PDF.
- Швидкість розробки: мінімум коду для тестування гіпотез — ідеально для ітераційних експериментів.
- Інтеграція з ML: зручність підключення AI-моделей через frameworks (TensorFlow, PyTorch) чи API (OpenAI, Hugging Face).
У результаті ви отримаєте готовий скрипт, який можна адаптувати під будь-які типи PDF-форм — від юридичних договорів до анкет. І головне: цей підхід дозволяє масштабувати рішення, додаючи нові правила обробки даних без повного переписування коду.
Впровадження системи: детальний алгоритм дій
1. Читання PDF
Скрипт ініціює роботу з аналізу PDF-файлу для видобування тексту та інтерактивних полів форми. Текст документу слугує AI-моделі базовим контекстом — він допомагає зрозуміти призначення форми (наприклад, договір, анкета) та логіку її заповнення.
```python
def extract_pdf_text (pdf_bytes: bytes) -> str:
pdf_text = ''
pdf_document = fitz.open (PDF_EXT, pdf_bytes)
for page_num in range (len (pdf_document)):
page = pdf_document.load_page (page_num)
text_page = page.get_textpage ()
pdf_text += text_page.extractText ()
return pdf_text
```
Також важливо максимально деталізувати інформацію про поля (назви, типи) і передати її у зрозумілому для моделі форматі. Це зменшує ризик «галюцинацій» AI, оскільки що точніше контекст — то відповідніші результати він генерує.
```python
def extract_pdf_fields (pdf_bytes: bytes) -> list[dict]:
form_fields = []
pdf_document = fitz.open (PDF_EXT, pdf_bytes)
for page_num in range (len (pdf_document)):
page = pdf_document.load_page (page_num)
widget_list = page.widgets ()
if widget_list:
for widget in widget_list:
form_fields.append ({
'name': widget.field_name,
'label': widget.field_label,
'type': widget.field_type_string,
'max_length': widget.text_maxlen
})
return form_fields
```
2. Делегуємо всю роботу АІ
Перед використанням штучного інтелекту для заповнення полів форми скрипт генерує промпт. Саме від якості цього промпту залежить, чи станеться «магія». Промпт містить загальну інструкцію і в якості параметрів приймає PDF-компоненти, отримані в попередньому кроці, та дані в неструктурованому форматі. Ці дані — джерело інформації, необхідної для заповнення форми. Для простоти скрипту вони зчитуються з текстового файлу, але в загальному випадку це можуть бути файли будь-якого формату: PDF, DOCX, JPG і т. д.
```python
def fill_fields_prompt (pdf_text: str, fields: list[dict], source_info: str) -> str:
return f"""
You are an automated PDF forms filler.
Your job is to fill the following form fields using the provided materials.
Field keys will tell you which values they expect:
{json.dumps (fields)}
Materials:
— Text extracted from the PDF form, delimited by <>:
<{pdf_text}>
— Source info attached by user, delimited by ##:
#{source_info}#
Output a JSON object with key-value pairs where:
— key is the 'name' of the field,
— value is the field value you assigned to it.
««"
```
Для інтеграції обрано модель GPT-4o від OpenAI через її точність і швидкість. Ви можете тестувати інші моделі, але ключовим залишається адаптація промптів під конкретну LLM. Результат виклику — словник із парами «назва поля: значення», готовий до фінального етапу.
```python
def call_openai (prompt: str, gpt_model: str = 'gpt-4o'):
response = openai_client.chat.completions.create (
model=gpt_model,
messages=[{'role': 'system', 'content': prompt}],
response_format={"type»: «json_object"},
timeout=TIMEOUT,
temperature=0
)
response_data = response.choices[0].message.content.strip ()
return json.loads (response_data)
```
3. Заповнення PDF
На завершальному етапі скрипт інтегрує згенеровані AI значення у відповідні поля форми. Це дає на виході оновлений PDF-документ, який можна відразу використовувати або відправляти далі за логікою вашого workflow.
```python
def fill_pdf_fields (pdf_bytes: bytes, field_values: dict) -> io.BytesIO:
pdf_document = fitz.open (PDF_EXT, pdf_bytes)
for page_num in range (len (pdf_document)):
page = pdf_document.load_page (page_num)
widget_list = page.widgets ()
if widget_list:
for widget in widget_list:
field_name = widget.field_name
if field_name in field_values:
widget.field_value = field_values[field_name]
widget.update ()
output_stream = io.BytesIO ()
pdf_document.save (output_stream)
output_stream.seek (0)
return output_stream
```
Тестуємо рішення
Першочергово наш продукт розроблений для американського ринку, тому для тестування я обрала форму IRS W-9 — поширену форму в США для збору даних платників податків. Вона активно використовується у фрілансі, контрактній роботі та фінансових операціях, що робить її ідеальним прикладом для демонстрації рішення.
Для заповнення форми використано такі тестові дані:
```
1. personal info
john smith
222 Victory St, 125
San Francisco, CA, 94111
2. business info
BOTMAKERS, LLC
has foreign partners
account numbers: 1234567890, 0987654321
tin: 123456789
3. requester
jane smith
87 Independence St
```
Тепер найцікавіше: подивімось на результат заповнення форми та проаналізуємо якість роботи цього рішення.
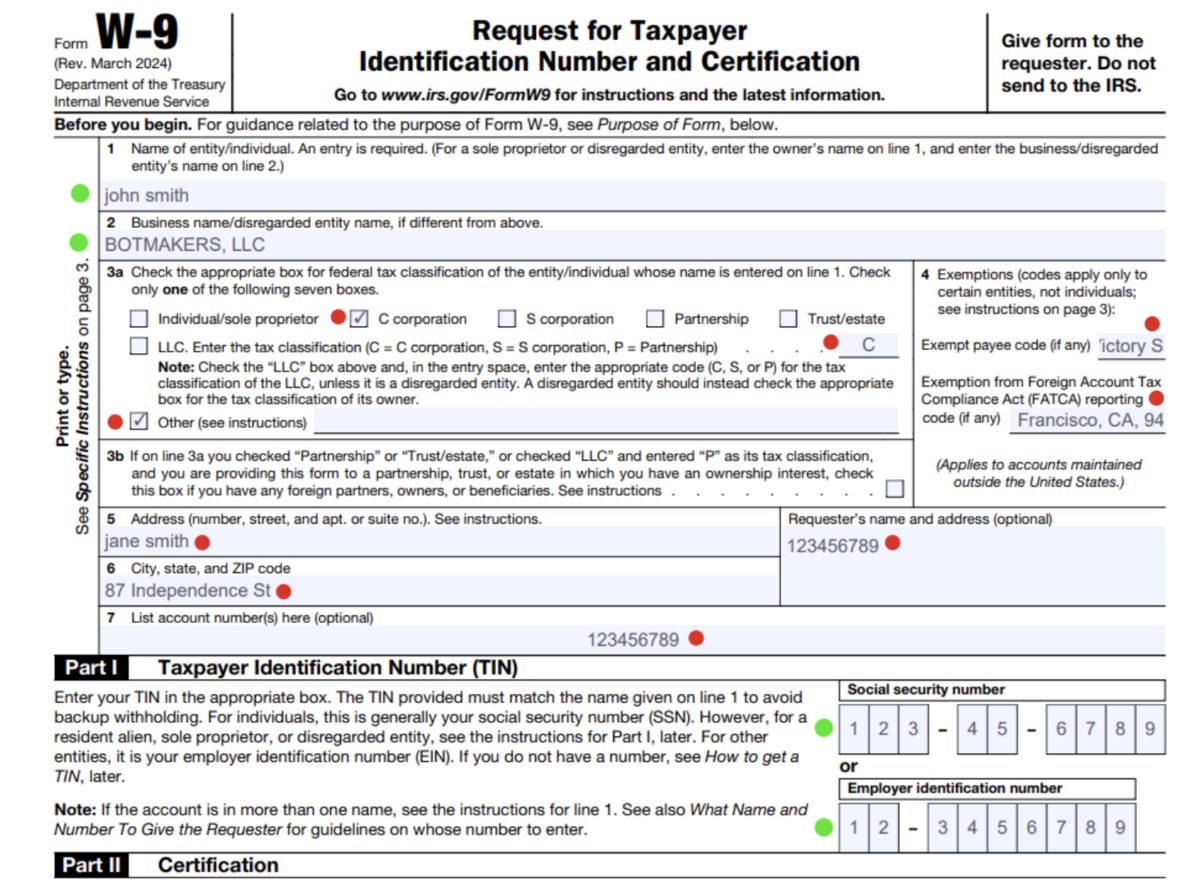
А результат роботи рішення наступний:
- Усі поля форми заповнені. На першому етапі можна констатувати, що генеративний AI зі своїм завданням впорався.
- Детальний аналіз результатів виявив як вдалі, так і невдалі моменти. Частина полів (позначені зеленим) містять коректні дані, інші (червоні) — здається, що заповнені абсолютно випадковим чином.
Пропоную зазирнути глибше й розібратись, чому так сталось. Звертаю вашу увагу на поля, що були витягнуті з PDF-форми (наводжу лише частину з них, усі інші мають аналогічний вигляд):
```json
{
«name»: «topmostSubform[0].Page1[0].Boxes3a-b_ReadOrder[0].c1_2[0]»,
«label»: null,
«type»: «CheckBox»,
«max_length»: 0
},
{
«name»: «topmostSubform[0].Page1[0].f1_05[0]»,
«label»: null,
«type»: «Text»,
«max_length»: 0
},
{
«name»: «topmostSubform[0].Page1[0].f1_06[0]»,
«label»: null,
«type»: «Text»,
«max_length»: 0
},
{
«name»: «topmostSubform[0].Page1[0].Address_ReadOrder[0].f1_07[0]»,
«label»: null,
«type»: «Text»,
«max_length»: 0
}
```
Назва поля грає ключову роль для AI, але в цьому випадку назви полів недостатньо інформативні. Наприклад, поле з ідентифікатором «topmostSubform[0].Page1[0].Boxes3a-b_ReadOrder[0].c1_2[0]» не дає моделі жодних підказок про те, які дані очікуються. Цим і пояснюється незадовільний результат.
Спробуймо заповнити іншу форму — TR-205 (Request for Trial by Written Declaration). Цей документ використовується в Каліфорнії, щоб подати клопотання про розгляд справи за письмовою декларацією. Така можливість дозволяє водіям оскаржувати дорожні порушення без необхідності з’являтися в суді.
Використовуємо наступні тестові дані для заповнення:
```
Court:
SUPERIOR COURT OF CALIFORNIA
100 NORTH STATE STREET
UKIAH CA 95482
BRANCH #23480
Citation: KV19133
Case: 231N07977
Defendant:
John Smith
1234 Main Street, Apt. 101
Due date: 07/21/24
Bail amount: $441
Date mailed: 06/21/24
Evidence:
— photographs (5)
— witness testimony
Statement of facts:
I increased my speed to avoid a possible traffic accident due to a truck in the middle of the road.
Today: 06/21/24
```
І отримуємо наступний результат:
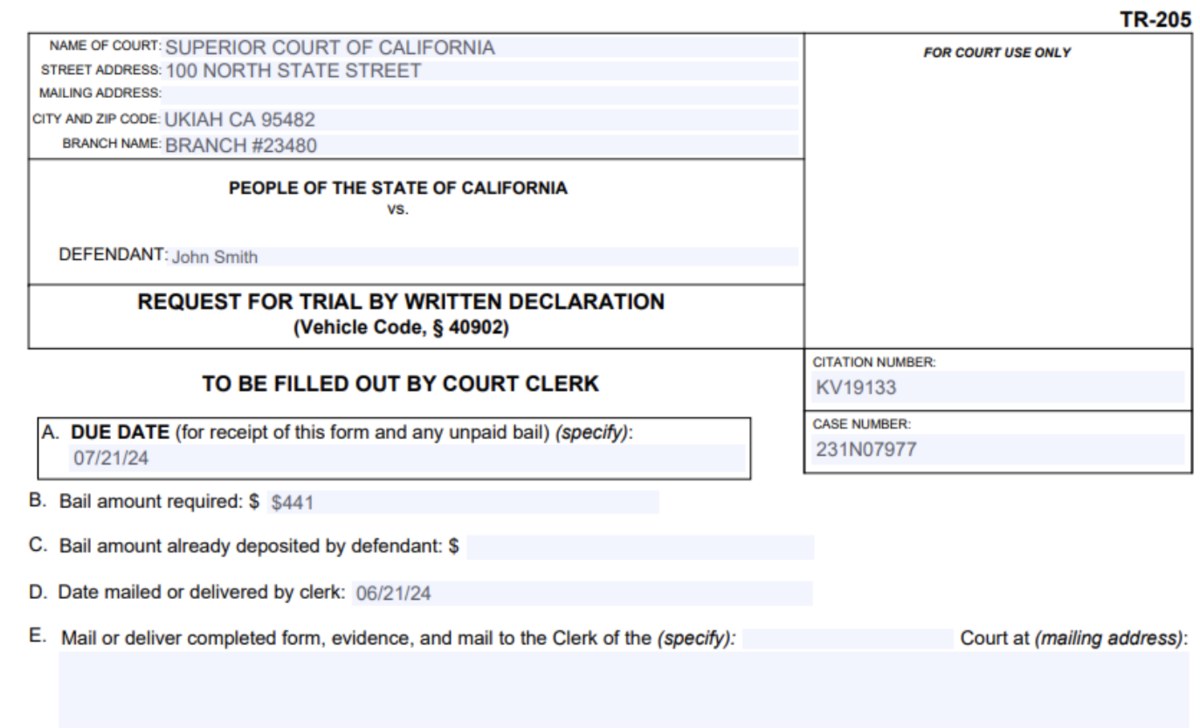

Зверніть увагу, що ця форма заповнилась точніше. Всі дані з тестового файлу коректно відображені у відповідних секціях форми. Справа в тому, що поля TR-205 мають зрозуміліші ідентифікатори (наприклад, «CITATION NUMBER:»), що дозволяє AI точніше інтерпретувати їх призначення.
```json
{
«name»: «TR-205[0].Page1[0].P1Caption[0].CitationNumber[0].CitationNumber[0]»,
«label»: «CITATION NUMBER:»,
«type»: «Text»,
«max_length»: 0
},
{
«name»: «TR-205[0].Page1[0].P1Caption[0].CaseNumber[0].CaseNumber[0]»,
«label»: «CASE NUMBER:»,
«type»: «Text»,
«max_length»: 0
}
```
Отже, порівняння з полями з попереднього прикладу показує: якість результату безпосередньо залежить від структури PDF-форми. Це, між іншим, залишається головним викликом, для якого досі не знайдено ідеального рішення.
Висновок
Отже, підсумуємо. У статті ми дослідили, як штучний інтелект може автоматизувати роботу з PDF-формами, використовуючи для прикладу IRS W-9 та TR-205. Ключова мета — продемонструвати, як автоматизація зменшує рутину та кількість помилок у роботі з документами. Усі матеріали, включаючи вихідний код на Python, доступні у відкритому репозиторії на GitHub.
Особисто для мене цей матеріал — нагадування про шлях, який подолала наша система: від простого скрипта до комплексної технології. Воно досі потребує вдосконалень, але прогрес очевидний. І це доводить: навіть невеликі зміни можуть призвести до значних результатів.
Сподіваюся, ця стаття надихне вас експериментувати з AI-інструментами та глибше досліджувати автоматизацію різних процесів. Хто знає — може, саме ваш проєкт стане наступним кроком у цій галузі?
Залишайте ваші коментарі та питання — буду рада обговорити деталі, досвід чи ідеї щодо вдосконалення рішення!