Тіммейтів стає більше, а процеси ніяк не покращуються. У такій ситуації багатьом важко визнавати, що headcount не дорівнює ефективність і тим паче зрілість команди.
У цій статті я розповім про типову для багатьох engineering-команд проблему — втрату ефективності під час масштабування. Моя робота на позиції Head of Development Department в UPSTARS, компанії, що активно зростає, охоплює безпосередню роботу з викликами, про які йтиметься далі. Почнімо?
Чому команда «гальмує» під час зростання
Команда росте: спочатку 2–3 розробники, потім 5–10, далі 30+. І в якийсь момент все починає «гальмувати» — фічі робляться довше, рішення затягуються, а люди обходять процеси заради швидкості.
Зазвичай структура команди просто перестає відповідати масштабу. Це окремий випадок закону Конвея: архітектура системи відображає те, як організовані люди, що її будують. Тому реструктуризація — це архітектурне рішення.
Структура, яку ви закладаєте сьогодні, через рік стане архітектурою.
Три моделі — але не три етапи
У матеріалі пройдусь по трьох моделях, з якими стикався сам: лінійній, матричній і крос-функціональній. Це не сходинки, через які мусить пройти кожна команда. Багато компаній десятиліттями живуть у матриці, частина стартапів стартує одразу крос-функціонально, а Amazon свого часу масштабував лінійну логіку дуже далеко через single-threaded leaders. Це радше різні відповіді на різні задачі, ніж етапи дорослішання.
Коли варто задуматися про зміни: загальні сигнали
Перед тим як переходити до самих моделей, хочу згадати сигнали, що універсальні для будь-якого типу структури:
- люди обходять процеси заради швидкості;
- рішення затягуються тижнями;
- неформальні домовленості витісняють офіційні;
- на Head або CTO лягає все більше ручної синхронізації.
Це все маркери того, що поточна форма більше не тримає масштаб. Якщо помічаєте два і більше — час задуматись.
Ці сигнали не стосуються лише структури. Ті самі симптоми можуть бути результатом некомпетентного менеджера, токсичної культури, слабкого тулінгу або розмитої стратегії. Перш ніж ламати структуру, варто перевірити, чи проблема справді в ній. Реструктуризація заради реструктуризації просто переносить тертя в інше місце і продовжує розгрібання наслідків на місяці.
Лінійна модель — сила і межі одного центру
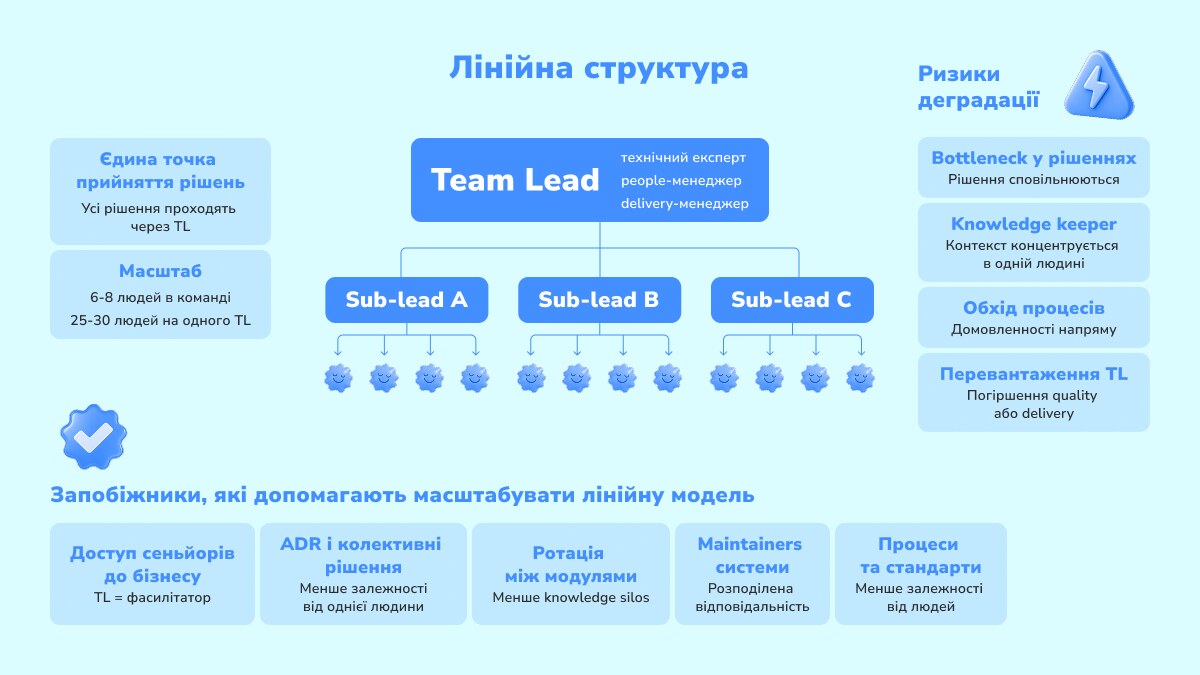
Коли ми говоримо про менеджмент команди розробки, перше, що спадає на думку — це не people partner і не PM (далі — PM/PO залежно від структури компанії), а саме Team Lead. У лінійній моделі він поєднує одразу кілька ролей: технічного спеціаліста, people-менеджера і фактично delivery-менеджера. Зручність очевидна: команда завжди знає, до кого йти, експертиза концентрується в одному місці.
Скільки людей може втримати лінійна модель
На рівні однієї команди добре працює правило двох піц — десь 6–8 людей. З кількох таких команд можна зібрати лінійну ієрархію під одним TL: span of control зазвичай дає менеджеру 5–10 прямих звітів, тож з одним рівнем sub-leads виходить орієнтовно 25–30 людей. Цифра умовна. Реальний поріг — це момент, коли TL перестає тримати в голові всю систему одночасно: архітектуру, поточні проблеми, людей, пріоритети.
Головна пастка: bottleneck і knowledge keeper
Головна проблема такої моделі — TL стає bottleneck’ом і носієм критичного контексту. Усі питання проходять через TL, у результаті або страждає технічна якість, або падає швидкість delivery. Коли тімлід замикає на собі весь контекст і архітектурні рішення, команда стає залежною від конкретної людини, а не від процесів.
Як покращити лінійну модель?
Кілька речей, які реально допомагають:
- дозволити Senior-інженерам напряму спілкуватись з бізнесом щодо технічних деталей (TL у цій схемі стає фасилітатором, а не посередником);
- колективно фіксувати архітектурні рішення через ADR, щоб прибрати «усну архітектуру» і знизити залежність від однієї голови;
- ротувати інженерів між модулями — поступово, без фанатизму — так розмиваються knowledge silos і піднімається Bus Factor;
- призначати Maintainers за окремі частини системи, щоб відповідальність розподілялась, а не концентрувалась.
У такому вигляді лінійна структура добре працює для невеликих команд або сервісних моделей. Але в продуктовому середовищі вона досить швидко впирається в обмеження комунікації. Симптоми типові: TL стає вузьким місцем, погодження затягуються, люди починають домовлятися напряму. У цей момент перехід до іншої моделі майже неминучий, і він завжди означає менше ручного контролю і більше формалізованих правил.
Матрична модель — контрольований конфлікт
Якщо в лінійній структурі все управління спирається на TL, то в матричній з’являються вже дві гілки: технічна (TL) і продуктова (PM). У теорії це система стримувань і противаг — TL відповідає за «how», PM за «what» і «when». На практиці ця модель часто працює як контрольований конфлікт. Як тільки зникають чіткі правила взаємодії, вона перестає бути ефективною.
Як матриця деградує
Найтиповіший сценарій деградації — коли TL приносить у матрицю «лінійні» звички й починає сам визначати продуктові пріоритети. Або, навпаки, коли PM ігнорує технічні обмеження заради швидкості. В обох випадках баланс руйнується: команда або деградує технічно, або втрачає швидкість. Окремий маркер — коли інженери отримують задачі з двох незалежних джерел і починають читати конфліктні сигнали. Якість продукту в такому стані падає швидко.
Запобіжники, без яких матриця не працює
Чітка матриця відповідальності (DACI або RACI) фіксує, хто приймає рішення: архітектура і технічні питання — зона TL, пріоритети і строки — зона PM. Спільні OKR вирівнюють цілі: технічні ініціативи на кшталт SLO/SLI чи observability мають перестати сприйматись як «забаганки розробників» і стати частиною бізнес-результату. Регламент ескалації, наприклад, 24 години на конкретний управлінський конфлікт, обмежує тривалість суперечки й не дає їй блокувати команду. Конкретна цифра тут — це просто деталь, важливий сам факт ліміту.
У такій конфігурації конфлікт стає механізмом балансування. Модель добре працює в продуктових командах середнього розміру — 20-80 людей, де системно конфліктують швидкість і якість. Її ціна — постійна необхідність утримувати баланс і працювати з конфліктом як з процесом, а не винятком. Сигнал зламу зазвичай однозначний: спірні питання починають регулярно вилітати на рівень Head або CTO, бо TL з PM більше не домовляються.

Крос-функціональна модель — автономія з ціною
В якийсь момент навіть матрична модель починає буксувати. Розробники, QA й аналітики починають погоджувати задачі напряму між собою, в обхід менеджменту, бо так банально швидше. Це вже сигнал, що coordination cost між командами став занадто високим.
Фактично команда сама починає мутувати: бере на себе більше відповідальності, межі між ролями всередині задач розмиваються. Те, що спочатку виглядало як «обхід процесів», з часом стає новою нормою. Далі є дві стратегії: або жорстко повертати контроль, або формалізувати цю поведінку. Другий шлях і веде до крос-функціональної моделі.
Важливо не романтизувати цю модель. Вона добре працює там, де цінність можна локалізувати всередині команди. Якщо ж система має високий рівень централізованих залежностей (platform, shared services, compliance), крос-функціональність може збільшити вартість координації, а не зменшити її.
Team Topologies і Spotify: два джерела, одна модель
Окрема ремарка. Те, що в індустрії називають «крос-функціональною моделлю», насправді є синтезом двох різних шкіл. Перша — Team Topologies (Skelton & Pais), де ключовою метрикою є cognitive load команди. Друга — ідеї зі Spotify-моделі: Squads, Tribes, Guilds і Chapters. Компанії зазвичай беруть звідти різне і змішують по-своєму, тому конкретні впровадження так сильно відрізняються одне від одного.
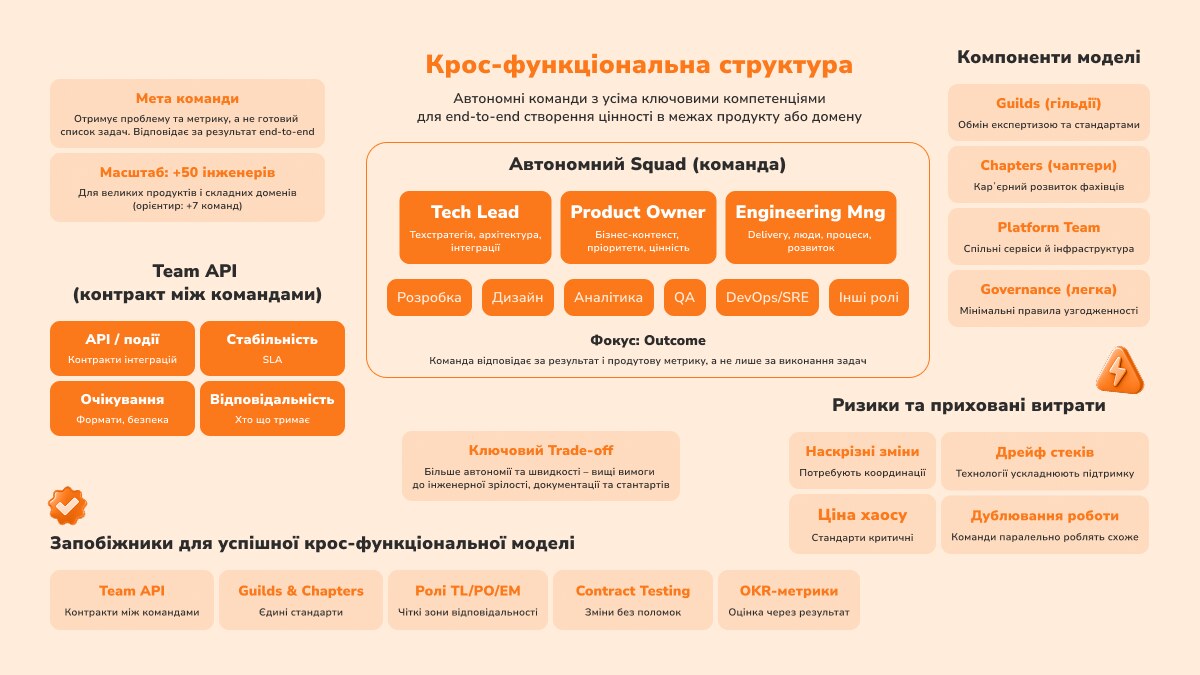
Що ж таке крос-функціональна команда сама по собі?
Це автономна одиниця, яка має всі необхідні компетенції для створення цінності в межах конкретного продукту або домену. Вона об'єднує різні ролі — розробку, дизайн, аналітику, тестування, продуктове управління і здатна проходити повний цикл, від ідеї до delivery. Ключова відмінність від feature team — команда отримує проблему і метрику, а не готовий список фіч на квартал. Якщо задачі приходять згори у вигляді скоупу, крос-функціональність залишається лише на оргсхемі.
Team API — інтерфейс між командами
Основна перевага такої структури — менше міжкомандних залежностей. Команда відповідає за задачу end-to-end, тому значна частина coordination cost просто зникає.
Але складність нікуди не дівається — вона переноситься в Team API. Тобто в набір чітких контрактів між командами:
- API та інтеграції;
- правила змін;
- відповідальність за сумісність;
- очікування щодо стабільності.
Які ролі утримують систему
У такій моделі критично важливо не розмивати ролі:
- Tech Lead відповідає за технічні рішення та інтеграції;
- Product Owner — за пріоритети й бізнес-контекст;
- Engineering Manager — за delivery, людей і процеси.
Коли одна людина починає тягнути кілька ролей одночасно, модель поступово деградує назад у лінійну або матричну.
Окрему роль відіграють Staff/Principal інженери, що працюють між командами: вирівнюють архітектуру, ведуть RFC, знижують coordination cost без створення додаткових менеджерських рівнів. У великих системах це один із ключових механізмів масштабування.
Без чого крос-функціональна модель не масштабується?
Для крос-функціональної моделі запобіжники — це базові умови існування. Без них автономія дуже швидко перетворюється на хаос:
- Team API виступає базовим контрактом — інтеграції без чітких домовленостей не приймаються, і це прибирає неявні залежності.
- Рольова модель TL/PO/EM прибирає «спільну відповідальність без відповідального».
- Guilds і Chapters забезпечують єдині стандарти архітектури, тестування, CI/CD і observability — без них автономія перетворюється на «зоопарк технологій»: кожна команда оптимізує локально, а система деградує глобально.
- Contract testing дозволяє змінювати сервіси, не ламаючи інших.
- Outcome-based метрики (Product OKR) синхронізують команди через результат, а не через задачі.
Ця модель має сенс у продуктах зі складним доменом і великою кількістю залежностей між командами. Її ціна — високі вимоги до інженерної зрілості: культури коду, автоматизації, code review і звички документувати рішення. Без цього вона просто не масштабується.
Міф про Spotify-модель
Spotify-модель давно стала індустріальним міфом. Сам Spotify описував її як snapshot, а не готовий фреймворк. Тому Squads, Tribes і Guilds варто сприймати як окремі ідеї, а не шаблон для копіювання.
Структура — це архітектурне рішення.
Кожна з цих моделей ламається передбачувано, і сигнали деградації багато в чому однакові — різниця радше в тому, де саме виникає тертя. Якщо знати ці сигнали заздалегідь, можна встигнути відреагувати до того, як система починає деградувати сама.
Перехід між моделями — завжди компроміс: менше централізованого контролю, більше відповідальності команд і вищі вимоги до процесів. Але якщо деградація ще не системна, дешевше посилити запобіжники в поточній структурі, ніж перебудовувати всю модель. Інакше проблема просто переміститься в інше місце.