Документація в QA є основою ефективного тестування програмного забезпечення, і найчастіше включає тест-плани, докладні описи тест-кейсів, звіти про помилки, матриці відстеження вимог та інші артефакти. Створення та підтримка найчастіше є трудомістким завданням і може спричинити помилки. На щастя, досягнення в галузі штучного інтелекту можуть сприяти перегляду процесів щодо документації, даючи змогу скоротити час, витрачений на рутинні та виснажливі завдання.
Далі, я розповім як саме сучасні LLM моделі та ШІ-асистенти можуть полегшити життя тестувальникам, покращити якість документації та дати можливість більше часу зосередитися безпосередньо на процесі тестування.
Проблема документування в QA
Ефективне тестування найчастіше включає ряд артефактів: тестові випадки з докладними кроками та очікуваними результатами, зрозумілі звіти про помилки з кроками відтворення, traceability матриці, плани тестування та багато іншого. Створення та підтримка цих документів найчастіше трудомісткий та одноманітний процес, оскільки тестувальникам часто доводиться знову і знову писати схожі тестові випадки або описи помилок. У міру масштабування проектів обсяг необхідної документації зростає, а терміни на ведення документації скорочуються, що може призвести до відставання від швидкого темпу розробки. Саме тому тестувальники час від часу замислюються, що вони можуть зробити ефективніше, щоб документація була актуальною і не забирала надто багато часу та ресурсів.
Генеративний ШІ як помічник із документації QA
Генеративні моделі ШІ, такі як ChatGPT, Gemini або LLaMA, мають передові можливості у створенні тексту на підставі prompts. Оскільки більша частина документації з контролю якості є текстовим описом, ці моделі, відповідно, підходять для цієї мети. Наразі тестувальники почали вже стрімко використовувати ChatGPT для різних завдань, від написання чернеток тестових випадків до резюмування обговорень у чаті у вигляді звітів про помилки. Нижче ми розглянемо кілька сфер документації та те, як інструменти ШІ допомагають у кожній з них.
Прискорення створення тестових випадків
Одне з найпоширеніших застосувань ШІ у сфері забезпечення якості, це автоматизація написання тестових випадків. Замість створення тестових випадків вручну тестувальник може використовуватися ChatGPT для автоматичного генерування їх описів. Наприклад, для вимоги «When a customer adds an item eligible for free shipping, a 'Free Shipping' badge should appear on cart, checkout, and confirmation pages», ChatGPT може згенерувати набір відповідних тестових випадків включаючи такі заголовки, як «Free Shipping Badge Non-Eligible Items» або «No Free Shipping Badge for Non-Eligible Items», кожен з яких, містить чіткі передумови, покрокові дії та очікувані результати. Важливо, що ChatGPT також може пропонувати граничні випадки та варіації, які людина може випустити з уваги. Наприклад, при запиті додаткових тестових сценаріїв, що виходять за рамки очевидних, він може запропонувати такі варіанти, як «Free Shipping re-evaluated after removing an item» або «Eligibility based on order total».
Аналогічно, тестувальники можуть використовувати prompts типу «Suggest five additional test cases for a payment gateway integration», і ChatGPT пропонує реалістичні ідеї, що розширюють тестове покриття. Цей творчий аспект мозкового штурму означає, що ШІ може виступати в ролі другого мозку, гарантуючи, що незвичайні умови або негативні сценарії не будуть забуті.
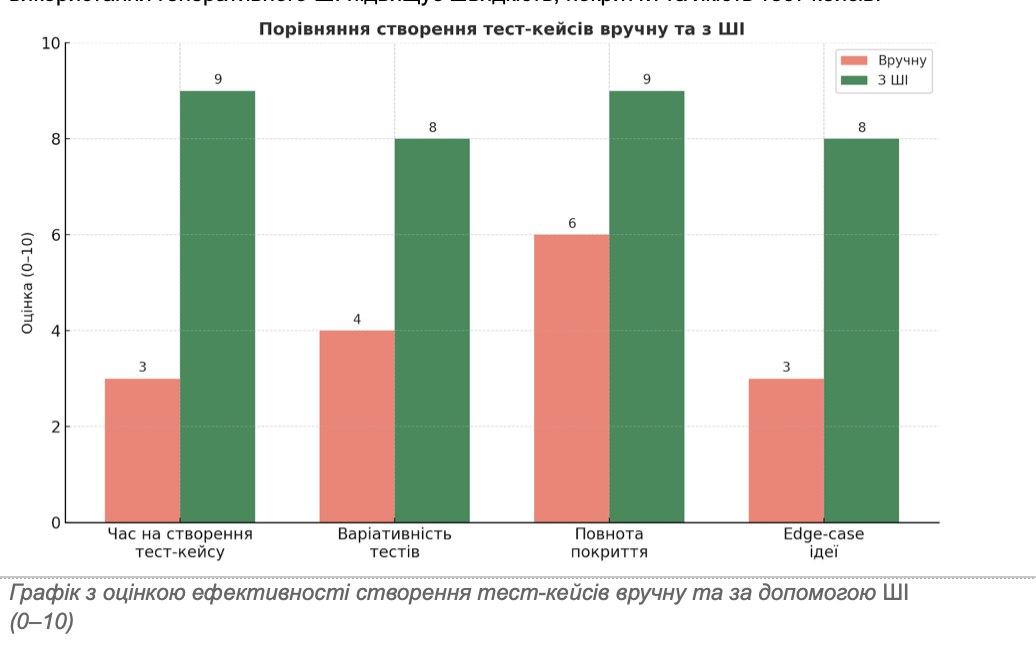
Звичайно, людський контроль залишається життєво важливим, тому що генеративні моделі іноді роблять припущення або включають деталі, відсутні в специфікаціях та вимогах. Наприклад, ChatGPT може сам вигадати вимогу, яка не була явно вказана, або використовувати плейсхолдерні значення, що вимагають коригування. Тому найчастіше тестувальники повинні перевіряти кожен запропонований ШІ тестовий випадок на релевантність та точність відповідно до фактичних вимог. На практиці тестувальники розглядають вихідні дані ШІ як чернетку або зразок для наслідування і коригують кроки, щоб вони відповідали точному інтерфейсу користувача. Цей етап перевірки усуває випадкові помилки, коли ШІ не розуміє предметну область. По суті, ChatGPT значно прискорює розробку тестового випадку, але тестувальник гарантує, що кожен випадок дійсно відповідає очікуванням продукту. Як показує графік нижче, використання генеративного ШІ підвищує швидкість, покриття та якість тест-кейсів.
Доопрацювання та перевірка документації
Крім створення нових тестових випадків, ШІ також може бути корисним для доопрацювання існуючої документації. Командам QA іноді доводиться перевіряти тестові випадки, написані іншими розробниками, на коректність та ясність. ChatGPT може виступати в ролі помічника перевіряючого, аналізуючи конкретний тестовий випадок і вказуючи на потенційні поліпшення або навіть недостатні деталі. Наприклад, тестувальник може надати приблизний тестовий випадок: «Check the application’s search feature. Steps: Open app, type query, press search.» і попросити ChatGPT перевірити його або навіть запропонувати поліпшення. ШІ своєю чергою може рекомендувати такі удосконалення: «Clarify the environment (web or mobile), specify expected results (e.g. List of matching items should appear), add a step for no-results scenario, and consider special character input handling». На мій погляд, це розумні покращення, які гарантують більш повний та однозначний тестовий випадок. Це схоже на наявність постійного рецензента для перевірки якості документації.
Аналогічним чином, ШІ може коригувати та стандартизувати документи контролю якості, виправляючи граматичні помилки або помилки форматування в описах дефектів, забезпечувати однаковість у кроках до відтворення і навіть пропонувати перефразувати заплутані речення для більшої ясності. Це призводить до створення більш якісної документації з меншими зусиллями за рахунок зниження кількості людських помилок та допомагає виявляти упущення чи невідповідність, підтримуючи високі стандарти документування у всій команді.
Звіти про помилки
Документування помилок також є частиною контролю якості, яку багато хто вважає стомлюючою. Інструменти ШІ можуть полегшити це завдання, автоматично перетворюючи необроблену інформацію про помилки або розмови в чатах на структуровані звіти про помилки. Для цього тестувальники можуть просто передати всю наявну інформацію про дефект у тому вигляді, в якому вона у них є і попросити ШІ сформувати дефект на підставі відповідного шаблону. ШІ своєю чергою підсумує ключові відомості про помилку, опише контекст та заповнить поля звіту про помилку, включаючи заголовок, кроки відтворення, очікувані та фактичні результати тощо.
Також важливо відзначити, що все ще потрібно перевіряти точність звітів про помилки які створюються за допомогою ШІ, оскільки модель може випадково неправильно витлумачити повідомлення про помилку або, наприклад, невірно припустити причину збою. Однак при розумному використанні ШІ, наприклад з використанням prompts, тестувальники витрачають менше часу на рутинну роботу над описом помилок і більше на їхнє вивчення.
Гарна ідея чи потенційна пастка?
Щоб об'єктивно оцінити роль ШІ розробці чи підтримці документації, варто подивитися на нього з обох боків як на інструмент, який справляється з рутиною і підвищує ефективність, так і на систему, яка не має контексту, гнучкості та аналітичного мислення. Нижче я постарався зробити порівняння сильних сторін та типових обмежень генеративних моделей у сфері QA-документації.
Що ШІ робить добре:
- Швидко генерує тест-кейси на основі вимог або user stories
- Прискорює написання документації, створення чернеток тестів, дефектів, звітів
- Пропонує додаткові edge cases і варіанти, які тестувальник міг би не врахувати
- Підтримує єдиний стиль оформлення, структуру тестів, заголовків, очікуваних результатів
- Автоматично виявляє помилки у формулюваннях або логічні неузгодженості
- Полегшує оновлення тестової документації при зміні вимог або API
- Підвищує продуктивність і знижує емоційне вигорання, позбавляючи рутини
У чому ШІ ще поступається людині
- Може вигадати неіснуючі вимоги або неправильні очікувані результати
- Погано розуміє доменно-специфічні особливості або складну бізнес-логіку
- Не може самостійно визначити пріоритетність тестів чи стратегічну важливість кейсів
- Без чіткого prompt або контексту генерує занадто загальні або нефокусні сценарії
- Потребує обов’язкової перевірки з боку людини
- Є ризик надмірної залежності. Наприклад навички тест-дизайну можуть поступово втрачатися без практики
- Потребує ресурсів (обчислювальних або фінансових) для стабільного використання та масштабування
Це порівняння допомагає краще зрозуміти, в яких саме сценаріях ШІ приносить найбільшу користь, а де все ще варто покладатися на людський досвід. Таке усвідомлення дозволяє формувати збалансовану стратегію впровадження ШІ з урахуванням його сильних сторін без втрати критичного мислення та розуміння контексту.
Що робити, коли в організації заборонено використовувати хмарні LLM?
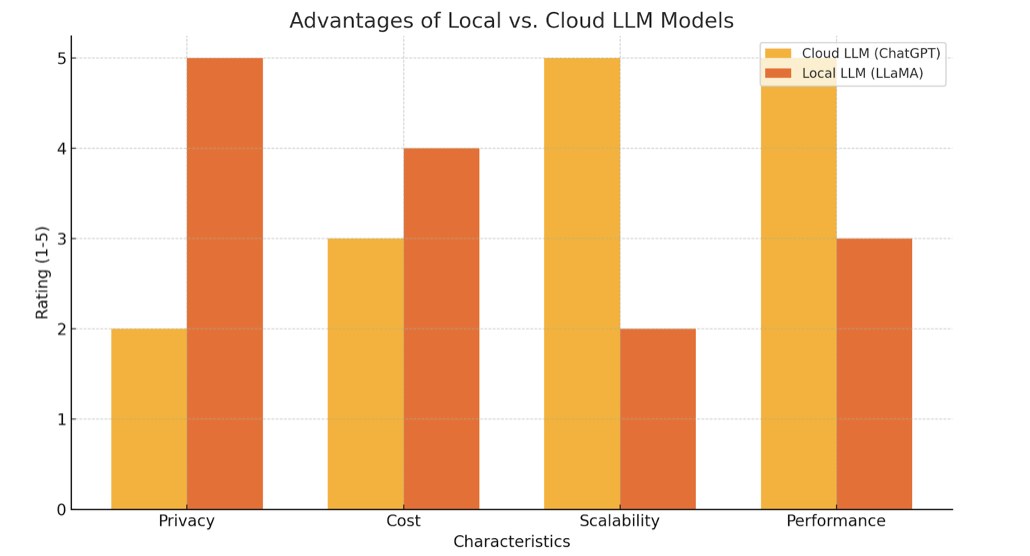
Попри всі переваги ChatGPT та аналогічних ШІ систем, багато компаній відчувають зрозумілі побоювання з приводу їх прямого використання, особливо в при контролі якості, де ви можете описувати невипущені функції, конфіденційні дані або навіть потенційні дефекти. Хмарні ШІ сервіси, такі як ChatGPT або Gemini, обробляють ваші запити на зовнішніх серверах, що порушує питання конфіденційності та безпеки даних.
Побоювання полягають у тому, що після надсилання даних зовнішньому ШІ, вони можуть бути збережені або навіть використані для навчання майбутніх моделей, і немає простого способу видалити ці дані. Для документації контролю якості, яка може містити конфіденційну інформацію про проєкт, це серйозний та обґрунтований ризик.
Програми LLM з відкритим вихідним кодом пропонують привабливе рішення для організацій, які потребують переваги ШІ, не втрачаючи контролю над даними. Такі моделі, як LLaMA від Meta, Gemma, Mistral та інші, можна завантажити та запустити локально або в віртуальній приватній хмарі. Завдяки цьому підходу вся обробка запитів відбувається локально, а конфіденційні дані ніколи не передаються стороннім сервісам, мінімізуючи ризики витоку важливої інформації.
Для команд QA це означає, що вони можуть використовувати ШІ для генерації тестових випадків або узагальнення інформації про помилки у внутрішній інфраструктурі. Ця модель добре підходить компаніям, які хочуть доопрацьовувати модель на основі своїх минулих тестових випадків, вимог та документації щодо продукту. У майбутньому ця модель могла б функціонувати аналогічно до ChatGPT, але виключно на серверах компанії. Тестувальники могли б безпечно вводити інформацію про нову функцію або вставляти журнали помилок для отримання чернеток звітів про помилки, впевнені, що ці дані не стануть загальнодоступними. Це розв’язує проблему витоку даних, що утримує багато команд від повного впровадження ШІ.
Запуск таких великих моделей вимагає значних обчислювальних ресурсів і апаратного забезпечення GPU, тому компаніям слід зважити вартість інфраструктури та переваги. У деяких випадках використання невеликих відкритих моделей може бути достатньо для створення базової тестової документації та роботи навіть на потужному ноутбуці або одному сервері.
Також варто відзначити рішення, де постачальники хмарних рішень для ШІ, пропонують корпоративні тарифні плани або локальні рішення, що гарантують конфіденційність даних. Наприклад, у OpenAI є версія ChatGPT Enterprise, в якій запити користувача не використовуються для навчання, а дані шифруються. Сервіс Microsoft Azure OpenAI дозволяє компаніям використовувати моделі OpenAI більш ізольовано. Ці варіанти, як і раніше, передбачають довіру до постачальника, але вирішують багато проблем конфіденційності.
Підсумовуючи, можна сказати, що локальні використання LLM, дозволяють командам контролю якості використовувати ШІ в конфіденційних проєктах, не передаючи свої дані третім особам. Інженери контролю якості можуть отримувати аналогічну допомогу в документуванні — швидку генерацію тестових сценаріїв, створення тестових планів та узагальнення помилок.
Підсумок
На практиці стає помітно, що штучний інтелект перетворює документування з необхідності, що стомлює, на більш автоматизований і інтелектуальний процес. Такі інструменти, як ChatGPT або Gemini демонструють, що вони можуть генерувати тестові сценарії, звіти про помилки та інші артефакти, необхідні для тестування, з достатньою якістю для початкових чернеток, які далі допрацьовуються спеціалістами.
Моделі з відкритим вихідним кодом, такі як LLaMA, дають ще більше можливостей і переваг на проєктах, де контроль даних має першорядне значення, гарантуючи, що навіть організації, що піклуються про безпеку, можуть використовувати ШІ, не побоюючись витоку даних. Також варто відзначити, що ШІ відмінно справляється з рутинними, чітко поставленими завданнями та пропонує креативні рішення, але йому не вистачає справжнього розуміння та контексту предметної галузі, які є у old-school тестувальників. ШІ може складати документи, але люди повинні їх перевіряти та залишати фідбек, щоб ШІ зміг зробити свою роботу краще наступного разу.
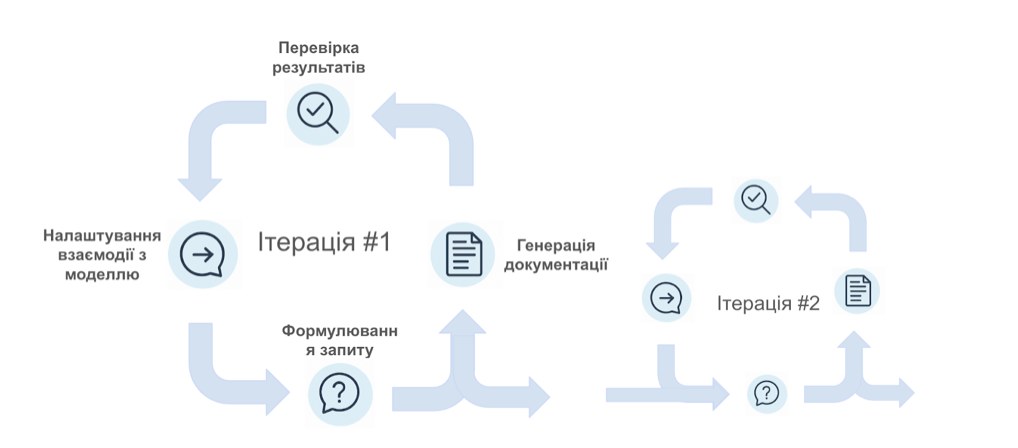
На практиці це виглядає як послідовність ітерацій:
На закінчення, «документація без рутини» стає реальністю для команд, що використовують ШІ. За умови належного контролю, використання ШІ може суттєво підвищити якість, забезпечуючи чіткість, повноту та швидкість. Рутина може зникнути, а значимість документації лише зросте завдяки мінімальним витратам на її створення та супровід. На мою думку, найефективнішими будуть ті команди, які знайдуть баланс: 80% рутинної роботи передадуть ШІ, а ухвалення технічних рішень залишать за людьми.