Відомо, що криптобіржі використовують моделі машинного навчання для відстеження підозрілої активності на платформі, щоб запобігти небажаним проблемам. Як же Binance використовує цей спосіб для захисту своєї екосистеми?
Команда штучного інтелекту для управління ризиками, що складається з інженерів по машинному навчанню та фахівців з даних, цілодобово працює над боротьбою з шахрайствами та захистом користувачів Binance. Для цього вони використовують рішення на основі ШІ, які можуть виявляти та реагувати на потенційні загрози, такі як шахрайство в однорангових мережах (P2P), крадіжка платіжних реквізитів і атаки із захопленням облікового запису та інші.
Отож, у даній статті розберемось, як команда з ризиків Binance використовує моделі машинного навчання для відстеження підозрілої активності на платформі.
Пакетна та потокова передача
Інженери з машинного навчання зазвичай використовують два типи конвеєрів: пакетний та потоковий. В обох є свої плюси та мінуси, залежно від ситуації.
Пакетні конвеєри обробляють дані, відповідно, пакетами. Інженери зазвичай використовують їх для обробки великих обсягів даних.
З іншого боку, потокові конвеєри обробляють дані в режимі реального часу в міру їхнього збору. Саме тому вони найбільше підходять для ситуацій, які потребують майже миттєвої відповіді. Наприклад, виявлення хакера до того, як він зможе вивести кошти з вкраденого рахунку.
Проте, обидва конвеєри однаково важливі. Поточні конвеєри відмінно підходять для надання відповідей у реальному часі, тоді як пакетні конвеєри краще підходять для обробки великих обсягів даних.
У разі запобігання шахрайству нам необхідно віддавати пріоритет даним у реальному часі, щоб уникнути ситуації, яка називається «застарілою моделлю», яка відноситься до застарілих чи неточних моделей машинного навчання.
Значення застою
Так само як люди можуть стати менш ефективними у виконанні завдання, якщо вони не будуть в курсі останньої інформації або методів, моделі машинного навчання можуть стати менш точними, якщо вони регулярно не оновлюються.
Саме тому ми використовуємо конвеєр потокової передачі, щоб гарантувати, що моделі запобігання шахрайству працюють із даними у реальному часі й здатні правильно позначати законні транзакції, як шахрайські та ідентифіковувати скомпрометовані облікові записи.
Розрахунок моделі захоплення облікового запису (ATO)
Для прикладу, розглянемо модель ATO, призначена для виявлення облікових записів, захоплених зловмисниками з недобрими намірами. Однією з характеристик, яку вимірює ця модель, є кількість транзакцій, здійснених конкретним клієнтом за останню хвилину.
Хакери, як правило, слідують послідовному шаблону, виконуючи велику кількість операцій, таких як зняття коштів протягом короткого періоду часу. Система має обчислити цю функцію якнайшвидше у разі потенційних загроз. Це означає мінімізацію затримок між тим, коли користувач чинить дію, і моментом, коли дані про активність цього користувача обробляються нашими моделями. Лише кілька секунд можуть стати різницею між зупинкою хакера та втратою користувачем усіх своїх грошей.
Роль пакетних обчислень
Важливість застаріння функцій може залежати від моделі або функції, що використовується. У випадку ATO, згаданому вище, також необхідно отримати дані про зняття коштів користувачем за останні 30 днів, щоб розрахувати коефіцієнт на основі їх останніх транзакцій.
У цьому випадку пакетні обчислення протягом більш тривалих періодів часу, наприклад, щоденних або годинних інтервалів, допустимі, попри вищий ступінь застаріння в результаті очікування надходження даних до сховищ даних і періодичного виконання пакетних завдань.
Баланс між свіжістю та затримкою
Зрештою, вибір між пакетним і потоковим конвеєрами слід робити на основі конкретних вимог варіанта використання та функцій, що розглядаються. Ретельний облік цих факторів дає змогу створювати ефективні системи запобігання шахрайству, які захищають наших користувачів.
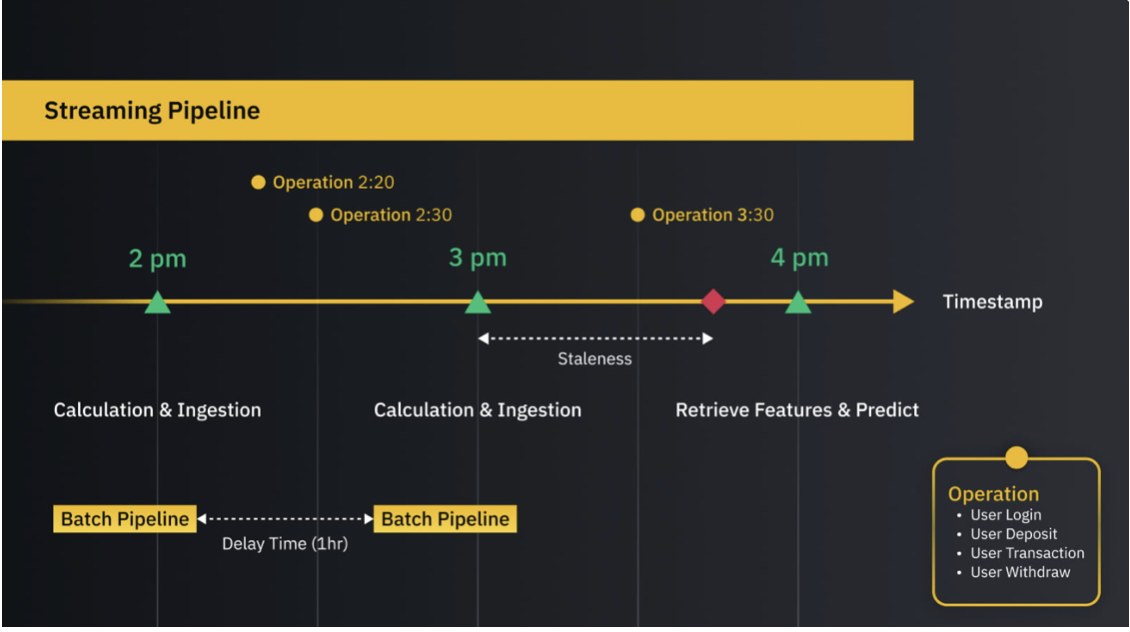
Використання конвеєра потокової передачі дозволяє нам віддавати пріоритет свіжості, а не затримці для функцій, чутливих до часу. Діаграма вище ілюструє цю необхідність, оскільки кількість операцій для отримання ознак має дорівнювати трьом, а не двом.
Ось чому конвеєр машинного навчання у реальному часі має вирішальне значення для повсякденних операцій нашої групи управління ризиками.
Руйнування конвеєра потокової передачі
Машинне навчання в реальному часі для команди Binance Risk AI в основному складається з двох частин:
- Обробка даних (верхня частина діаграми).
- Обслуговування даних (нижня частина діаграми).
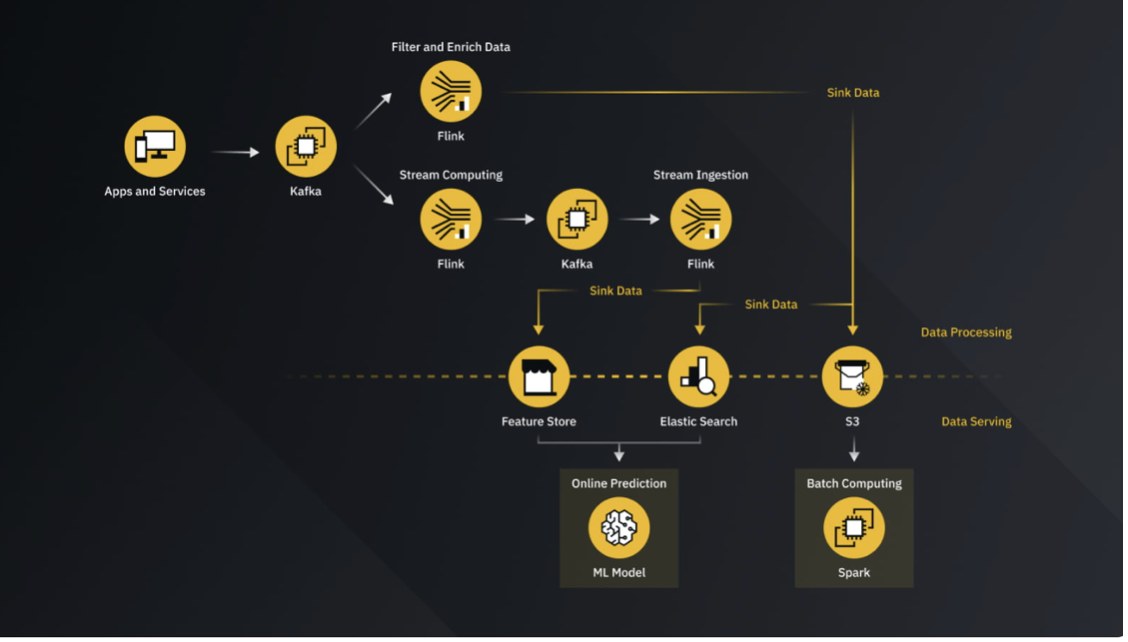
Обробка даних
Що стосується обробки даних, ми можемо розділити наш конвеєр потокової передачі (Flink Job) на три категорії в залежності від їх обов’язків:
- Поточні обчислення: розробка функцій.
- Поточне додавання: додавання функцій.
- Потокове занурення: збагачення даних.
Поточні обчислення
Компонент потокових обчислень конвеєра відповідає за проєктування ознак майже реальному часі, процес вилучення ознак з необроблених даних.
Він попередньо обчислює функції, які наші моделі машинного навчання використовуватимуть для онлайн-прогнозування. Є два типи методів обчислень для конвеєра потокових обчислень: на основі часу та на основі подій.
- Заснований на часі. Підрахунок кількості транзакцій кожні 10 хвилин. Це призводить до деякого старіння, але знижує затримку.
- Заснований на подіях. Обчислення ознак на основі події, що прибуває. Це знижує старіння, але трохи збільшує затримку.
Бажано не використовувати якнайбільше обчислень у реальному часі, і ось чому:
- Існує компроміс між затримкою та старінням. Обчислення функцій з надходженням онлайн-запитів обмежує обчислювальну логіку спрощеними підходами. Хоча цей метод знижує старіння, обчислення ознак збільшує затримку прогнозування.
- Незалежне масштабування є складним завданням, оскільки служби прогнозування та обчислень залежать одна від одної.
- Обчислення за запитом, що базуються на трафіку запитів, створюють непередбачуваний тиск масштабування.
- Обчислення в реальному часі не адаптуються до наших рішень з моніторингу моделей (перекіс навчання) та моніторингу функцій, оскільки функції не зберігаються у центральній базі даних, тобто у сховищі функцій.
Потокове поглинання
Компонент прийому потоку відповідає за прийом функцій у наше сховище функцій практично в реальному часі із платформи машинного навчання Kafka. Сховища функцій — це централізовані бази даних, у яких зберігаються функції, що часто використовуються.
Потік сток
Компонент приймача потоку в основному відповідає за передачу подій у реальному часі у певне місце призначення, наприклад, у високорозподілені файлові системи (HDFS), такі як S3, або інші зовнішні бази даних, такі як ElasticSearch, залежно від вимог проєкту.
Для команди штучного інтелекту ризику Binance зазвичай існує два шаблони збагачення даних, які можна застосувати до даних у реальному часі в Kafka в залежності від варіанта використання:
- Статичні дані. Наприклад, отримання списку популярних виробників, що сидять у S3 для бізнес-проєктів, пов’язаних із P2P, у завданнях Flink. Довідкові дані є статичними й вимагають оновлення лише рідше одного разу на місяць.
- Динамічні дані Обмінні курси в режимі реального часу (BTC до USD), наприклад, виходять із зовнішніх баз даних, таких як Redis. Пошук кожного запису забезпечує низьку затримку і високу точність при зміні еталонних даних.
Обслуговування даних
Компонент конвеєра, який обслуговує дані, відповідає за онлайн-прогнозування та пакетні обчислення.
Онлайн передбачення. Це відбувається коли запити надходять через Decision Hub (внутрішній механізм правил нашої групи управління ризиками). Потім відповідний сервіс викликає сховище функцій, щоб отримати функції та відправити їх у модель машинного навчання для оцінки. Наша команда Risk AI має понад 20 моделей машинного навчання, розроблених для задоволення різноманітних бізнес-вимог.
Пакетні обчислення. Хоча він може призвести до затримки до кількох днів, він відіграє важливу роль, оскільки доповнює функції, що обчислюються в реальному часі.
На завершення, важливо відзначити, що ринок криптовалют працює цілодобово і без вихідних, на відміну від традиційних фінансових ринків, які мають час відкриття та закриття. Кожну секунду відбувається безперервний приплив нових даних (зняття коштів, депозити, угоди тощо), що вимагає від бірж бути у пошуку зловмисників, які намагаються вкрасти власні засоби або особисту інформацію.