Кожна новостворена система нестабільна. Змиритися не можна чи все ж таки? Згадайте перші літаки — вони були ненадійними й у результаті непередбачуваними. У 1903 році брати Райти підняли свій літак у повітря приблизно на 12 секунд. У 1908 році один із демонстраційних польотів завершився смертю пасажира. На початку 20 століття аварії були звичним явищем. Але все змінилось, і слава Богу.
Мені б і хотілося розкрити тему, як помилки можуть робити систему кращою. Точніше закцентувати на тому, що саме системний підхід в опрацюванні цих недоліків — і відіграє ключову роль. Не достатньо просто пофіксити одну проблему один раз, бо вона рано чи пізно може вилізти знову. А от системність в опрацюванні якраз і може вивести вашу систему в ту саму, яка буде працювати без збоїв. Ділюсь порадами та деталями з власного досвіду помилок і напрацювань. Маю досвід понад 10 років у розробці, разом зі своєю командою Hillel IT School розробив десятки застосунків, серед яких й Hillel LMS, яка обслуговує 75 000 користувачів. І так, злетіти одразу і так щоб високо, стабільно і без помилок виходить не одразу й точно не успішно на всі 100%. Але давайте все ж таки розберемось, що може працювати на ваш результат.

Х’юстон, політ нормальний ….не завжди й не одразу
Літаки зазнавали катастроф через усе: пориви вітру, слабкі матеріали, прорахунки в аеродинаміці, людський фактор. Кожна катастрофа ставала болючим, але необхідним уроком. Інженери не просто «латали» поломки — вони переглядали підхід: змінювали матеріали, тестували конструкції, створювали тренажери для пілотів, стандартизували протоколи безпеки. Минуло сто років, і сьогодні авіаперевезення — один із найнадійніших видів транспорту. Рівень смертності в авіакатастрофах знизився з понад 6 інцидентів на 100 000 польотів у 1970-х до менше ніж 0.06 сьогодні. Це не випадковість — це наслідок системного підходу: виявлення, аналізу, усунення та запобігання помилкам.
І тут головне: виправити проблему — недостатньо. Справжня стабільність приходить лише тоді, коли ви не просто «полагодили» проблему, а й зрозуміли її причину, і змінили підхід так, щоб вона ніколи не повторилася.
Те саме стосується й вашого застосунку. Коли ви вперше запускаєте його — це як літак на першому польоті.
Ви ще не знаєте, де він зламається, але він зламається
Питання не в тому, чи буде баг, а як ви на нього відреагуєте. У хорошій команді програмісти не просто «фіксять баг». Вони аналізують причину, додають автоматичні тести, змінюють процес розробки, і вже наступного разу ця сама помилка не має шансів повторитися. Так створюється стабільна система. Це як в авіації: кожна аварія, це інвестиція в безпеку в майбутньому. І як би парадоксально це не звучало: чим більше помилок ви зустріли та правильно обробили, тим надійнішою стає ваша система.
Щоб забезпечити стабільність і передбачуваність у роботі додатка, сучасні команди впроваджують багаторівневу систему тестування, яка охоплює як окремі частини системи, так і її поведінку в цілому.
Основні типи тестування
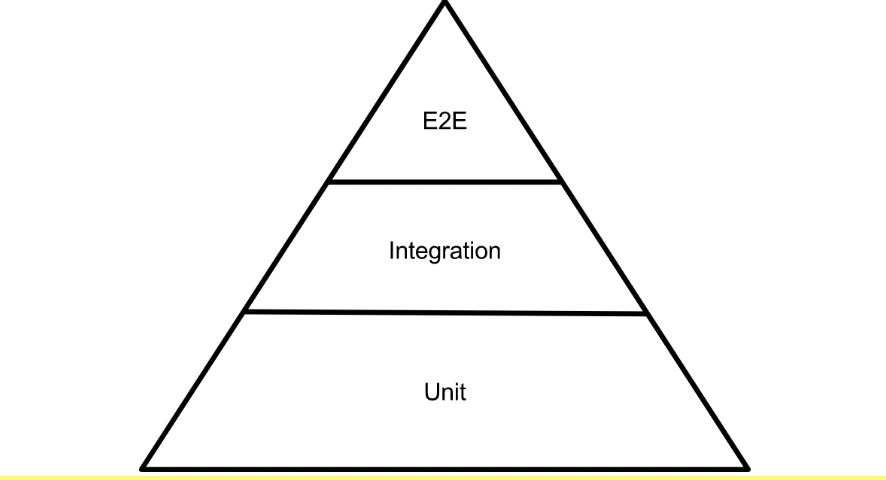
- Юніт-тести (Unit tests) — перевіряють роботу окремих функцій або методів у відриві від решти системи. Їх мета — гарантувати коректність елементарних одиниць логіки.
- Інтеграційні тести (Integration tests) — перевіряють взаємодію між модулями, наприклад, між контролером і сервісом, або між сервісом і базою даних.
- Енд-ту-енд тести (End-to-End tests) — моделюють повну поведінку користувача через інтерфейс (UI або API), перевіряючи, чи всі компоненти системи працюють разом як очікується.
- Регресійні тести (Regression tests) — допомагають переконатися, що нові зміни не зламали вже стабільний функціонал.
- Тести продуктивності (Performance / Load testing) — виявляють вузькі місця при високих навантаженнях, перевіряють реакцію системи на велике число запитів або великий обсяг даних.
- Тестування безпеки — включає перевірки на типові вразливості, такі як SQL-ін’єкції, XSS, CSRF тощо.
Крім самих тестів, ключову роль у стабільності відіграють
- CI/CD-процеси — кожна зміна коду автоматично проходить тести в ізольованому середовищі перед потраплянням у production. Це мінімізує людський фактор і пришвидшує виявлення помилок.
- Моніторинг та алертинг — інструменти на кшталт Sentry або Datadog відстежують помилки, метрики й інциденти в реальному часі, дозволяючи оперативно реагувати на проблеми.
- Code review і статичний аналіз коду — запобігають появі помилок ще на етапі написання, покращують якість і зрозумілість коду.
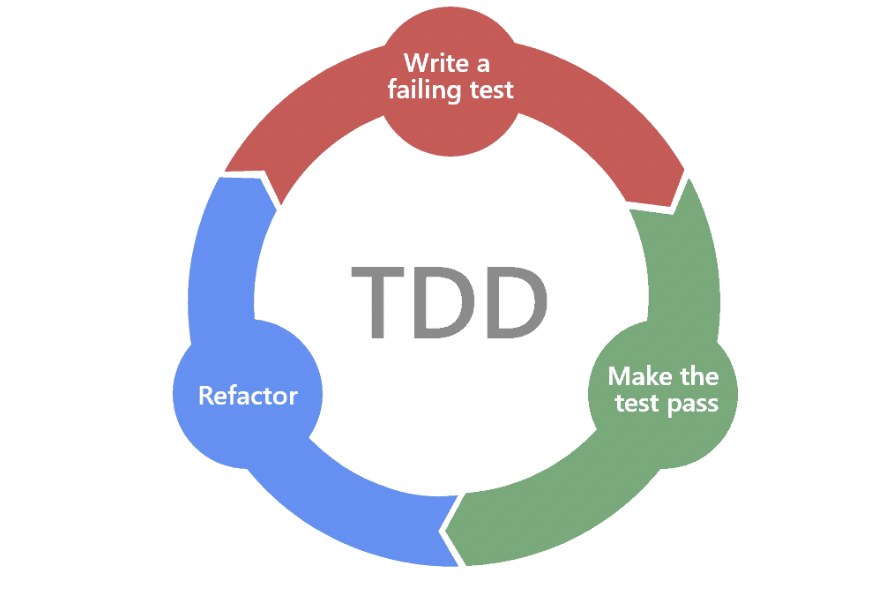
TDD — розробка, керована тестами. Один із найефективніших методів створення стабільного ПЗ — Test-Driven Development (TDD). Це підхід, коли тест пишеться до самої реалізації логіки. Процес має три етапи:
- Red — написати тест, який провалюється.
- Green — реалізувати мінімальний код, щоб пройти тест.
- Refactor — оптимізувати код без зміни поведінки.
TDD має безпосередній вплив на стабільність
- Легко перевірити наслідки змін — будь-яке оновлення автоматично перевіряється на порушення попередньої поведінки.
- Ясне розуміння вимог — це змушує краще осмислити, що саме має робити функція, ще до її реалізації.
- Раннє виявлення помилок — Більшість багів виявляється на етапі написання коду, а не в продакшені.
TDD — це про контроль. Це спосіб зробити розробку передбачуваною, масштабованою і стабільною в довгостроковій перспективі.
Висновок. Стабільність — це не властивість системи, це результат дисципліни, практики та процесів. Вона не з’являється автоматично, але формується через:
- вчасно виявлені баги;
- системний аналіз причин;
- автоматичні перевірки;
- постійне вдосконалення процесів.