Великі мовні моделі (Large Language Models, LLMs) є значним кроком уперед у розвитку штучного інтелекту, особливо в галузі обробки природної мови (Natural Language Processing, NLP). Вони розроблені для розуміння, генерування та маніпулювання людською мовою надзвичайно точно. В основі LLM лежать архітектури глибокого навчання, часто з використанням моделей-трансформерів, які дають змогу їм обробляти величезні обсяги текстових даних і вивчати складні мовні закономірності.
Сьогодні у світі є чимало великих мовних моделей від компаній на кшталт Anthropic чи OpenAI, які пропонують високу точність і продуктивність за відносно доступними цінами. Однак ключовою проблемою залишається питання безпеки даних: як і для чого ці компанії можуть використовувати вашу інформацію? У ситуаціях, коли конфіденційність є пріоритетом, я рекомендую розгортати open-source LLM локально.
Чому варто використовувати open-source LLM
Локальне розгортання LLM відкриває перед компаніями нові горизонти, долаючи численні обмеження, властиві хмарним сервісам. Однією з найпомітніших переваг є підвищення конфіденційності: інформація залишається «вдома» і під надійним захистом. Це може мати вирішальне значення для галузей, які працюють із чутливою інформацією, таких як охорона здоров’я, фінанси та юридичні послуги.
Проте на цьому переваги не закінчуються. Локальне розгортання дає свободу в управлінні даними та дає змогу гнучко налаштовувати моделі під специфічні потреби організації. Це відкриває шлях до створення справді індивідуалізованих рішень, адаптованих до унікальних викликів і стратегій. На відміну від хмарних платформ, орієнтованих на узагальнені сценарії, локальні моделі надають компаніям можливість перетворити LLM на інструмент, який гармонійно поєднується з їхнім баченням і бізнес-цілями. Локальна система відкриває простір для дій та гнучкості для точного налаштування, ніж масштабні хмарні сервіси. Це рішення для тих, хто розуміє: справжня стратегічна перевага полягає не в універсальності, а в точній адаптації до конкретних потреб.
Локальне розгортання LLM дає розробникам змогу експериментувати з ідеями швидше й економніше, зменшуючи витрати на створення прототипів. Інтеграція з локальними API, сумісними з OpenAI, забезпечує плавну роботу системи та зберігає гнучкість для майбутнього переходу на моделі, такі як GPT. Це дає змогу не лише залишатися адаптивними до змін, але й досягати максимальної відповідності завданням і контексту.
Як обрати open-source LLM
Протягом останніх років з’явилося багато різноманітних бенчмарків для LLM. Вони порівнюють продуктивність моделей на різних наборах даних і завданнях, що дає змогу обрати оптимальну модель для вашого бізнес-кейсу.
Я віддаю перевагу HuggingFace LLM Leaderboard. Якщо вам цікаво, на яких наборах даних тестувалася модель, ви можете переглянути інформацію за посиланням. На основі цього можна обрати найкращу модель для своїх потреб.
Після вибору потрібної LLM ви можете використовувати різні інструменти для її локального запуску. У цій статті ми зосередимо увагу на таких інструментах, як Ollama і LMStudio.
Ваш ідеальний сетап або як вибрати апаратне забезпечення
У мене є два ноутбуки: Dell Latitude 5511 для роботи та MacBook M1 Pro для особистого використання. Локальний запуск LLM вимагає ретельного врахування можливостей апаратного забезпечення. Dell Latitude 5511 з процесором Intel i7-10850H і 16 ГБ оперативної пам’яті добре підходить для легких завдань, що залежать від процесора, але йому не вистачає виділеного GPU для прискореної обробки. MacBook Pro (M1 Pro), також з 16 ГБ уніфікованої пам’яті, використовує інтегрований Neural Engine і GPU для ефективної роботи з моделями середнього розміру, такими як LLaMA-2-7B. Latitude підходить для простіших завдань, тоді як M1 Pro відзначається ефективністю та продуктивністю, що робить його кращим вибором для тривалих навантажень. Крім того, є різні методи, які дозволяють запускати більші моделі з меншою обчислювальною потужністю, про що поговоримо пізніше.
Для моделей, які я тестував на ноутбуці Dell, відповідь генерувалася до 3 хвилин, тоді як Mac справлявся за секунди. Тому варто враховувати апаратні обмеження, вибираючи найкращу модель для локального запуску. У ШІ-спільнотах після виходу mac mini m4 почався прямо бум: багато хто почав використовувати його для деплою локальних LLM, порівнюючи перфоманс своїх ноутів.
Оптимальні параметри моделі
Зазвичай моделі доступні з різною кількістю параметрів:
1. Моделі з 1 мільярдом параметрів
- Розмір: ~1 мільярд параметрів.
- Продуктивність: низька та підходить для загальних завдань, таких як генерація тексту, базове логічне мислення та робота з меншими наборами даних.
- Вимоги до обладнання: мінімальні; можуть ефективно працювати на системах із 16 ГБ оперативної пам’яті, таких як Dell Latitude 5511, використовуючи інструменти для інференції на базі процесора, наприклад, llama.cpp.
- Сценарій використання: Ідеально підходить для середовищ з обмеженими ресурсами або додатків, які потребують швидкої відповіді з мінімальними обчислювальними витратами.
2. Моделі із 7 мільярдами параметрів
- Розмір: ~7 мільярдів параметрів.
- Продуктивність: Значно краще розуміють контекст, логічне мислення та справляються зі складними завданнями.
- Вимоги до обладнання: помірні; отримують переваги від оптимізованого обладнання, такого як уніфікована пам’ять або Neural Engine Mac M1 Pro.
- Сценарій використання: Підходить для додатків, що потребують більшої точності та розуміння контексту без необхідності використання великих обчислювальних потужностей.
3. Моделі з 32 мільярдами параметрів
- Розмір: ~32 мільярди параметрів.
- Продуктивність: Надзвичайно просунута, пропонує передові можливості у логічному мисленні, детальній генерації тексту та мультимодальних завданнях (за наявності підтримки). Мультимодальність — здатність однієї моделі генерувати та розуміти різні типи даних, наприклад текст та зображення
- Вимоги до обладнання: високі; вимагають потужних GPU або систем із понад 32 ГБ оперативної пам’яті та оптимізованих фреймворків, таких як ONNX, TensorRT або CoreML, для інференції.
- Сценарій використання: Найкраще підходить для високоточних корпоративних додатків, наукових проєктів або роботи з великими, складними наборами даних.
Як обрати?
- Обирайте моделі з 1 мільярдом параметрів для легких завдань або коли апаратні ресурси обмежені.
- Для балансу між продуктивністю та вимогами до обладнання, наприклад, для детального логічного мислення або завдань середньої складності, вибирайте моделі із 7 мільярдами параметрів.
- Використовуйте моделі з 32 мільярдами параметрів лише тоді, коли маєте достатню обчислювальну потужність і потребуєте передової продуктивності для складних навантажень, таких як дослідження у сфері ШІ, масштабні завдання NLP або корпоративні рішення.
- Також ви можете перевірити різницю в точності між однаковими моделями з різною кількістю параметрів. Наприклад:
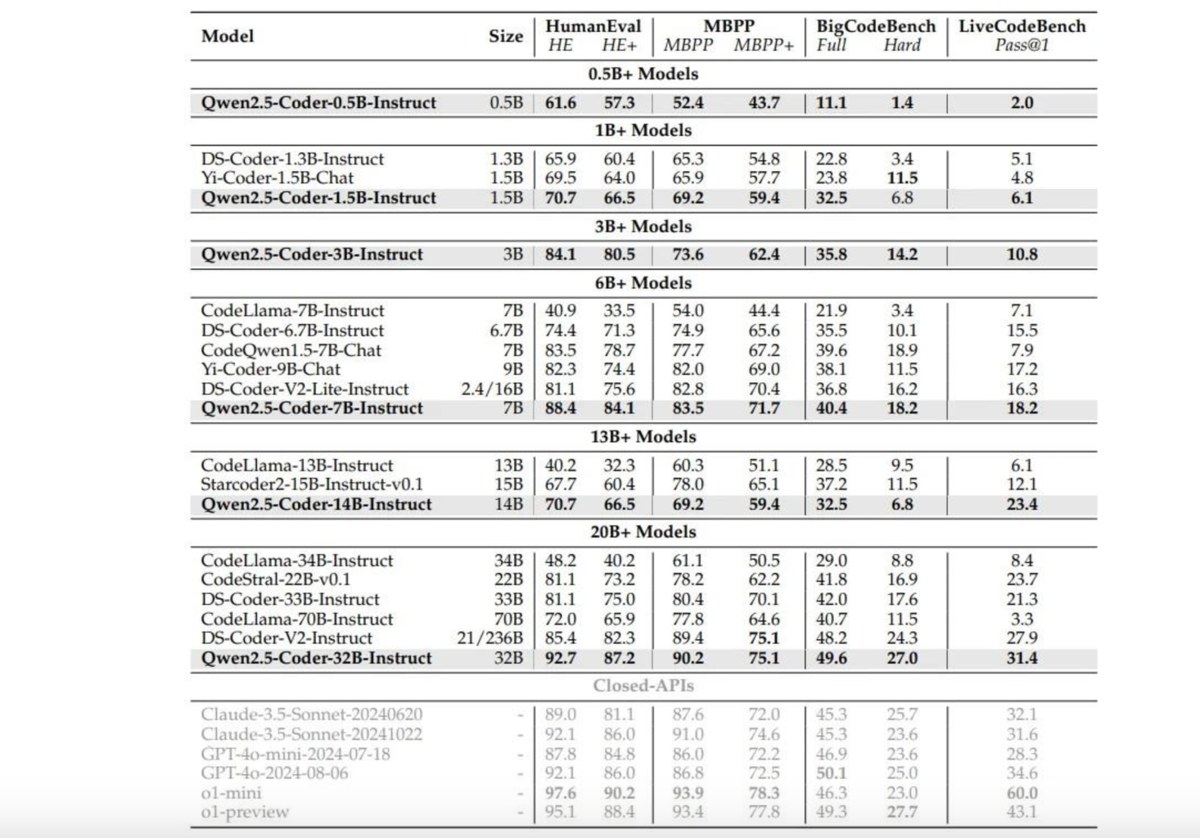
Ми можемо побачити, що Qwen2.5-Coder із 32 млрд параметрів працює значно краще, ніж його версії з 7 млрд та 1 млрд параметрів.
Для мене на моїх ноутбуках оптимальними були моделі з 7 млрд параметрів.
Техніки квантизації для оптимізації локального запуску LLM
Квантизація дозволяє використовувати потужність LLM навіть там, де апаратні ресурси далекі від ідеальних. Завдяки цій техніці модель стає компактнішою, швидшою й водночас зберігає точність, яка задовольняє більшість завдань.
Зі зростанням розміру та складності моделей вимоги до пам’яті та обчислювальної потужності можуть здаватися непосильними для локальних середовищ. Тут і вступає в гру квантизація: параметри моделі переводяться з 32-бітної плаваючої точки у 16-бітні чи навіть 8-бітні цілі числа. Це суттєво скорочує обсяг даних і прискорює обробку, дозволяючи використовувати модель у ресурсозатратних середовищах без серйозних компромісів.
По суті, квантизація — це спосіб навчити модель працювати «легше», не жертвуючи її функціональністю. Вона робить складні LLM доступними для локального запуску, перетворюючи навіть обмежену інфраструктуру на повноцінний інструмент для роботи з найсучаснішими технологіями.
Попри переваги, квантизація несе і свої виклики. Одним з основних компромісів є можливість втрати точності моделі, особливо в завданнях, що потребують високої точності. Рівень втрати точності залежить від архітектури моделі та конкретного методу квантизації. Зі зростанням попиту на локальний запуск LLM опанування квантизації стане ключовою навичкою для розробників, які прагнуть максимально використати потенціал цих потужних моделей у різноманітних і ресурсно обмежених середовищах.
Ви можете знайти квантовані версії різних моделей на HuggingFace. Також квантовані версії доступні на Ollama і LMStudio (вони використовують HuggingFace як постачальника моделей). Завдяки квантизації ви навіть можете використовувати деякі моделі з 32 мільярдами параметрів на своєму локальному ноутбуці (у мене це працювало з Qwen2.5-coder).
Будьте уважні: якщо ви використовуєте бібліотеку transormers і хочете використати квантовану модель, вам необхідно оновити код і спілкуватися з моделлю використовуючи llama-cpp.
Встановлення:
```bash
sudo apt install ninja-build
pip install llama-cpp-python
```

Introduction to Ollama
Ви можете завантажити Ollama з її офіційного сайту.
Також є список доступних моделей:
Ви можете знайти найкращу модель для себе саме там. Моделі з різною кількістю параметрів і квантовані версії також доступні. У документації ви знайдете багато функціональних можливостей, але тут варто виділити два ключові варіанти:
1. Локальний чат із моделлю
```bash
ollama run llama3.2:1b
```
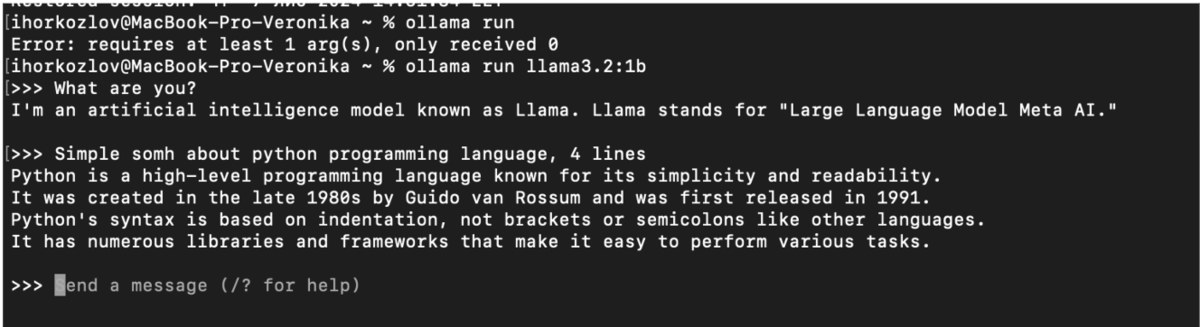
Як бачите, можна обрати модель та кількість параметрів.
2. Запуск локального сервера з ендпоінтами, подібними до OpenAI:
```bash
ollama serve
#Приклад використання через API, подібний до OpenAI:
curl http://localhost:11434/v1/chat/completions \
-H «Content-Type: application/json» \
-d '{
«model»: «llama3.2:1b»,
«messages»: [
{
«role»: «system»,
«content»: «You are a helpful assistant.»
},
{
«role»: «user»,
«content»: «Hello!»
}
]
}'
```
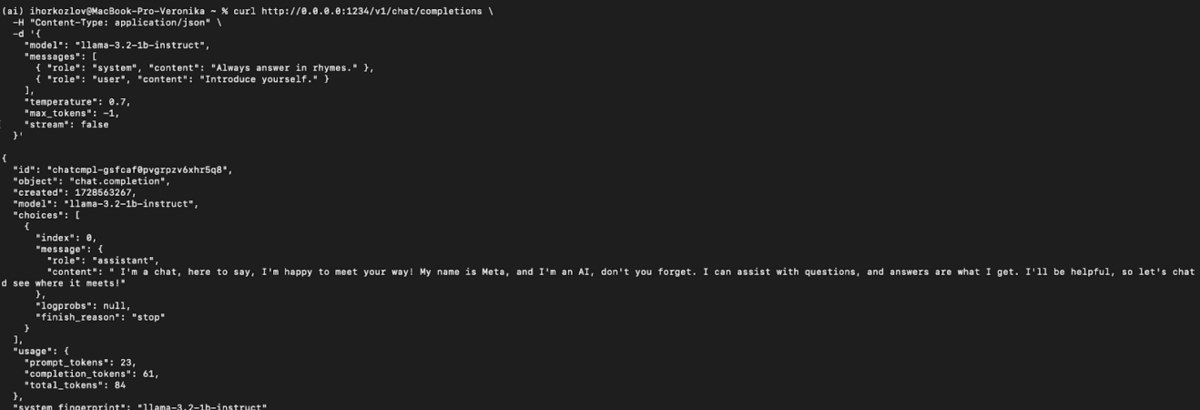
І ви можете використовувати його безпосередньо з клієнтами OpenAI у своїх додатках.
Не забудьте виконати цю команду, щоб звільнити ресурси:
```bash
ollama stop <model>
```
Як підсумок, Ollama відіграє ключову роль у локальному розгортанні LLM, адже спрощує процес встановлення, налаштування й управління.
LMstudio
LMStudio пропонує розробникам зручне середовище для роботи з LLM: від налаштувань і конфігурації до інтеграції RAG (Retrieval Augmented Generation). Але це лише частина його функцій.
Завантажити LMStudio можна за адресою lmstudio.ai. Хоча це ще не фінальна версія, інструмент уже помітно полегшує процес локальної розробки.
Як і Ollama, LMStudio дає змогу запустити локальний сервер для роботи з LLM або поділитися ним у локальній мережі. Усе це супроводжується інтерфейсом, який надає детальну інформацію про використання ресурсів і дозволяє гнучко підлаштовувати модель під ваші задачі.
Налаштування локального сервера
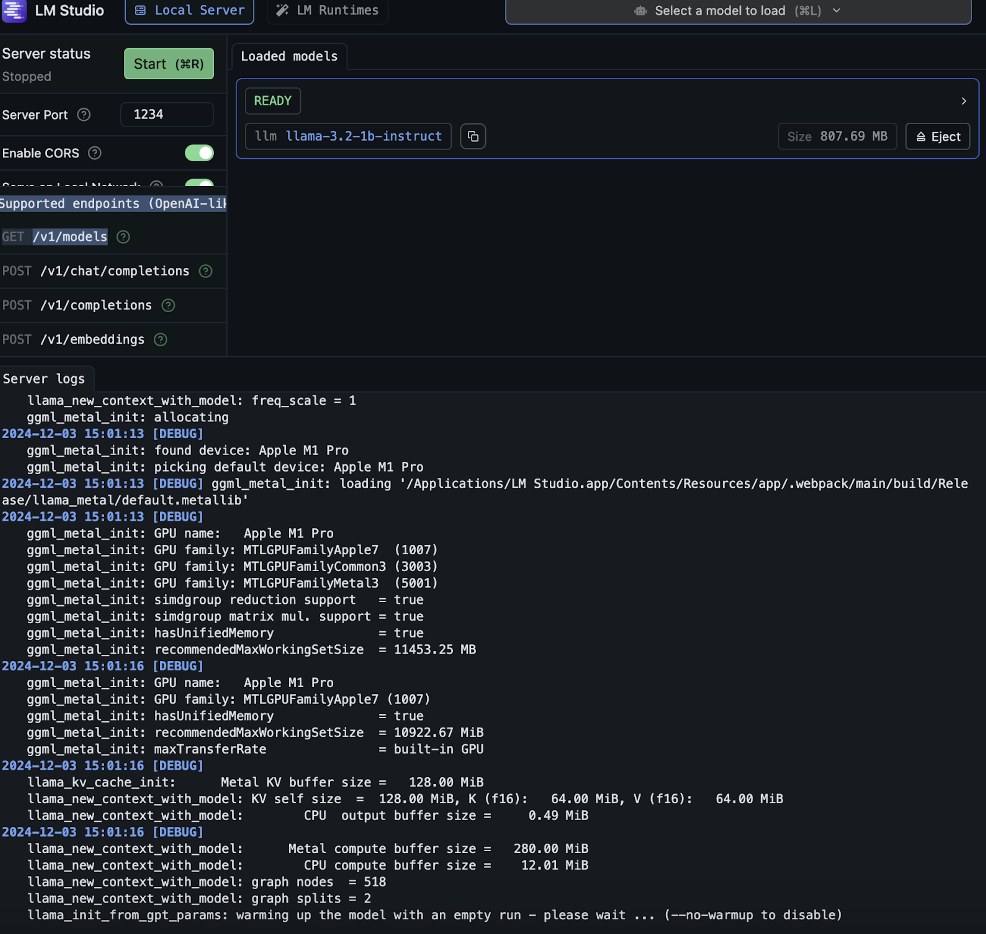
Ви також можете завантажити свій документ і запитати про нього LLM. Інтерфейс чату наразі підтримує формати PDF, DOCX, TXT та CSV. Ви можете безпосередньо налаштувати prompt в інтерфейсі чату та побачити, як LLM змінює відповіді залежно від нього.
Як бачите, система надає детальний журнал подій прямо в інтерфейсі чату (за умови активації). Також, залежно від розміру документа, LMStudio обирає: розмістити його безпосередньо в контексті (ідеально для моделей з великою довжиною контексту, long context models) або створити RAG-додаток.
LMStudio — це комплексний інструмент, який значно спрощує процес локального розгортання великих мовних моделей. Завдяки сумісному з OpenAI API, можливості серверного розгортання та зручному інтерфейсу, він стає привабливим вибором для розробників.
Підсумки та можливості
Розгортання великих мовних моделей локально відкриває перспективні можливості для розробників та організацій, дозволяючи використовувати потужність сучасного штучного інтелекту з одночасним забезпеченням контролю над конфіденційністю даних, гнучким налаштуванням та ефективністю. У цій статті ми розглянули основні інструменти й техніки, необхідні для успішного локального розгортання, зокрема використання Ollama та LMStudio з різними параметрами та методами квантизації. Ці інструменти спрощують процес, дозволяючи оптимізувати продуктивність моделей і безперешкодно інтегрувати їх у вже наявні системи.
Вибір відкритих LLM має базуватися на оцінюванні таких критеріїв, як розмір моделі, продуктивність, підтримка спільноти та сумісність із наявною інфраструктурою. Наприклад, у моєму випадку LLM розгорнута на MacBook і використовується зі свого робочого Dell через локальну мережу. Такий підхід не лише звільняє обчислювальні ресурси, але й додає гнучкості в розробці.
Переваги локального розгортання виходять далеко за межі технічних аспектів. Воно забезпечує вищий рівень конфіденційності та дозволяє працювати в офлайн-режимі, що особливо важливо для галузей, які мають справу з чутливими даними. Крім того, адаптація моделей під конкретні завдання дає змогу створювати індивідуальні рішення, які відповідають цілям організації та реальним потребам користувачів.
Дотримуючись стратегій і найкращих практик, описаних у цій статті, розробники можуть впевнено долати складнощі локального розгортання та використовувати потенціал LLM у своїй роботі.