У сучасному спортивному цифровому медіа-ландшафті наявність життєздатного продукту залежить від здатності надавати дані в режимі реального часу, гарантуючи, що користувачі залишаються залученими та поінформованими. Передача даних про спортивні події у режимі реального часу є основою залучення користувачів. Приміром, щодня сотні мільйонів людей стежать за футбольними подіями он-лайн.
У цій публікації блогу розглядаються технічні процеси, пов’язані з інтеграцією та відображенням даних про футбольні матчі у реальному часі в мобільних або веб-застосунках на tribuna.com.
Розклад матчів
Уявімо, що сьогодні Matchday. І якщо ви любитель футболу, або просто стежите за своєю командою, перше, що вам цікаво, це розклад матчів — календар команди. Отже, як це формується?
Підтримувати актуальний календар для кожної команди вручну було б не такою чудовою ідеєю, оскільки ми надаємо дані про поточні матчі понад 1000 футбольних змагань на всіх континентах. Для цього ми співпрацюємо із постачальником спортивних даних Perform (наразі це єдиний наш партнер, але плануємо співпрацювати з більшою кількістю — у тому числі за межами футболу), який надає API для всіх видів спортивної статистики, а також WebSockets для live streaming data.
Повернемося до розкладу матчів. Те, що ви бачите, відкриваючи сторінку з календарем, формується з даних, які ми зібрали та підготували заздалегідь. Точніше, розклад матчів на поточний is polled daily для всіх змагань, що є у нашій базі даних. Це допомагає нам бути в курсі подій у разі перенесення або скасування матчів.
Уявіть, щодня у світі на професійному рівні грають сотні матчів и десятках країн на всіх континентах. Інформація про ці футбольні події є у нас.
Live матч
Тепер давайте обговоримо випадок, коли ви хочете подивитися, що відбувається в грі (або навіть кількох іграх одночасно). Якщо ви прихильник футбол вас поза усіляких сумнівів цікавить: який рахунок, хто забив, отримав жовту картку, асистував тощо.
Коли ви відкриваєте сторінку матчу під час гри, ви бачите багато даних — усі основні події в матчі, позиції в таблиці ліги, історію матчів суперників та багато іншого.
Тут я поділю дані на дві частини та поясню, як вони формуються:
- Оновлення даних матчів у прямому ефірі (події матчу, як-от голи, картки, заміни тощо) транслюється через WebSockets, уся інформація про події матчу в прямому ефірі передається від нашого постачальника, зберігається на нашій стороні та передається безпосередньо на мобільний або веб-застосунок.
- Статистичні дані (таблиці ліг, історія та статистика матчів суперників, травмовані гравці, які не можуть брати участь тощо) отримуються безпосередньо з нашого боку, оскільки ми зберігаємо та готуємо дані заздалегідь
Тож, так, ми зберігаємо та працюємо з дійсно великими обсягами спортивних даних :)
Візуалізація потоку даних
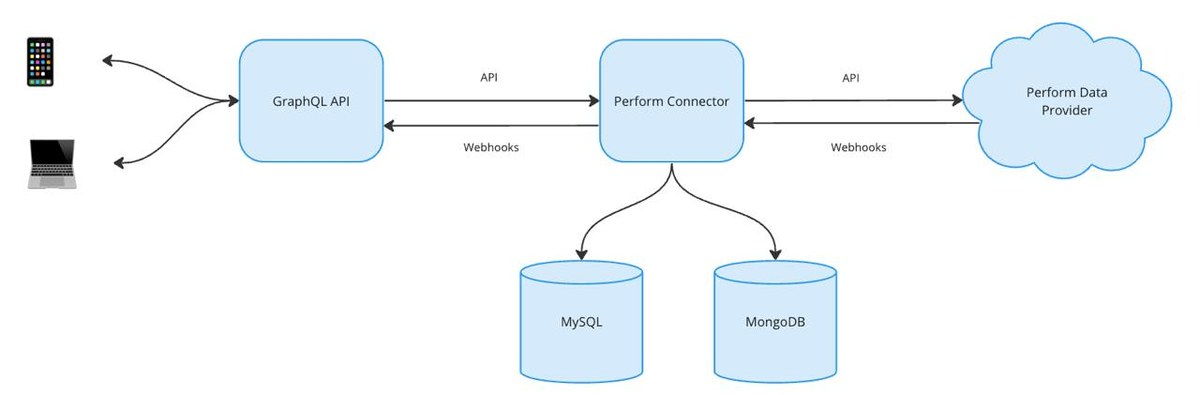
- Інтерфейс користувача (веб або мобільний додаток). Користувач ініціює запит, відкривши сторінку в Інтернеті або екран мобільного додатку. Програма надсилає запит до GraphQL API, щоб отримати дані.
- GraphQL API. API служить посередником, отримуючи запит від мобільного додатка та пересилаючи його до конектора постачальника. Він структурує запити, щоб запитувати як дані в реальному часі, так і історичну статистику.
- Perform конектор. Схематичний компонент, що агрегує декілька мікросервісів і scheduled jobs, діє як міст між API GraphQL і постачальником даних, використовує різні бази даних для зберігання всіх видів статистики зібраної в live або polled daily, забезпечуючи цілісність і доступність історичних даних
- Бази даних. Ми використовуємо як MySQL, так і MongoDB для нормалізованих і денормалізованих даних, MongoDB, використовується для даних, структура яких часто змінюється або швидкість читання потребує оптимізації (наприклад, live match data)
Вподобання користувача
Гаразд, ми робимо запити на отримання, отримуємо, зберігаємо та обслуговуємо дані, щоб сформувати список матчів. Це круто, але необроблені дані самі по собі не такі вже й круті. Наприклад, коли ви відкриваєте сторінку матчу, ви також хотіли б побачити: хто з гравців травмований, хто приєднався до команди цього сезону, як той чи інший гравець виступає у цьому сезоні, яка історія протистоянь між командами та багато інших додаткових даних.
Їх не можна отримати результатом простого поллінгу розкладу матчів. Крім того, деякі дані можуть бути неправильними (наприклад, назви гравців або ліг) і мають бути перевірені. Крім того, якщо ви перебуваєте, наприклад, у Великій Британії, ви, швидше за все, хотіли б спочатку побачити в списку матчі АПЛ (Англійська Прем’єр-Ліга), а не якесь випадкове змагання, тому дані повинні подаватись іншим способом залежно від географічного розташування.
Щоб упоратися з цим, ми витрачаємо багато часу на розробку та створення продуктів для обробки, перетворення, збагачення та перевірки даних на нашому боці. Ми робимо це, зберігаючи сирі дані та поєднуючи їх із нашими власними (наприклад, ми замінюємо назви команд за замовчуванням або додаємо переклади імен гравців або змагань). Таким чином, враховуючи географічне розташування користувача, ми надаємо корисні дані у змістовний та привабливий для нього спосіб.
Висновок
Робота з даними є життєво важливою частиною розробки сучасного програмного забезпечення, що має відповідати високому темпу життя людини. Цифрові спортивні медіа не є винятком. Неможливо обслуговувати тисячі футбольних ліг у Matchday із сотнями матчів у прямому ефірі одночасно (не кажучи про інші види спорту), наповнюючи контент вручну, повільно або просто показуючи рахунок, статистика повинна бути цікавою, мати додаткову цінність.
Подумайте, чи користувались би ви веб-сайтом або додатком, де результати матчів оновлюються з відставанням, або де ви, відкриваючи сторінку матчу, бачили лише рахунок? Чи, можливо, пішли б деінде за оновленнями даних в реальному часі та цікавою статистикою?
Використовуючи постачальника даних, ми гарантуємо, що ми отримуємо «сировину». Але це набагато більше, ніж просто отримання даних — ми повинні переконатися, що користувач отримує їх вчасно. Також вони мають бути підготовлені та подані, забезпечуючи додаткову цінність. До того ж це має бути розважально.
Залишайтеся з нами, щоб отримати більше технічної інформації про можливості обробки даних нашою платформою.