Усім привіт, мене звати Владислав Мишоловський, я — Data/BI Engineer у компанії Yalantis. Моя робота охоплює впровадження сучасних підходів до роботи з даними, що сприяє успіху замовників і розвитку компанії.
В сучасний період багато компаній вирішують стратегічні завдання, спираючись на аналіз даних. З обсягами накопичених даних, що зростають в геометричній прогресії, важливість ефективного управління ними та обробки стає просто критичною. З цієї причини виникає необхідність високоефективних систем ETL (Extract, Transform, Load), які дають змогу збирати, трансформувати та завантажувати дані.
Що таке ETL?
ETL (extract, transform, load) визначається як комплексний процес, який дає змогу збирати дані з багатьох джерел в єдиний центр обробки даних. Під час завантаження, він аналізує та агрегує дані для аналітичних завдань, процесів машинного навчання тощо. Цей підхід допомагає забезпечити якість та консистентність даних, що є важливим для правдивого аналізу.
Процес ETL містить у собі кроки трансформації, які перетворюють дані з різних джерел у спільний формат, спрощуючи їх для подальшого використання в бізнес-застосунках.
Як працює ETL?
ETL охоплює 3 поетапних процеси:
Extract
Першим кроком є копіювання або експорт даних із джерел даних у проміжні області. Джерела даних можуть бути різних типів, наприклад:
- MySQL, PostgreSQL, NoSQL бази даних.
- CSV, JSON, XML, плоскі файли.
- Файли Hadoop.
Проміжна область зазвичай тимчасова і стирається після закінчення ETL, але у разі необхідності може бути історизованою для проведення бекапів, залежно від бізнес-вимог та обсягу збереженої інформації. То ж для полегшення маніпуляціями з сирими даними варто одразу розподіляти дані на партиції завантаження або створювати маркери.
Є три варіанти першого етапу:
- Повне вилучення — вивантаження всіх даних, незалежно від того, чи відбулися зміни, та без умов. Це може бути витратно з точки зору ресурсів, але гарантує повну актуальність даних на вході.
- Часткове вилучення з повідомленням про оновлення — це витягування лише тих даних, які зазнали змін, а також інформації або «повідомлень» від джерела про те, які саме записи були змінені. Це дає змогу ефективніше витягувати лише актуальні дані та зменшити обсяг трафіку.
- Часткове вилучення без повідомлення про оновлення — у цьому випадку також витягуються лише змінені дані, але без повідомлень про оновлення від джерела. Це може призвести до більшого обсягу трафіку, оскільки системі доведеться визначити самостійно, які дані зазнали змін.
Transform
Дані, які були завантажені у проміжну область, є сирими й необробленими. Відповідно, у цьому етапі їх потрібно очистити, підготувати та трансформувати для аналізу. Приклади можливих обробок даних:
- Очищення або збагачення даних — це потрібно для того, щоб видалити непотрібні дані або навпаки.
- Перевірка відповідності колонок відповідно до кінцевої бази даних.
- Фільтрація — обмеження даних за відповідними умовам.
- Перевірка типів та формату даних — цей процес охоплює перевірку, наприклад, дат і чисел.
- Стандартизація — перевірка відповідних бізнес-стандартів.
- Дедублікація — перевірка та видалення повторюваних даних.
- Агрегація — процес, який передбачає калькуляцію деяких даних (наприклад, порахувати прибуток, середнє число тощо)
- Розщеплення — розділення значень з одного стовпця на кілька стовпців.
- Валідація — перевірка якості даних за допомогою аудитів.
- Шифрування даних.
Load
Останній етап — завантаження. На цьому етапі дані завантажуються із проміжної області в кінцеве сховище. Є два типи завантаження:
- Повне завантаження — у цьому сценарії всі дані, що пройшли процес трансформації, замінюють собою всі дані, що були записані в попередню ітерацію завантаження до сховища даних. Це іноді буває корисним, але це призводить до експоненційного зростання обсягу даних і з часом утруднює його підтримку через постійну потребу в обробці застарілих даних.
- Інкрементальне завантаження
Простіший, але керований підхід є інкрементальне завантаження. Воно порівнює вхідні дані з наявними та створює нові записи лише у разі виявлення нової унікальної інформації чи за допомогою фільтрів на дату, партицій, чексум. Є два типи:- Потокове завантаження — це процес неперервного завантаження та обробки даних в реальному часі, забезпечуючи миттєву доступність актуальної інформації для аналізу та вирішення бізнес-завдань.
- Пакетне завантаження — це процес завантаження та обробки даних в обмеженій кількості, часто групами чи «пакетами», зазвичай в позаперіодні часи або за певним графіком, з метою оптимізації ресурсів та керування навантаженням на систему. Пакетні завантаження часто можна проводити асинхронно для оптимізації процесів.
Приклад ETL на Python
Нижче наведено приклад ETL-процесу для збору даних з Amazon RDS, подальшої обробки на S3 з використанням Airflow на основі Python і SQL, а також завантаження в Amazon Redshift. Діаграма схеми даних містить у собі наступні кроки:
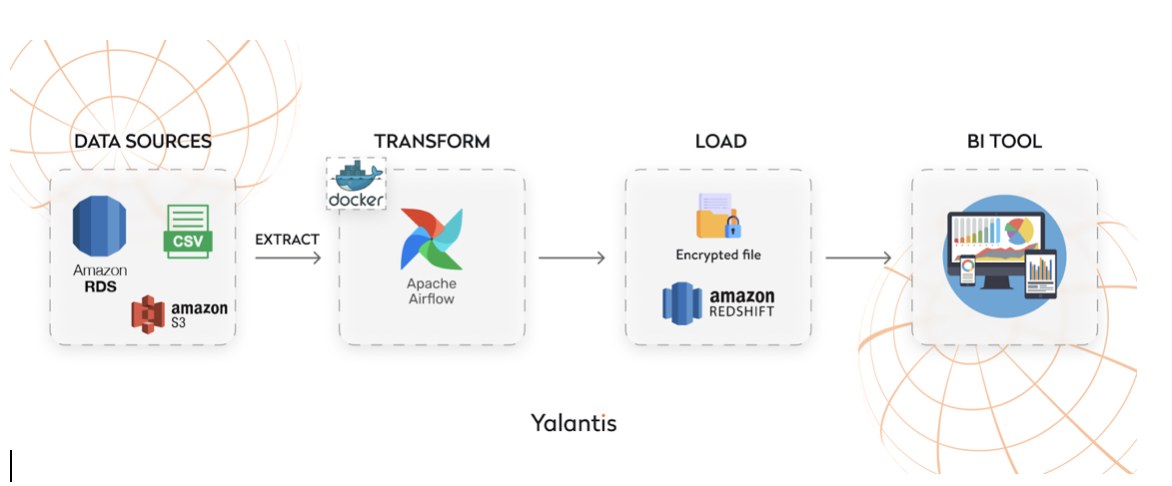
Крок 1. Завантаження даних із RDS і зашифрованих даних з S3
Спочатку визначається основна інформація для DAG — імʼя, його розклад та електронну пошту для відправки обмеженої інформації. Потім встановлюється з'єднання з базою даних RDS за допомогою SQLAlchemy. Підключення до бази даних виконується з використанням Secrets manager. Потім здійснюється читання даних з бази даних за допомогою SQL-запиту. Перед завантаженням файлу з S3 для збагачення, виконується перевірка його наявності. Це робиться на випадок реплікації або його видалення. Після цього отримані дані збагачуються зашифрованими даними з S3 за допомогою DAG. У випадку, якщо файл відсутній або є помилка від Secrets manager, виконується відправка повідомлення на електронну пошту з обмеженою інформацією.
Дуже важливо перевіряти, що буде відправлятись, тому що є ризик відправки конфіденційних даних (credentials, посилання, назви баз даних і т. п.)
Результат обробки зберігається у форматі CSV.
import pandas as pd
import boto3
import botocore.exceptions
import json
import psycopg2
from airflow.providers.email import EmailOperator
from airflow.providers.amazon.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.operators import PythonOperator
from airflow import DAG
from datetime import datetime
from sqlalchemy import create_engine
from cryptography.fernet import Fernet
#
DAG_NAME = «ETL_RDS_Redshift»
DAG_SCHEDULE = '@daily'
EMAIL_FOR_LIMITED_INFO = '[email protected]'
#
dag = DAG (
DAG_NAME,
start_date=datetime (2024, 1, 1),
schedule_interval=DAG_SCHEDULE,
)
#
secrets_manager = boto3.client ('secretsmanager', region_name='your_region')
secret_name = 'your_rds_secret_name'
try:
#
secret_response = secrets_manager.get_secret_value (SecretId=secret_name)
secret_data = json.loads (secret_response['SecretString'])
#
rds_username = secret_data['username']
rds_password = secret_data['password']
rds_host = 'rds_endpoint'
rds_db_name = 'db_name'
#
rds_connection_string = f"mysql://{rds_username}:{rds_password}@{rds_host}/{rds_db_name}»
engine = create_engine (rds_connection_string)
# db_dataset»
query = «SELECT * FROM your_table»
db_df = pd.read_sql (query, engine)
db_df.to_csv ('db_dataset.csv', index=False)
#
s3 = boto3.client ('s3', aws_access_key_id='your_access_key', aws_secret_access_key='your_secret_key')
s3_bucket = 'your_bucket'
s3_path = 'encrypted_dataset.csv'
try:
#
s3.head_object (Bucket=s3_bucket, Key=s3_path)
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == '404':
#
email_task = EmailOperator (
task_id='send_error_message',
to=EMAIL_FOR_LIMITED_INFO,
subject=f"Error in {DAG_NAME} DAG: File '{s3_path}' not found in S3 bucket»,
html_content=f"File '{s3_path}' not found in S3 bucket. See details:\n» + e.response['Error']['Message'],
dag=dag,
)
email_task.execute (context=None)
exit ()
#
s3.upload_file ('encrypted_dataset.csv', s3_bucket, s3_path)
except botocore.exceptions.ClientError as e:
#
email_task = EmailOperator (
task_id='send_error_message',
to=EMAIL_FOR_LIMITED_INFO,
subject=f"Error in {DAG_NAME} DAG: Accessing RDS secrets»,
html_content=f"Error accessing RDS secrets. See details:\n» + e.response['Error']['Message'],
dag=dag,
)
email_task.execute (context=None)
exit ()
Крок 2. Завантаження збагачених даних до Redshift через Apache Airflow
Наступним кроком є перевірка відповідністю колонок, після чого виконується обʼєднання двох датасетів. Далі функція encrypt_encrypted_dataset запитую секрети для шифрування і шифрує готовий датасет перед завантаженням.
Після цього створюється функція load_data_to_redshift, яка використовує SQL-запит COPY для завантаження даних з S3 до Redshift.
Далі, створюється функція load_encrypted_data_to_redshift для завантаження зашифрованих даних з S3 до Redshift.
Наступним кроком є створення Directed Acyclic Graph (DAG) в Apache Airflow, включно з 3 завданнями: merge_datasets_task, encrypt_encrypted_dataset_task, load_all_data_task.
Залежності між цими завданнями також встановлюються.
#
def merge_datasets ():
db_dataset = pd.read_csv ('db_dataset.csv')
encrypted_dataset = pd.read_csv ('encrypted_dataset.csv')
#
if set (db_dataset.columns)≠ set (encrypted_dataset.columns):
email_task = EmailOperator (
task_id='send_error_message',
to=EMAIL_FOR_LIMITED_INFO,
subject=f"Error in {DAG_NAME} DAG: Columns in datasets do not match.»,
html_content="Columns in datasets do not match.»,
dag=dag,
)
email_task.execute (context=None)
exit ()
all_data = pd.merge (db_dataset, encrypted_dataset, on='common_column', how='inner')
all_data.to_csv ('all_data.csv', index=False)
# encrypted_dataset.csv»
def encrypt_encrypted_dataset ():
#
secrets_manager = boto3.client ('secretsmanager', region_name='your_region')
#
secret_name = 'your_secret_name'
secret_response = secrets_manager.get_secret_value (SecretId=secret_name)
secret_data = json.loads (secret_response['SecretString'])
encryption_key = secret_data['encryption_key']
#
cipher_suite = Fernet (encryption_key)
encrypted_data = cipher_suite.encrypt (all_data.to_csv (index=False).encode ())
encrypted_data_df = pd.DataFrame ({'data': [encrypted_data]})
encrypted_data_df.to_csv ('encrypted_dataset.csv', index=False)
#
#
def load_all_data_to_redshift ():
try:
#
secrets_manager = boto3.client ('secretsmanager', region_name='your_region')
secret_name_redshift = 'your_redshift_secret_name'
secret_response_redshift = secrets_manager.get_secret_value (SecretId=secret_name_redshift)
secret_data_redshift = json.loads (secret_response_redshift['SecretString'])
#
redshift_username = secret_data_redshift['username']
redshift_password = secret_data_redshift['password']
redshift_host = 'your_redshift_host'
redshift_db_name = 'your_redshift_db_name'
redshift_connection_string = f"postgresql+psycopg2://{redshift_username}:{redshift_password}@{redshift_host}/{redshift_db_name}»
# all_data» до Redshift
copy_query = f"COPY your_redshift_table FROM 's3://{s3_bucket}/all_data.csv' DELIMITER ',' CSV;»
with psycopg2.connect (redshift_connection_string) as conn:
with conn.cursor () as cur:
cur.execute (copy_query)
except Exception as e:
#
email_task = EmailOperator (
task_id='send_error_message',
to=EMAIL_FOR_LIMITED_INFO,
subject=f"Error in {DAG_NAME} DAG: loading all data to Redshift»,
html_content=f"Error loading all data to Redshift. See details:\n» + e.response['Error']['Message'],
dag=dag,
)
email_task.execute (context=None)
exit ()
#
merge_datasets_task = PythonOperator (
task_id='merge_datasets',
python_callable=merge_datasets,
dag=dag,
)
encrypt_encrypted_dataset_task = PythonOperator (
task_id='encrypt_encrypted_dataset',
python_callable=encrypt_encrypted_dataset,
dag=dag,
)
load_all_data_task = PythonOperator (
task_id='load_all_data_to_redshift',
python_callable=load_all_data_to_redshift,
dag=dag,
)
#
merge_datasets_task >> encrypt_encrypted_dataset_task >> load_all_data_task
Покриття результатів завантаження на виявлення простих аномалій даних
Для виявлення простих аномалій даних у результаті завантаження в процесі ETL, можна використовувати різноманітні методи та стратегії:
1. Перевіряти на наявність дублів.
Використання SQL-запитів для ідентифікації дублів у завантажених даних допомагає попередити можливі проблеми з дублюванням інформації. Приклад SQL запиту:
SELECT column1, COUNT (*)
FROM table_name
GROUP BY column1, …
HAVING COUNT (*) > 1;
2. Перевірка на відсутність значень (NULL). Приклад SQL запиту:
SELECT *
FROM table_name
WHERE column1 IS NULL OR column2 = '';
3. Валідація формату даних.
Перевірка відповідності формату даних описаному в схемі бази даних для уникнення помилок при завантаженні.
Обов’язково потрібно узгодити з замовником вимоги до обов’язкових полів, якщо такі є та покривати тестами їх наповнення.
Покриття тестами результатів обробки даних попередить некоректність в відображеннях для бізнесу і є важливою частиною процесу завантаження даних.
Приклади використання ETL для оптимізації бізнес-процесів у великих компаніях

Amazon
Amazon використовує ETL для обробки та аналізу величезного обсягу даних з різних джерел, таких як інтернет-магазин, вебсервери та системи управління запасами. Це дуже корисно, щоб швидко адаптуватися до змін у попиті на товари, прогнозувати та управляти запасами, а також розробляти персоналізовані стратегії маркетингу для своїх клієнтів.
Walmart
ETL в цій компанії використовує ETL для агрегації та консолідації даних з тисяч магазинів та постачальників у всьому світі. Це дозволяє компанії ефективно управляти ланцюгом постачання, прогнозувати попит, здійснювати аналіз витрат та вдосконалювати стратегії продажу.
Goldman Sachs
У фінансовому секторі, Goldman Sachs потрібен ETL для обробки та аналізу фінансових даних з різних джерел, таких як транзакції, ринкові дані та внутрішні системи. Це важливо для прийняття стратегічних інвестиційних рішень, розробляти ризик-менеджмент та виконувати фінансові аналізи з метою забезпечення високої ефективності та відповідності з правовими вимогами.
ETL проти ELT: у чому різниця?
ELT ефективно працює з великими обсягами неструктурованих даних, що вимагають частого завантаження. Він також ідеально підходить для обробки великих обсягів даних, оскільки планування аналітики можна виконати після вилучення та зберігання даних. ELT залишає основні перетворення для етапу аналітики та акцентується на завантаженні мінімально оброблених необроблених даних у сховище даних.
В процесі ETL необхідне більше деталей на початковому етапі. Залучення аналітиків на початковій стадії є обов’язковим для визначення цільових типів даних, структур та зв’язків. Дослідники даних часто використовують ETL для завантаження застарілих баз даних у сховище, тоді як ELT стає більш поширеним сьогодні.
Тенденції, майбутнє у світі ETL та аналізу даних
В сучасному світі збільшення обсягів даних та швидка зміна технологій визначають нові виклики й можливості для сфери ETL та аналізу даних. Тенденції у цих галузях стають визначальними для бізнесу, прогнозуючи не лише розвиток технологій, але й вплив на стратегії прийняття рішень. Розглянемо приклади наступних тенденцій:
Автоматизація та Штучний Інтелект (ШІ)
Однією з основних тенденцій у світі ETL та аналізу даних є висхідна важливість автоматизації процесів завантаження, трансформації та завантаження за допомогою технологій Штучного Інтелекту. Майбутнє цього напряму полягає в інтеграції алгоритмів машинного навчання для автоматичної ідентифікації та оптимізації ETL-процесів, що дозволить швидше та ефективніше обробляти великі обсяги даних.
Обробка стріму даних
Ще однією ключовою тенденцією є зростання обсягів стрімінгових даних. Майбутнє полягає в інтеграції засобів обробки стрімінгових даних у системи ETL, що дозволить компаніям отримувати реальний час аналітики та реагувати на події миттєво.
Інтеграція з Big Data технологіями
Однією з ключових тенденцій майбутнього є подальше зростання використання Big Data технологій у сфері ETL. Забезпечення сумісності з різноманітними джерелами даних, такими як Hadoop та Spark, стане стандартом, дозволяючи ефективно обробляти великі обсяги даних та забезпечувати високу продуктивність аналітичних операцій.
Зростання популярності Cloud ETL
Cloud ETL послуги набувають все більшої популярності, оскільки вони пропонують гнучкість та масштабованість. Майбутнє ETL полягає в широкому використанні хмарних сервісів для оптимізації ресурсів та забезпечення доступності даних у будь-якому місці та часі.
Застосування технологій контейнеризації
Використання технологій контейнеризації, таких як Docker та Kubernetes, стає все популярнішим для розгортання та масштабування ETL процесів. Це дозволяє забезпечити консистентність та легкість управління різноманітними складними компонентами ETL систем.
Порівняння різних платформ ETL
Apache Spark. Хоча Spark в першу чергу відомий як фреймворк для обробки даних в реальному часі та машинного навчання, він також може використовуватися для ETL завдань. Він дозволяє працювати з великими обсягами даних та використовується для паралельної обробки.
Apache Nifi. Ця відкрита платформа ETL зосереджена на легкості використання та забезпеченні потужних можливостей для обробки даних. Nifi дозволяє з легкістю налаштовувати потоки даних і працювати з різними джерелами та призначеннями.
Microsoft SSIS (SQL Server Integration Services). SSIS є частиною платформи Microsoft SQL Server та надає широкі можливості для інтеграції та обробки даних. Вона добре інтегрована з іншими продуктами Microsoft.
Informatica. Це одна з провідних комерційних ETL-платформ, яка відзначається високою продуктивністю та надійністю. Informatica пропонує різні рішення для обробки даних, включаючи Master Data Management.
При виборі платформи ETL слід розглядати потреби конкретного проєкту, типи джерел та призначень даних, а також доступні ресурси для підтримки та розгортання платформи.
Висновок
У висновку на тему ETL слід відзначити, що ефективна інтеграція та обробка даних стає ключовим фактором у сучасному бізнес-середовищі. Використання ETL-процесів дозволяє підприємствам оптимізувати свою діяльність, забезпечуючи точні та зручні інструменти для аналізу та використання даних. З урахуванням постійного розвитку технологій та платформ ETL, компанії можуть ефективно впроваджувати нові інновації та вдосконалювати свої бізнес-процеси для досягнення вищих стандартів ефективності та конкурентоспроможності.