Мене звати Ілля Маляренко, я — Data/Bi Engineer у компанії Yalantis. Мій досвід Data інженером — 3 роки, працював із різними глобальними корпораціями у сфері медіа, медицини та харчових продуктів, нерухомості, а саме, — з великими обсягами даних. З огляду на минуле, я використав багато технологій і про цікавішу з них зараз піде мова — це DBT.
DBT розроблений для роботи з даними в компаніях будь-якого розміру, від маленьких стартапів до великих корпорацій. Він також повністю сумісний з великими сховищами даних, такими як BigQuery, Snowflake, Redshift і інші. Однією з ключових переваг DBT є його вартість. Це відкритий інструмент, який може бути використаний абсолютно безоплатно.
Що таке DBT і для чого потрібен?
DBT — це інструмент для трансформації на основі SQL, який дає змогу командам швидко і спільно розгортати аналітичний код відповідно до найкращих практик програмної інженерії, таких як модульність, портативність, CI/CD та документування. З ним будь-хто з команди, що працює з даними, може безпечно використати дані виробничого рівня включаючи проміжні перетворення.
Цей інструмент не обробляє дані самостійно, а лише подає SQL запити на виконання до вашого сховища або рушія, проте він дозволяє систематизувати ваші трансформації та покращити їх розуміння.
Давайте я вас заінтригую розповівши про ціноутворення та можливості використання.
Прайсинг і можливості розгортання
DBT має декілька варіантів розгортання, в залежності ваших потреб і розміру команди.
Ви можете вибрати де зберігати код:
- Використовувати системи контролю версій.
- Використовуючи хмарне сховище від розробників DBT.
Визначившись з місцем зберігання коду, перейдемо до можливих варіантів використання:
- Перший — це DBT Core, що являє собою Python пакет із відкритим кодом, і може бути використаний безоплатно, і бути гнучко налаштованим під ваші потреби. Ви можете запускати його як локально, так і, в поєднанні з планувальниками як от Airflow чи інших.
- DBT Cloud — це хмарна платформа, яка надає веб інтерфейс, планувальник та інші функції для керування та запуску проєктів DBT. Якщо казати спрощено, то це як IDE у вигляді вебсайту, яка працює на основі DBT core і дозволяє вам менше піклуватись про те як буде запускатись оновлення даних, і більше концентруватись саме на розробці моделей, а не на інфраструктурі. DBT Cloud має три плани ціноутворення: Developer, Team та Enterprise.
Developer — ви матимете змогу запускати до 3000 моделей безоплатно, включаючи заплановані автоматичні запуски та використанням документації, проте тільки для одного проєкту. Це ідеальний варіант якщо ви хочете спробувати даний інструмент або у вас невеликий проєкт, над яким працюєте здебільшого тільки ви.
Team — якщо у вас команда до 8 осіб, то можете використати командний план, який коштуватиме 100$ на місяць за місце і додатково до попереднього надає безкоштовні 5 місць з доступом тільки на перегляд, та доступом до Semantic Layer.
Enterprise — це все, що в попередніх планах, але з більшим нахилом на приватність даних, моніторинг витрат та кращу тех. підтримку.
Як ви бачите, це є дуже заманливо, що ви можете дуже гнучко та з мінімальними коштами почати використовувати даний інструмент. Особливо якщо використаєте повністю безоплатний Python пакет. І у вас є вибір використовувати готове хмарне рішення чи налаштувати все власноруч.
Які переваги дає DBT для C-level, аналітиків та інших decision makers
- Покращення якості даних. DBT допомагає покращити якість даних, використовуючи тести і документацію для перевірки і опису трансформацій даних. Це допоможе знизити витрати на контроль якості.
- Швидше досягнення цінності. З DBT дуже швидко й ефективно будувати пайплайни трансформації даних, використовуючи лише SQL-запити й Jinja-шаблонування.
- Доступність. Будь-хто з доступом до вашої бази даних може переглянути проміжні результати перетворення, та переглянути походження даних.
- Ізольованість. DBT не потребує окремого місця для зберігання даних, все зберігається у вашому сховищі.
- Масштабованість. DBT розроблений для роботи з компаніями будь-якого розміру, від маленьких стартапів до великих корпорацій.
- Вартість. DBT — це відкритий інструмент, який може бути безоплатним для використання.
- Можливість відстежувати зміну даних. Ви зможете простежити, які саме дані та коли змінились, що нерідко буває корисним при аналізі та побудові моделей.
- Кастомізованість. Ви можете використовувати додаткові пакети, що розширюють функціонал DBT, які можете зробити самими.
Можливості DBT
DBT також має такі основні можливості, як:
- SQL & Python. Ви маєте справу тільки з SQL запитами, такі як SELECT. Додатково можете використати Python скрипти, якщо це підтримує ваше сховище.
- Jinja. У випадку коли ваш SQL код повторюється або потребує більш просунутого форматування, ви використовуєте Jinja2, що спростить розуміння та підвищить швидкість.
- Макроси. Макроси в DBT — це фрагменти коду, які можна використовувати багато разів в різних моделях. Вони схожі на функції в інших мовах програмування і дуже корисні, якщо ви повторюєте код.
- Документація. У DBT ви можете детально описати ваші дані, включно з колонками та з генерацією походження даних.
- Снепшоти. Snapshots дозволяють зберігати історичні дані з джерел даних, які змінюються з часом. Це дає додаткові можливості аналізу та прийняття рішень.
- Seeds. Це CSV-файли в вашому проєкті DBT, які можуть бути використані для фільтрування.
- Пакети. DBT дозволяє завантажити додаткові макроси, тести та інший функціонал.
- Джерела даних. DBT може використовуватись з великим переліком сховищ даних.
Порівняємо DBT із аналогами такі як Oracle Data Integrator або Looker.
Як DBT відрізняється від інших інструментів по роботі з даними, таких як Oracle Data Integrator або Looker
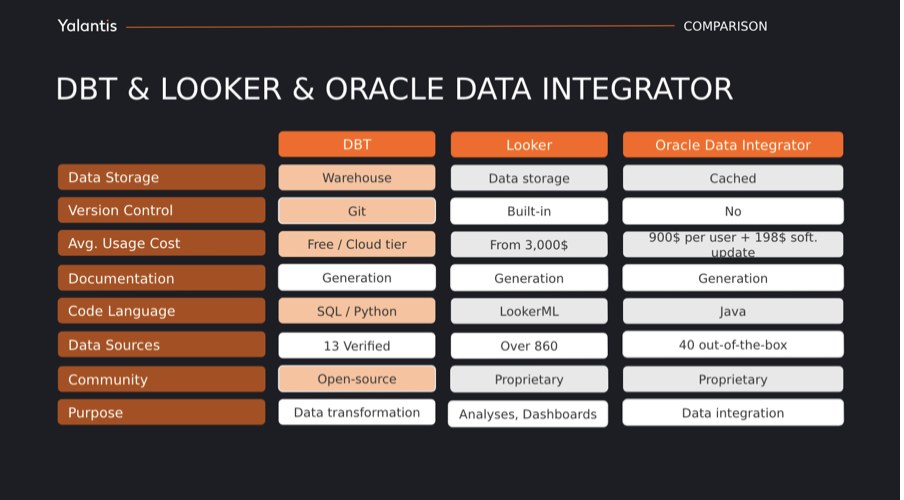
DBT відрізняється від інших інструментів по роботі з даними, таких як Oracle Data Integrator або Looker, за кількома параметрами — призначенням, мовою програмування та ціною.
Призначення
- Oracle Data Integrator — це інструмент для інтеграції даних, який дозволяє розробникам писати ETL/ELT-скрипти для переміщення, очищення і збереження даних з різних джерел.
- Looker — це інструмент для візуалізації даних, який дозволяє аналітикам писати LookML-код для створення інтерактивних дашбордів і звітів на основі даних зі сховищ даних.
Мова програмування
- DBT використовує SQL як основну мову програмування.
- Oracle Data Integrator використовує Java, Groovy, Python і інші мови програмування, що робить його складним і потребує високих технічних навичок.o Looker використовує LookML як основну мову програмування, що робить його гнучким й експресивним для аналітиків.
Ціна:
- DBT є відкритим програмним забезпеченням, яке можна безоплатно використовувати на своїй локальній системі або платити за хмарний сервіс.
- Oracle Data Integrator є комерційним програмним забезпеченням, яке потребує ліцензування та платежів за підтримку.
- Looker є комерційним програмним забезпеченням, яке потребує платежів за користувача та обсяг даних.
Oracle Data Integrator пропонує ширшу функціональність для роботи з даними на всіх етапах ETL, таких як видобуток, завантаження, очищення, збереження та аналіз даних. Looker має потужні можливості візуалізації. У той час як DBT фокусується тільки на SQL трансформаціях та представленні таблиць, тому він більше підійде коли не потрібен зайвий функціонал.
Технічна частина і можливості DBT
Як використовувати DBT — Cloud, Core
Спочатку треба визначити як буде розгортатись DBT. У випадку використання DBT Cloud вам не потрібно буде думати за автоматизацію оновлень моделей.
Якщо ваша ціль полягає на зменшенні витрат, і використання наявної інфраструктури, тоді підійде DBT Core.
Після вирішення цього, розгляньмо як будуються моделі.
Що таке модель
У DBT будь-яка модель представлена sql файлом, або Python-скриптом. Наразі ми розглянемо SQL, як найбільш вживаний.
Приклад моделі нижче.

Як бачимо, в моделі є використання CTE, як best practice перелічення джерел, і в них є посилання на попередні моделі. Для посилання використовується Jinja2.
Як виконати розбивку на шари, best practice, опис моделей
У DBT заведено використовувати 3 кроки перетворення даних:
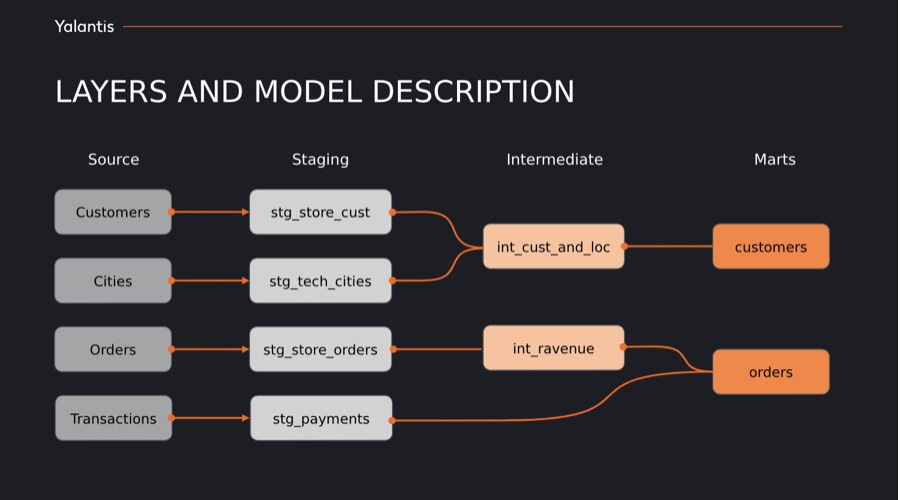
Source — початкові таблиці в базі даних
Staging — базові трансформації початкових таблиць, такі як агрегації, count, max, case when. Все те, що можна зробити на основі однієї початкової таблиці.
Intermediate — на цьому кроці моделі зі Staging об’єднуються за допомогою join, union. Тут виконуються комплексні трансформації, що потребують декількох моделей.
Marts — остаточний результат перетворень, тут об’єднуються моделі з Intermediate, Staging та Source рівнів. Тут описана лише логіка об’єднання та базові трансформації. Основні перетворення виконуються на попередньому кроці.
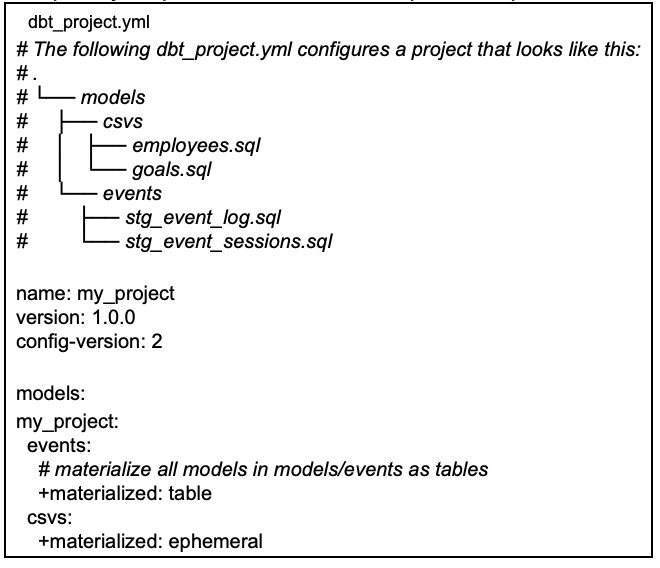
Це лише рекомендації для побудови кроків обробки. Вони представлені у вигляді папок у вашому репозиторії.
Приклад організації файлів у DBT
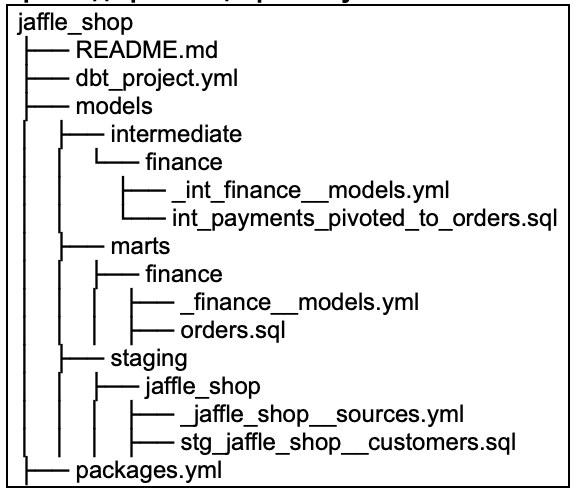
Після того як оглянули структуру проєкту, перейдемо до опису моделей та документації.
Документація
Документація в DBT задається у вигляді опису колонок, моделей та макросів. Для додавання опису треба створити yml файл з наступною структурою у папці з моделями.

Пізніше ви можете переглянути її у вигляді вебсторінки, де буде наступне:
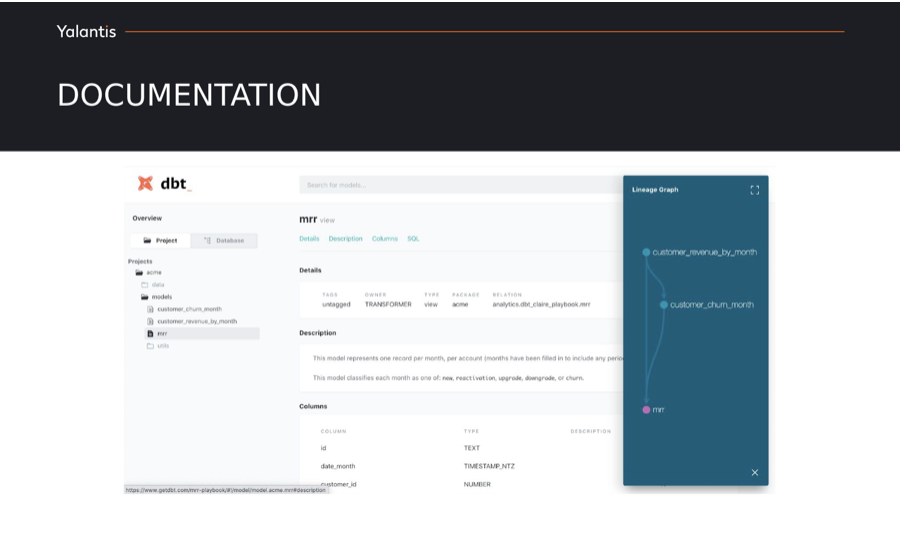
Тут ви можете бачити опис полів, структуру проєкту, як перетворювалися дані для побудови обраної моделі та можете переглянути згенерований SQL-запит.
Типи матеріалізацій
Як ви пам’ятаєте DBT не зберігає дані, тому нам треба задати їх представлення у сховищі. Це називається матеріалізація. Матеріалізації — це стратегії для збереження моделей dbt у сховищі. Є п’ять типів матеріалізацій, вбудованих у dbt. Ось вони:
- Table
- View
- Incremental
- Ephemeral
- Materialized view

View
При використанні матеріалізації view ваша модель перебудовується за допомогою інструкції create view as. Є стандартним типом матеріалізації.
Плюси: Результат завжди має найсвіжіші записи.
Мінуси: Під час комплексних перетворень довге виконання.
Table
При використанні табличної матеріалізації ваша модель перебудовується у вигляді таблиці під час кожного запуску за допомогою інструкції create table as.
Плюси: Запити до таблиць виконуються швидко
Мінуси: Перебудова таблиць може зайняти багато часу, особливо для складних перетворень. Нові записи у вихідних даних не додаються до таблиці автоматично.
Порада: використовуйте матеріалізацію типу table для будь-яких моделей, які інтегровані з інструментами BI, щоб пришвидшити роботу кінцевого користувача. Також використовуйте матеріалізацію таблиць для будь-яких повільних перетворень, які використовуються багатьма наступними моделями.
Incremental
Інкрементні моделі дають змогу dbt вставляти або оновлювати записи в таблиці з моменту останнього запуску dbt.
Плюси: Ви можете значно скоротити час збірки, просто трансформуючи нові записи.
Мінуси: Інкрементні моделі вимагають додаткового налаштування і є розширеним варіантом використання dbt.
Порада: Інкрементні моделі найкраще підходять для даних у стилі подій. Використовуйте інкрементні моделі, коли dbt стає надто повільно оновлювати моделі (тобто не починайте з інкрементних моделей).
Ephemeral
Ефемерні моделі не вбудовуються безпосередньо в базу даних. Натомість, dbt інтерполює код з цієї моделі у залежні моделі як CTE.
Плюси: Ефемерні моделі можуть допомогти спростити розуміння коду та розбити його на частини.
Мінуси: Ви не можете отримати дані безпосередньо з цієї моделі. Надмірне використання ефемерної матеріалізації може також ускладнити налагодження запитів.
Materialized view
Materialized view це порівняно нова матеріалізація яка підтримується DBT, вона дозволяє перекласти частину з реплікації відмінностей на сховище даних, на відміну від Incremental. Має відмінності реалізації в залежності від сховища.
Плюси: Залежить від бази даних, проте основна ідея що ваші дані будуть оновлені з певним інтервалом, саме сховищем, а не DBT. Це дозволить швидко отримати дані при необхідності та зберігати найновішу версію.
Мінуси: Ви маєте менше варіантів контролю такої матеріалізації.
Нюанси
Наразі доступні такі сховища:
- dbt-postgres
- dbt-redshift
- dbt-snowflake — використовуються dynamic table (preview feature)
- dbt-databricks
- dbt-materialize*
- dbt-trino*
- dbt-bigquery**
*Ці адаптери підтримували матеріалізовані представлення у своїх адаптерах до версії 1.6.
**Підтримка dbt-bigquery з’явиться у 1.7.
Макроси
Макроси — ще одна важлива частина DBT. Вона дає змогу спростити представлення коду та зменшити дублікацію. Для створення макросу вам треба створити окрему папку macros в основі репозиторію, додати туди sql файл з назвою макросу і yml файл, де буде опис макроса та полів.

Як ви бачите, макроси це аналоги функцій з програмування, які можуть спростити представлення коду та запобігти дублювання коду, а ще динамічно форматуються в залежності від поданих параметрів.
Tests
Існує два способи визначення тестів у dbt.
Одиничний тест — це тестування в його найпростішій формі: Якщо ви можете написати SQL-запит, який повертає невдалі рядки, ви можете зберегти цей запит у файлі .sql у вашому тестовому каталозі. Тепер це вже тест, і він буде виконаний командою dbt test.

Типовий тест — це параметризований запит, який приймає аргументи. Тестовий запит визначається у спеціальному тестовому блоці (як макрос). Після визначення ви можете посилатися на загальний тест за назвою у ваших .yml файлах — визначати його у моделях, стовпцях, джерелах, знімках і seeds. DBT постачається з чотирма вбудованими загальними тестами.

Інтеграції
DBT може використовуватись з різними сховищами даних — адаптерами.
Сьогодні існує три типи адаптерів:
Перевірені — це адаптери, які пройшли суворий процес перевірки у співпраці з dbt Labs.
Довірені — адаптери, розробники яких погодилися відповідати вищим стандартам якості.
Спільнота — адаптери спільноти мають відкритий вихідний код і підтримуються членами спільноти.

Які приклади успішного використання DBT в різних проєктах і компаніях?
DBT використовується багатьма компаніями і проєктами для трансформації даних в сховищах даних.

Ось деякі з них:
- JetBlue: це американська авіакомпанія, яка використовує DBT для побудови аналітичної платформи, яка інтегрує дані з різних джерел, таких як бронювання, польоти, лояльність, фінанси тощо.
- GitLab: це платформа для розробки програмного забезпечення, яка використовує DBT для аналізу даних про продуктивність, задоволення клієнтів, конверсію та інші метрики.
- Shopify: це платформа для електронної комерції, яка використовує DBT для побудови аналітичної інфраструктури, яка обробляє дані з більш ніж мільйона онлайн-магазинів.
- Monzo: це британський банк, який використовує DBT для побудови аналітичної платформи, яка інтегрує дані з різних систем, таких як транзакції, платежі, кредити тощо.
- Spotify: це світовий лідер у сфері потокового аудіо, який використовує DBT для побудови аналітичної платформи, яка обробляє дані з більш ніж 365 мільйонів користувачів.
- WeWork: це глобальна платформа для спільного простору, яка використовує DBT для побудови аналітичної платформи, яка інтегрує дані з різних систем, таких як CRM, фінанси, операції тощо.
- Fishtown Analytics: це компанія, яка розробила DBT та надає консалтингові послуги з аналітики даних. Fishtown Analytics використовує DBT для побудови аналітичних рішень для своїх клієнтів з різних галузей, таких як електронна комерція, освіта, медіа тощо.
Висновок
Якщо підсумувати, DBT — це потужний інструмент для трансформації даних, який дозволяє аналітикам писати SQL-код для створення аналітичних моделей в сховищах даних. DBT займається зберіганням SQL коду, опису моделей та структури, обробка даних виконується лише на стороні сховища при запуску SQL-запитів. Якщо проводити аналогію, то DBT — це як Airflow, який вмів би лише організовувати процес з документацією. Складність моделей обмежена тільки масштабованістю та оптимізацією вашого сховища даних та швидкістю обробки запитів. Для сховищ та рушіїв, що підтримують Python, ви можете більш гнучко налаштувати моделі.
DBT — це ідеальний варіант для команд, які хочуть швидко й ефективно будувати пайплайни трансформації даних, використовуючи лише SQL-запити й Jinja-шаблонування. З ним будь-хто з команди, що працює з даними, може безпечно використати дані виробничого рівня включаючи проміжні перетворення.
Про експертизу та досвід Yalantis у BI&Big Data ви також можете прочитати тут.