У сучасному eCommerce персоналізація вже не є додатковою опцією — вона стає основним драйвером зростання. Саме тому все більше компаній впроваджують технологію товарних рекомендацій. Вони допомагають вирішити одразу декілька важливих задач: підвищити конверсію сайту, збільшити середній чек і ефективніше використовувати маркетинговий бюджет. Дослідження McKinsey показує, що персоналізація дозволяє бізнесу скоротити витрати на залучення клієнтів до 50%, підняти дохід на 5–15% і збільшити ROI на 10–30%. За даними Barilliance, до 31% доходу інтернет-магазинів формується саме завдяки блокам рекомендацій.
Ця технологія стрімко розвивається. На заміну класичним алгоритмам, які обмежені історією купівель товарів і не завжди розуміють контекст поведінки користувача, прийшло нове покоління рішень, побудоване на трансформерній моделі у поєднанні з великими мовними моделями (LLM). Ця технологія дає змогу розуміти наміри покупця, працювати з неструктурованими даними й підбирати максимально релевантні рекомендації.
У статті ми показуємо, як працюють нові алгоритми рекомендацій, чим вони відрізняються від попередніх моделей, а також які результати вони дають українському ecommerce вже з першого тестування. Зокрема, Dnipro-M отримав зростання конверсії на 43%, MasterZoo — на 71%, а Yakaboo збільшив частку замовлень із рекомендацій на 126%.
Як працюють традиційні методи
Розглянемо алгоритми роботи попередніх версій ML, що формували рекомендації товарів.
Контентно-орієнтовані рекомендаційні системи
Цей підхід працює на основі аналізу характеристик товарів, з якими користувач уже мав взаємодію. Система порівнює атрибути продуктів — наприклад, розмір, колір, бренд, тип або категорію — і на основі цього пропонує схожі позиції.
Наприклад, якщо користувач переглядав кілька пар кросівок, модель відстежує цю активність і формує добірку схожого взуття, що потенційно може зацікавити конкретного користувача.
У випадку, коли користувач уже придбав кепку, спортивний костюм і кросівки одного бренду, система враховує не лише категорію (оскільки товари різнопланові), а й бренд як спільну ознаку. У результаті алгоритм запропонує джогери тієї ж марки, орієнтуючись на ймовірність інтересу до товарів даного виробника.
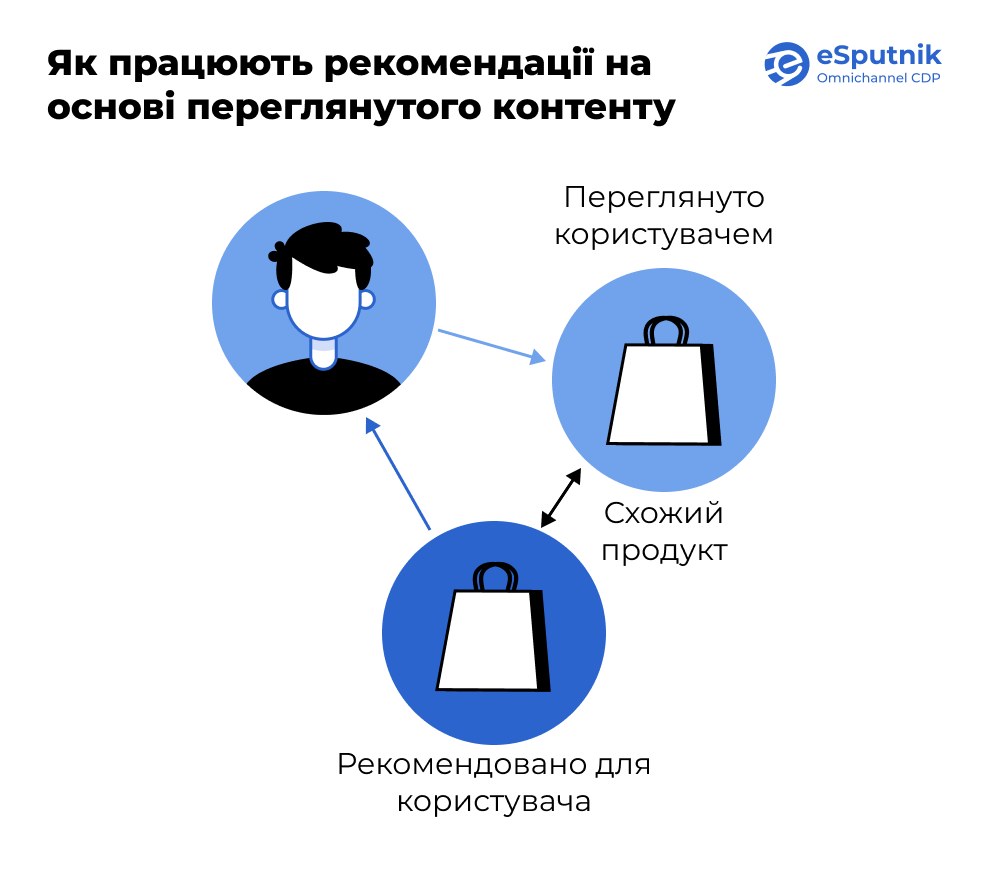
Контентно-орієнтований тип рекомендаційних систем вважається доволі базовим, адже він не виходить за межі відомих вподобань конкретного користувача. Алгоритм не «фантазує» далі зафіксованої поведінки. Однак саме в цьому полягає його перевага для окремих задач.
Сильні сторони:
- система працює автономно — їй не потрібна інформація про інших користувачів;
- ефективна для обслуговування індивідуальних, рідкісних або нішевих смаків;
- здатна просувати нові товари, які ще не встигли зібрати відгуки чи оцінки.
Обмеження:
- не здатна аналізувати складні поведінкові шаблони або контекст минулих дій;
- втрачає ефективність, якщо товар має обмежений опис або недостатньо атрибутів;
- може формувати надто вузьке коло рекомендацій, якщо історія взаємодій користувача обмежена.
Рекомендаційні системи на основі колаборативної фільтрації
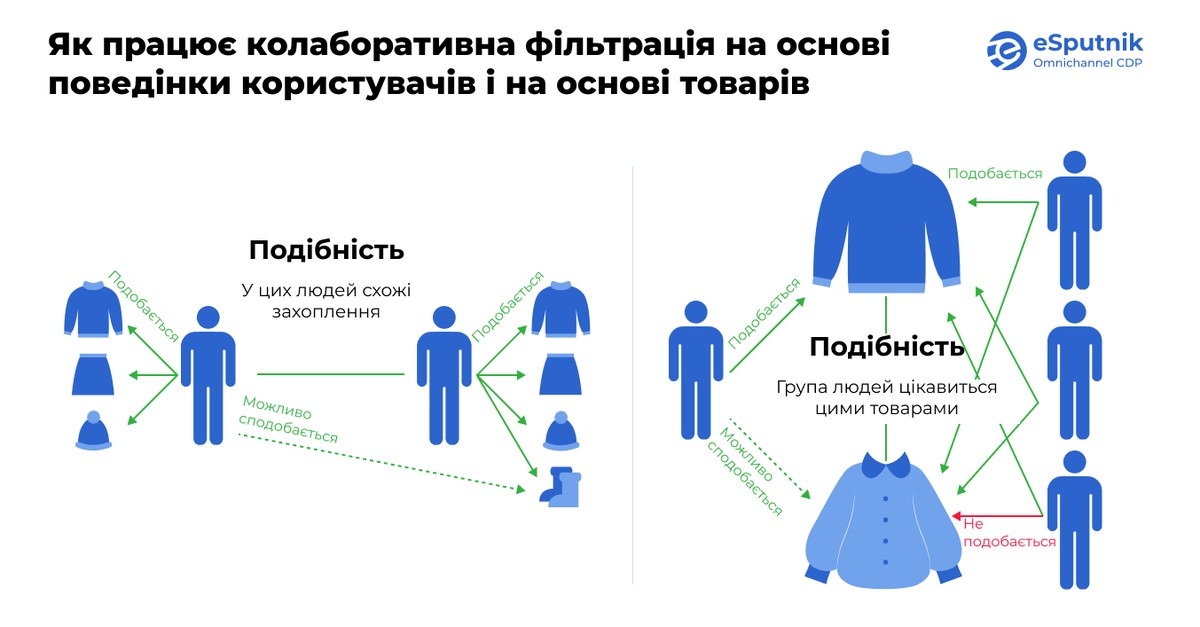
Колаборативна фільтрація — це один із найпоширеніших підходів до формування персоналізованих рекомендацій. В основі методу — ідея про те, що смаки схожих користувачів можуть бути ключовими орієнтирами для нових пропозицій.
Цей підхід поділяється на два основні типи:
Орієнтація на користувачів.
У цьому варіанті система шукає користувачів зі схожими інтересами, поведінкою або історією покупок, як у цільового клієнта. Вивчивши їхні вподобання, система пропонує товари, які були популярні серед цих «двійників».
Орієнтація на об'єкти (товари):
Тут фокус зміщується на аналіз товарів, з якими взаємодіяли інші користувачі. Система вивчає великі масиви даних про те, які товари переглядали чи купували разом, і на основі цих зв’язків формує релевантні рекомендації для користувача.
Такий спосіб формування рекомендацій певною мірою схожий на контентно-орієнтовані підходи, оскільки також шукає схожі товари. Але є ключова різниця: у контентній фільтрації аналізуються внутрішні характеристики самих товарів (наприклад, колір, бренд, тип), тоді як колаборативна фільтрація враховує ще й колективну поведінку користувачів: їхні перегляди, покупки та інші дії.
Переваги:
- ефективно працює навіть тоді, коли про товари є мінімум описової інформації;
- дає змогу виявляти складні, неочевидні поведінкові патерни користувачів;
- часто формує більш різноманітні та неочікувані рекомендації, що можуть приємно здивувати клієнта.
Недоліки:
- обробка великої кількості взаємодій між користувачами й товарами вимагає значних обчислювальних ресурсів;
- дані про поведінку можуть бути фрагментованими або неповними, що ускладнює виявлення подібностей;
- система погано працює з новими користувачами або новими товарами, оскільки бракує історичних даних — це так звана проблема холодного старту.
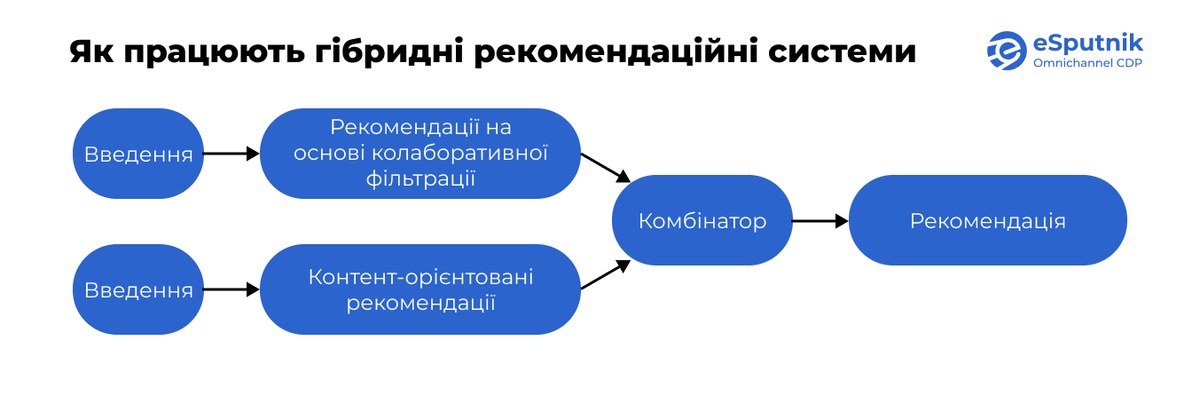
Гібридні рекомендаційні системи
Гібридний підхід передбачає поєднання кількох різних методів рекомендацій, щоб досягти більш точних і стабільних результатів. Завдяки такій стратегії можна компенсувати недоліки кожного окремого методу й підсилити загальну ефективність системи.
Найчастіше комбінують контентно-орієнтовану фільтрацію та колаборативну фільтрацію — це дозволяє одночасно враховувати характеристики товарів і поведінку користувачів.
Існують різні варіанти реалізації гібридних систем. Наприклад:
- модель може незалежно створювати рекомендації за кожним методом, а потім поєднувати результати в один список;
- або ж система обирає підхожий алгоритм залежно від контексту — наприклад, на початковому етапі використовується контентний підхід, а з накопиченням даних — колаборативна фільтрація.
Переваги:
- завдяки поєднанню кількох алгоритмів система охоплює ширший спектр користувацьких інтересів і властивостей товарів;
- комбінований підхід дозволяє створювати більш точні та персоналізовані рекомендації;
- гібридна модель допомагає нейтралізувати слабкі місця окремих методів, зокрема проблему «холодного старту» та нестачу повних даних.
Недоліки:
- поєднання різних алгоритмів збільшує навантаження на обчислювальні ресурси;
- налаштування ефективної взаємодії між методами може бути технічно складним процесом;
- розробка, тестування та підтримка гібридних систем зазвичай складніші, ніж реалізація одного окремого підходу.
Попри те, що кожен з описаних методів має свої переваги, саме гібридні моделі найчастіше забезпечують найвищу точність рекомендацій.
Трансформери: нове покоління рекомендаційних моделей
Попри свою назву, трансформери не мають нічого спільного з популярними іграшками Hasbro — натомість вони стали революційним інструментом у сфері штучного інтелекту. Вперше цю архітектуру представила команда Ашиша Васвані у 2017 році в роботі «Attention is All You Need», яка згодом докорінно змінила підхід до обробки послідовностей даних.
Уже в 2018-му Google інтегрував трансформерну модель BERT (Bidirectional Encoder Representations from Transformers) у свій пошуковий алгоритм, зробивши її невіддільною частиною сучасного вебу. Трохи пізніше компанія OpenAI представила GPT-2 — власну реалізацію трансформерів, що поклала початок новій епосі генеративного ШІ.
Чим трансформери корисні для рекомендацій
Сучасні моделі ML ідеально підходять для обробки даних, які мають часову або логічну послідовність — наприклад, історія переглядів, кліки, покупки тощо. Вони здатні вловлювати тонкі зв’язки між подіями в історії користувача, аналізувати контекст і визначати значущість кожної дії.
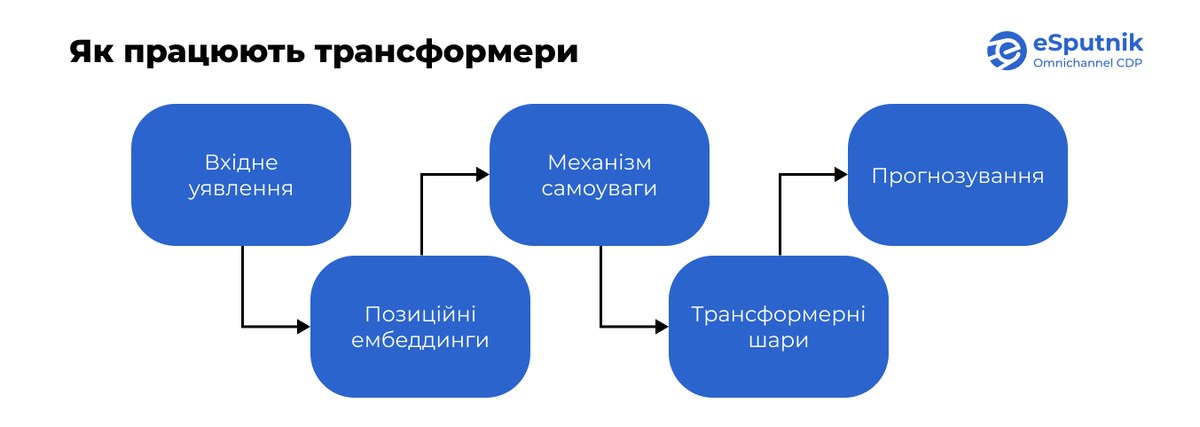
Основні етапи роботи трансформерної моделі в рекомендаціях:
- Початкове представлення. Усі дії користувача (наприклад, перегляд товару) та характеристики самих товарів кодуються у вигляді числових векторів — ембеддингів.
Ембеддинги: як система «розуміє» дані
У трансформерах усі вхідні дані — товари, дії користувача, додаткові характеристики — перетворюються на ембеддинги, тобто вектори чисел, які є зрозумілими для моделі машинного навчання. Це спеціальний спосіб представлення інформації у цифровому вигляді, оптимізований для подальшої обробки.
На перший погляд, ембеддинги схожі на звичайні масиви даних. Але є принципова різниця:
- звичайні масиви містять «людинозрозумілі» атрибути, наприклад: [«сорочка», «М», «білий»];
- ембеддинги виглядають як набір чисел, наприклад: [0.12, –0.08, 0.45, … –0.34], і не мають прямої інтерпретації для людини, але в них зашифрована складна багатовимірна інформація про сутність.
Завдяки такому представленню система може ефективно виявляти схожості, тренди та закономірності, які практично неможливо помітити людині.
- Позиційні ембеддинги. Щоб трансформер розумів не лише що саме зробив користувач, але й у якій послідовності це відбулося, до основних ембеддингів додаються позиційні ембеддинги. Останні зберігають інформацію про порядок дій — наприклад, чи перегляд товару відбувся до додавання в кошик, чи навпаки. Таким чином система аналізує контекст подій, а не просто окремі взаємодії.
- Механізм самоуваги (self-attention) — ключовий компонент трансформерної архітектури. Саме він дає змогу моделі визначити, які саме елементи в послідовності мають найбільше значення. Наприклад, якщо користувач переглянув 10 товарів, але придбав лише один, механізм самоуваги дозволяє зосередитись на взаємодіях, які найбільше вплинули на рішення про покупку і, відповідно, на основі цього будувати точніші рекомендації.
Самоувага дозволяє алгоритмам зважувати важливість різних характеристик товару залежно від контексту завдання. Наприклад, розглянемо товар — iPhone 15 Pink 256 ГБ. Завдяки механізму self-attention модель може визначити, що ключовими ознаками для пошуку є слова «iPhone» і «15», а додатковою інформацією — колір та обсяг пам’яті, тобто «Pink» і «256 ГБ».
В залежності від мети:
- для класифікації конкретної моделі телефона найбільшу вагу отримає поєднання «iPhone» та «15»;
- якщо ж завдання — рекомендувати аксесуари, які підходять за кольором, найбільш релевантним буде параметр «Pink».
Самоувага допомагає моделі гнучко виділяти найважливіші аспекти у різних сценаріях.
- Трансформерні шари. На цьому етапі модель уточнює подання окремих елементів послідовності, враховуючи весь контекст взаємодій. Це дозволяє ефективно виявляти залежності навіть між тими елементами, які розташовані далеко один від одного у послідовності.
- Прогнозування. Після обробки даних трансформерними шарами система отримує глибоке розуміння послідовності користувацьких дій і використовує його для прогнозування наступного товару, з яким користувач, ймовірно, захоче взаємодіяти. Такий прогноз можна застосувати для:
- ранжування товарів за релевантністю,
- формування персоналізованих списків рекомендацій.
Завдяки здатності працювати з послідовними даними та розпізнавати складні поведінкові патерни трансформери є надзвичайно ефективними для прогнозування подальших дій користувачів.
Переваги рекомендацій на основі трансформерів
Трансформерні моделі відкривають нові можливості для ecommerce завдяки своїм унікальним перевагам, а саме:
Вища точність прогнозів. Трансформери забезпечують більш релевантні та персоналізовані рекомендації, що безпосередньо впливає на збільшення продажів, підвищення кліків (CTR) та покращення загального досвіду користувачів.
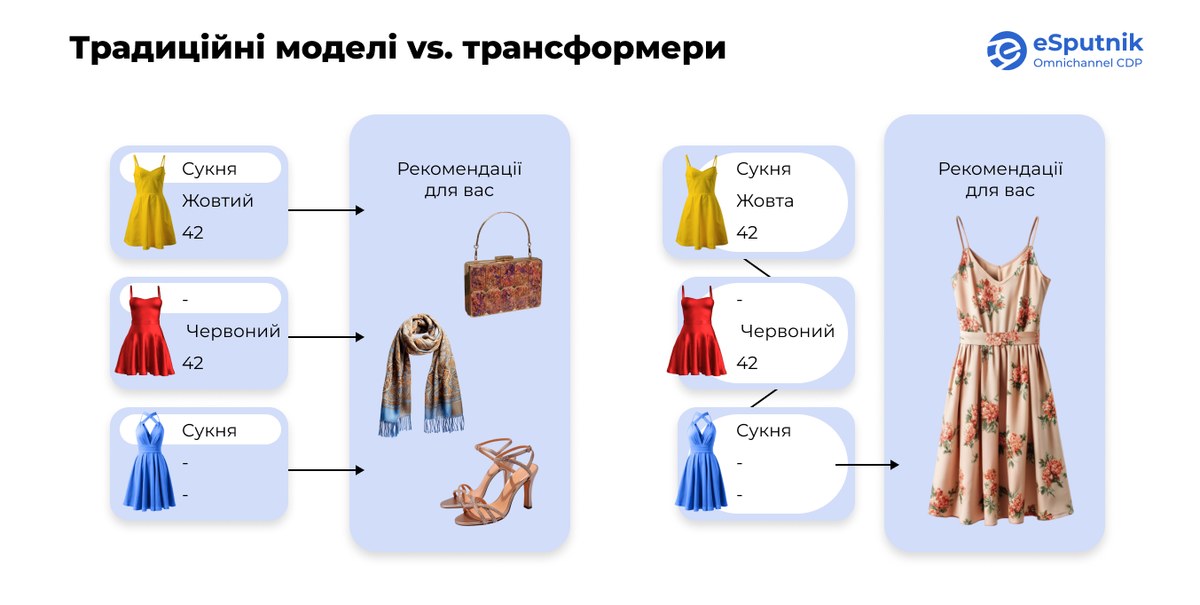
Аналіз повної історії користувача. Головна перевага трансформерів у тому, що вони аналізують всю послідовність взаємодій користувача, а не лише окремі точки даних. Раніші моделі будували рекомендації на основі кожної події окремо, що часто призводило до менш точних висновків.
Наприклад, уявімо, що клієнт придбав три книги, присвячені Стародавньому Риму: вигадану історію, історичний нарис і біографію римського імператора, написані різними авторами. Традиційні підходи могли б запропонувати йому біографію середньовічного короля або книгу про історію Стародавньої Греції — оскільки вони не враховують логічну послідовність тем.
Натомість сучасна модель ML проаналізує всю низку покупок і розпізнає інтерес користувача саме до тематики Риму, тому з більшою ймовірністю запропонує релевантні книги в цьому напрямку.

Трансформери краще вирішують завдання обробки неповних або суперечливих даних. Завдяки здатності працювати з різнорідною та частково відсутньою інформацією, модель вміє виділяти найбільш релевантні факти з усього доступного набору даних.
Це можна порівняти зі складанням пазла, у якому бракує кількох частинок — трансформер заповнює пропуски, використовуючи наявну картину про дії користувача, щоб відновити весь пазл. Така властивість особливо цінна для бізнесів, які не мають можливості або ресурсів для комплексної обробки та структурування своїх даних, наприклад, інформації про товари.
Хоча трансформери є потужним інструментом, вони мають певні обмеження порівняно з іншими моделями:
- Високі вимоги до ресурсів. Налаштування і запуск трансформерних моделей потребують значних обчислювальних потужностей і великого обсягу оперативної пам’яті. Якщо плануєте створювати власну систему, варто бути готовими інвестувати в потужні графічні процесори, серверне обладнання або оплачувати використання хмарних платформ.
- Велика потреба у даних. Незважаючи на здатність працювати з неповними даними, трансформери потребують значних обсягів інформації для коректного навчання і прогнозування. Для малого бізнесу, де профіль клієнта часто неповний, простіші алгоритми можуть бути більш ефективними та економічними.
- Складність розробки. Створення рекомендаційних систем на базі трансформерів вимагає високої кваліфікації фахівців, яких наразі не так багато. Через це часто недоцільно будувати власні рішення самотужки, адже підтримка і розвиток потужних систем ML можуть бути дорогими та ресурсозатратними.
Як працюють рекомендації на основі трансформерів на прикладі української CDP eSputnik
Раніше в CDP eSputnik застосовувалися гібридні рекомендаційні системи, які базувалися на колаборативній фільтрації та інших підходах.
З квітня 2024 року ми вдосконалили наші трансформерні моделі, інтегрувавши їх із технологією LLM (великі мовні моделі). LLM застосовує передові можливості штучного інтелекту для глибшого розуміння мови, що дозволяє детальніше аналізувати поведінку користувачів, їхні вподобання та характеристики товарів. Це суттєво підвищило точність рекомендацій, забезпечуючи клієнтам більш релевантні та персоналізовані пропозиції.
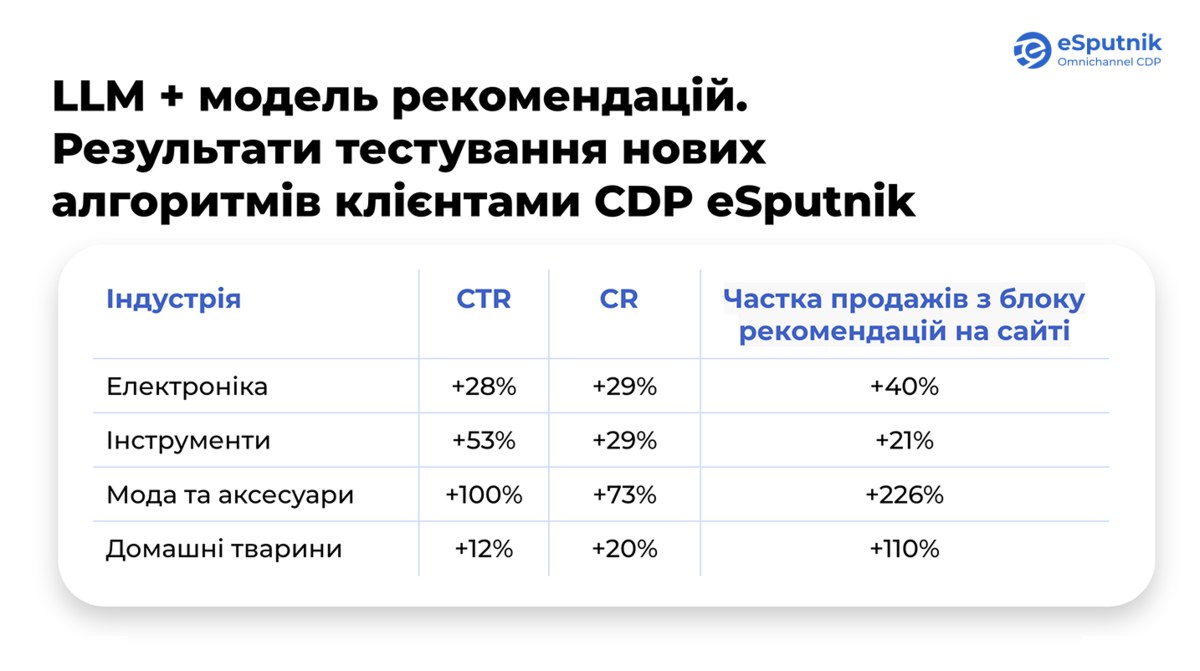
У травні–червні 2024 року ми протестували оновлені товарні рекомендації та порівняли їхні результати з показниками за січень–лютий того ж року.
Для оцінки ефективності ми обрали три ключові показники:
- Клікабельність (CTR, click-through rate) — відношення кількості кліків на нові рекомендації до показників у базовому (вихідному) періоді
- Конверсії — кількість покупок, здійснених користувачами через нові блоки рекомендацій, порівняно з попереднім періодом.
- Частка замовлень, що надійшли з рекомендованих блоків, відносно загальної кількості продажів на сайті.
Dnipro-M
Dnipro-M — виробник і продавець будівельних інструментів, який займає близько 30% українського ринку. Компанія також працює у кількох країнах Східної Європи, зокрема в Чехії, Польщі та Молдові.
Результати використання покращених алгоритмів формування рекомендацій:
+105% — CTR;
+43% — конверсії;
+116% — частка замовлень.
MasterZoo
MasterZoo — одна з провідних мереж зоомагазинів в Україні, що налічує понад 200 фізичних точок та має великий інтернет-майданчик.
Результати використання покращених алгоритмів формування рекомендацій:
+46% — CTR;
+71% — конверсії;
+76% — частка замовлень.
Yakaboo
Yakaboo — провідний український інтернет-магазин книг, що працює з 2004 року і пропонує видання більш ніж 70 мовами.
Результати використання покращених алгоритмів формування рекомендацій:
+10% — конверсії;
+126% — частка замовлень.
Висновки
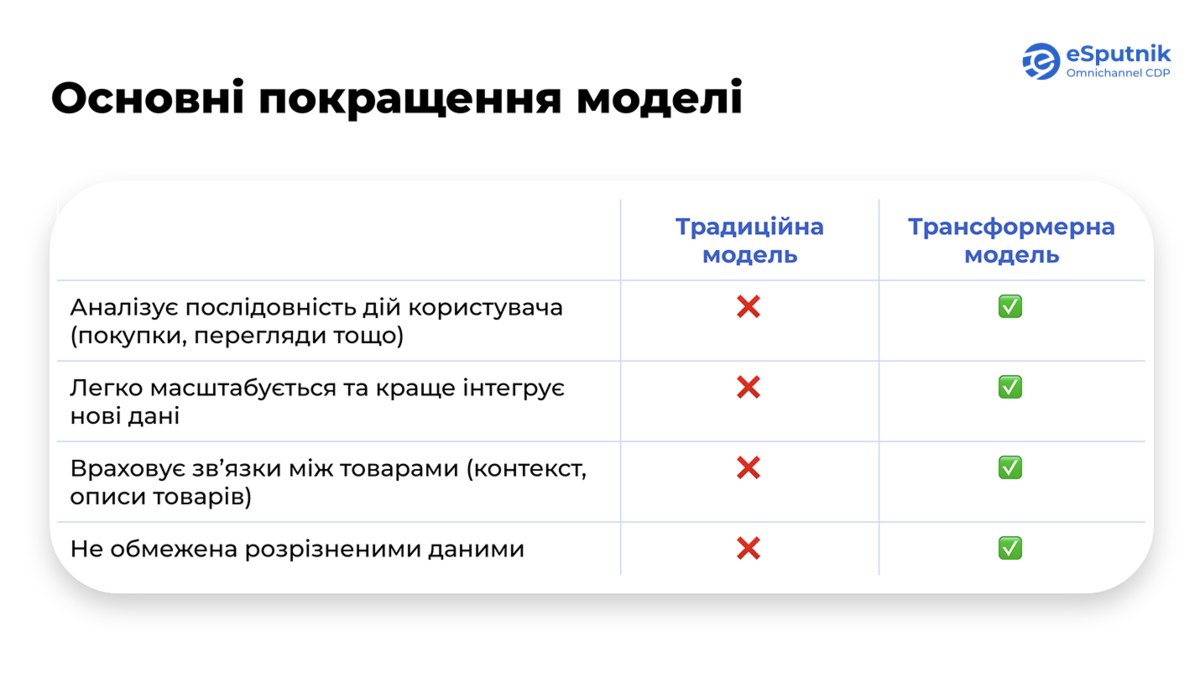
Раніше товарні рекомендації будувалися переважно на історії кліків і покупок, використовуючи колаборативну та контентну фільтрацію. Вони добре працювали на базовому рівні, але мали обмеження: не враховували контекст поведінки, не працювали з неструктурованими даними, важко масштабувалися при великому каталозі та часто не могли дати точні результати для нових користувачів чи товарів.
Ці недоліки усунула трансформерна модель у поєднанні з великими мовними моделями. Вона аналізує послідовність дій користувача — від переглядів і пошуків до реальних покупок, легко масштабується та швидко інтегрує нові дані. Модель враховує зв’язки між товарами, включно з їхніми описами й контекстом використання, а також працює з неповними даними.
Результати українських компаній Dnipro-M, MasterZoo та Yakaboo підтверджують переваги нової архітектури товарних рекомендацій. Перехід на трансформерну модель + LLM дав приріст у десятки відсотків за ключовими метриками: CTR, конверсія, частка замовлень із рекомендацій. Це доводить, що нове покоління рекомендаційних систем не просто вдосконалює існуючі рішення, а відкриває якісно інший рівень персоналізації, який напряму впливає на прибутковість бізнесу.