Маркетинг пройшов величезний шлях еволюції за тисячоліття свого існування — від найпростіших форм комунікації до сучасних високотехнологічних екосистем. Разом із галуззю трансформувалися й робочі інструменти фахівців. Ключовою мотивацією цього розвитку завжди залишається прагнення до максимальної ефективності результатів. Одночасно з цим зростає необхідність скорочення часу на виконання рутинних операцій — в умовах жорсткої конкуренції та великого обсягу завдань маркетологи просто не можуть дозволити собі ручне виконання всіх процесів.
Це пояснює динамічне зростання сфери автоматизації маркетингу. Сьогодні з використанням ШІ в таких платформах створюється контент, формуються персоналізовані товарні рекомендації, а стандартні завдання та робочі процеси оптимізуються. Подібний підхід гарантує отримання кращих результатів при суттєвому зменшенні витрат часу.
Протягом тривалого періоду сегментація вважалася однією з найскладніших для автоматизації. Але завдяки появі сегментації за допомогою штучного інтелекту стало можливим формування клієнтських груп в автономному режимі з паралельним підвищенням якості отриманих результатів.
Предиктивна сегментація — це передова технологія, яка дозволяє глибоко аналізувати клієнтську поведінку для оптимізації маркетингових кампаній. Завдяки алгоритмам штучного інтелекту стало можливим прогнозування готовності клієнта до покупки, а також ймовірності втрати клієнта. Завдяки цьому можна створювати відповідні цільові групи та правильно працювати з ними.
Мета цієї статті — надати всебічний огляд підходів, які формують основу предиктивної сегментації, та їхнього практичного впровадження у вирішенні конкретних бізнес-завдань. Якщо ви хотіли розібратись, як саме ШІ навчився передбачати результати, але не маєте достатніх технічних та аналітичних знань — ця стаття саме для вас.
Основи предиктивної сегментації у порівнянні з дескриптивними (описовими) підходами
Сегментація забезпечує поділ клієнтської аудиторії на різні групи на основі спільних характеристик. Класичний варіант реалізації цього процесу передбачає ручне виконання відповідно до бізнес-цілей. Наприклад: реклама певного товару виключно для жіночої аудиторії, або доступна виключно для користувачів застосунку.
Такі стратегії належать до категорії дескриптивних (описових), їхнє завдання полягає у групуванні вже наявної інформації про клієнтів, тобто фактично їх характеристик.
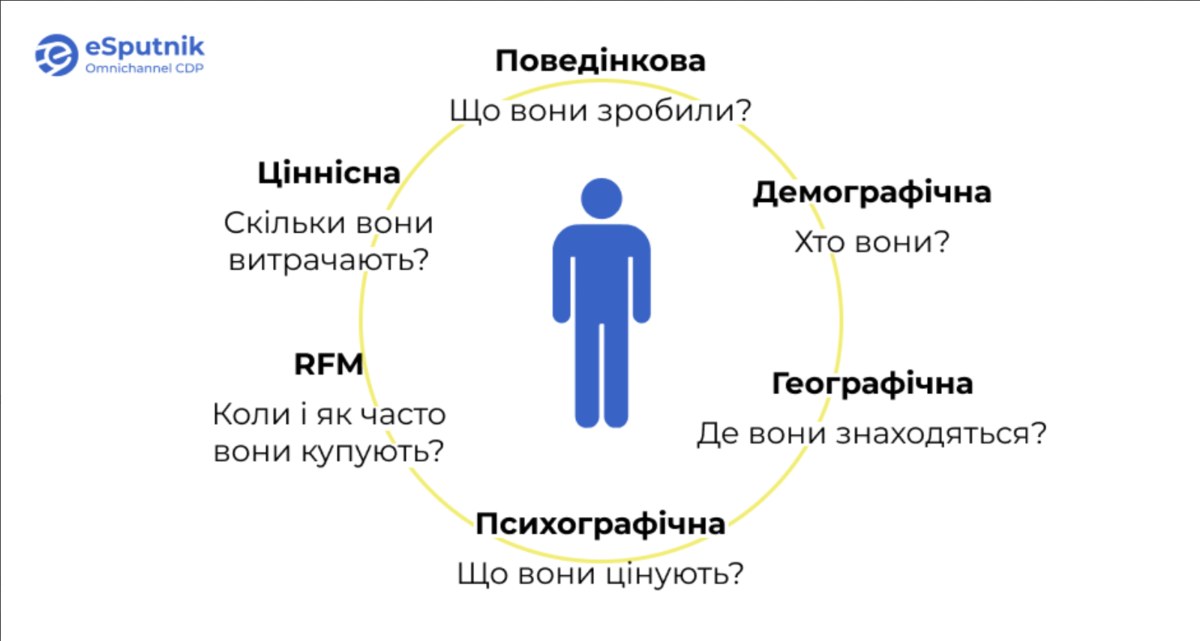
Найпоширеніші підходи описового методу:
Демографічна сегментація
Цей базовий підхід передбачає розподіл клієнтів відповідно до їхніх спільних ознак: вікових параметрів, гендеру, рівня доходу та освіти. Зокрема, преміальні бренди можуть фокусуватися на заможній аудиторії старше 40 років, тим часом як масові торгові марки орієнтуються на молодших споживачів із середнім рівнем заробітку.
Сучасні інструменти надають маркетологам можливість створювати складніші поєднання параметрів, приміром: «заміжні жінки 25-34 років з вищою освітою», що забезпечує спрямування маркетингових зусиль та налаштування продуктів під конкретну аудиторію.
Географічна сегментація
Локальне націлювання бере до уваги не лише фізичне місцезнаходження клієнтів, а також контекст їхнього місця проживання: урбанізовані чи сільські території, кліматичні особливості, демографічну щільність, культурні традиції регіону.
Передові методики, зокрема геофенсинг, дають можливість компаніям налагоджувати комунікацію з клієнтами у реальному часі, коли ті перебувають у визначених локаціях.
Психографічна сегментація
Цей поглиблений підхід зосереджує увагу на психологічних особливостях споживацької поведінки: способі життя, системі цінностей, сфері інтересів та світоглядних орієнтирах. Він забезпечує розуміння мотивів прийняття клієнтами конкретних рішень, формуючи такі категорії як «прихильники здорового способу життя», «любителі технологічних новинок» або «свідомі екоспоживачі».
Поведінкова сегментація
Вивчаючи особливості взаємодії клієнтів з продуктами або послугами, компанії можуть здійснювати їх розподіл базуючись на реальних діях, а не на характеристиках. Сюди входить частота здійснення покупок, рівень прихильності до бренду, активність використання продукту та відповідь на маркетингові ініціативи.
Сегментація за споживчою цінністю
Метод зосереджується на економічних аспектах взаємовідносин клієнта з бізнесом та включає розмір середньої покупки, регулярність замовлень і загальну життєву вартість клієнта (CLV). Компанії застосовують ціннісне сегментування для ідентифікації найприбутковіших та стратегічно важливих категорій клієнтів.
RFM-сегментація
Цей аналітичний інструмент покращує розуміння клієнтської бази через сегментування за трьома критичними індикаторами:
- Recency (Актуальність) — період з моменту останньої транзакції.
- Frequency (Частотність) — регулярність здійснення покупок.
- Monetary value (Монетарна вартість) — обсяг витрачених коштів.
Приклад: клієнт, який робить покупки щотижня і витрачає великі суми, представляє високу цінність для бізнесу. RFM-сегментування дозволяє компаніям виявляти найцінніших клієнтів та розробляти стратегії для їхнього утримання.
Механізми роботи предиктивної сегментації
Тоді як дескриптивна сегментація спирається на чітко визначені правила та критерії (наприклад, «клієнти із витратами понад $100 за попередній місяць» або «жінки 25–35 років»), предиктивна сегментація використовує принципово інший механізм.
Замість застосування фіксованих правил вона вивчає патерни у історичних клієнтських даних з метою передбачення майбутньої активності. Наприклад, замість простого аналізу попередніх транзакцій, система здатна виявляти приховані тенденції, які сигналізують про ймовірність нового замовлення у найближчій перспективі.
Сила такого підходу криється у можливості обробки великих масивів взаємопов’язаної інформації. Маркетолог під час створення сегментів зазвичай концентрується на 3–4 ключових змінних — врахування більшої кількості стає складним завданням та збільшує вірогідність помилок. Проте алгоритми машинного навчання спроможні паралельно обробляти сотні різних параметрів. Це охоплює не тільки очевидні індикатори на кшталт історії покупок і демографічних характеристик, а також ледь помітні зміни у веб-поведінці клієнта, його реакції на попередні кампанії, сезонні коливання та навіть тимчасові проміжки між відвідуваннями сайту.
Алгоритми не аналізують окремі змінні у відриві від контексту. Вони розкривають складні звʼязки в історичних даних клієнтів та передбачають їхні наступні дії. Скажімо, предиктивна модель може виявити, що клієнти, які відвідують вебсайт у вечірні години робочих днів, систематично переглядають email-розсилки та здійснили мінімум дві покупки у різних товарних категоріях, з високою ймовірністю позитивно відреагують на чергову промоакцію.
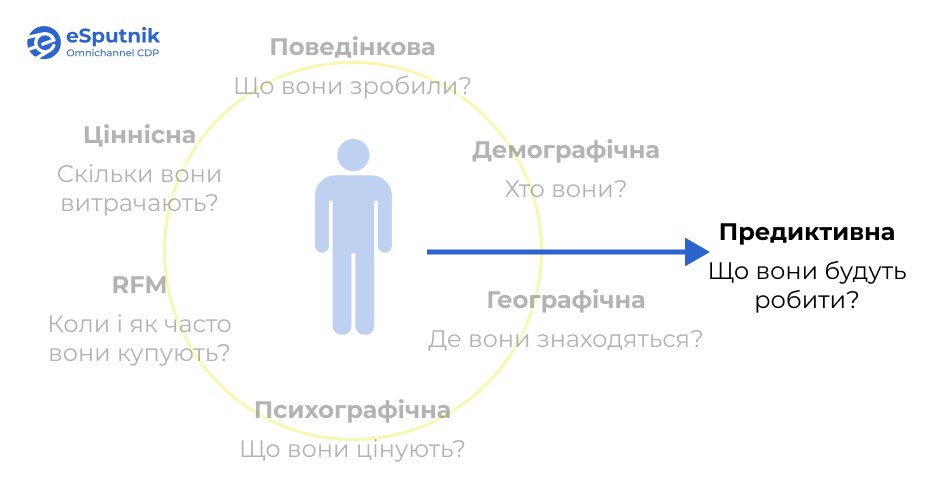
Ретроспектива проти прогнозування: ключова відмінність
Принципова різниця між дескриптивною та предиктивною сегментацією полягає у їхньому ставленні до часу. Описові сегменти незмінно орієнтовані на минуле — вони лише досліджує активності, які клієнти вже реалізували, або їхній актуальний стан. Предиктивна сегментація натомість дає відповідь на питання, яке має справжнє значення для бізнесу: «Які кроки зробить цей клієнт у майбутньому?»
Замість екстраполяції минулих дій вона моделює майбутні. Наприклад, замість сегмента «клієнти з частими покупками у минулому», АІ формує групу «клієнтів із високою ймовірністю покупки впродовж найближчих двох тижнів» — навіть якщо частина з них не відповідає традиційному профілю активного покупця.
Предиктивна сегментація в деталях
Базове розуміння, що відбувається «під капотом» предиктивної моделі допоможе маркетологу краще розуміти технологію та приймати правильні рішення щодо доречності її використання.
Інформаційна база як фундамент
Перше, що важливо розуміти — предиктивна сегментація працює з величезним обсягом даних. Чим більше якісної інформації про клієнта доступно, тим вищою буде точність прогнозів. Точність та комплексність даних безпосередньо визначають результативність таких моделей. Основні типи інформації, які потрібні для побудови точних прогнозів:
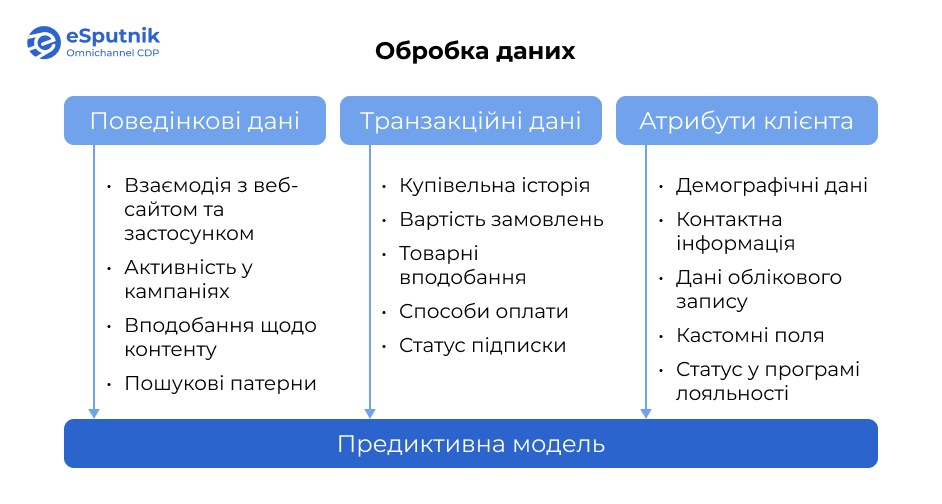
Поведінкові дані:
- Активність на сайті, у мобільному додатку: відвідані сторінки, тривалість сесій.
- Рівень залучення у кампанії: відкриття email, переходи за посиланнями, реакція на пропозиції.
- Контентні вподобання: опрацьовані статті, переглянуті відео, досліджені товари.
- Пошукова активність: запити на вашому веб-ресурсі.
Транзакційні дані:
- Історія купівель: які товари купуються та у які періоди.
- Розмір середнього чека: типові суми витрат.
- Товарні вподобання: улюблені категорії та конкретні продукти.
- Платіжні методи: найчастіше використовувані способи оплати тощо.
Дані про клієнтів
- Основні демографічні показники: вік, місце проживання, стать.
- Контактні дані: пріоритетні канали зв’язку.
- Давність профілю: тривалість життєвого циклу.
- Індивідуальні поля: специфічні дані, релевантні для вашого бізнесу.
- Лояльність: участь у бонусних програмах (якщо є).
Важливо: для початку роботи не потрібна вся ця інформація — алгоритми прогнозування можуть працювати з тими даними, які вже є у бізнеса. Поступово, із накопиченням більшої кількості даних, точність прогнозів буде зростати.
Робота з даними про клієнта
Якщо ви користуєтеся хоча б одним програмним рішенням для маркетингової автоматизації, то вже збираєте цінну інформацію про клієнтів. Однак перед тим, як ці дані стануть працювати у системі предиктивної сегментації, важливо забезпечити їх очищення, уніфікацію та зберігання. Вони мають бути зрозумілими та доступними для ШІ.
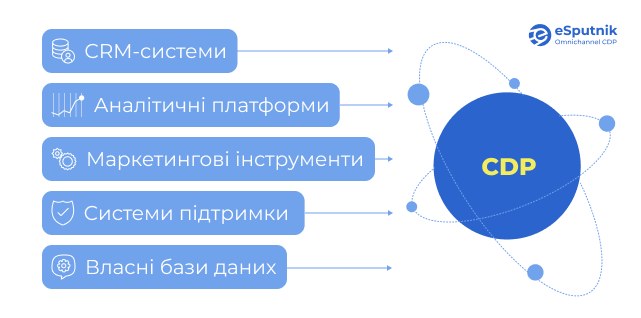
Найкращим варіантом є наявність єдиного профілю клієнта, який консолідує дані з усіх доступних джерел. Такий профіль забезпечують платформи клієнтських даних (customer data platform або CDP).
CDP є центральним хабом, який:
- збирає інформацію з різних джерел у єдиний клієнтський профіль;
- забезпечує оновлення даних у режимі реального часу;
- гарантує консистентність інформації між різними системами;
- надає можливість використання даних та забезпечує фунціональність предиктивних моделей та інших ШІ-рішень, таких як трансформерні моделі рекомендацій і генерація контенту для кампаній.
Як побудована модель
Після підготовки даних система починає пошук історичних закономірностей для прогнозування клієнтської поведінки. Це нагадує з’єднання множини точок у ваших даних для формування цілісного розуміння того, які дії можуть вказувати на майбутню поведінку клієнтів.
Залежно від того, що саме потрібно спрогнозувати, система застосовує різні типи моделей. Найпоширенішим методом для аналізу клієнтської поведінки є класифікація, де завданням є розподіл клієнтів на дві групи відповідно до їхніх ймовірних дій (наприклад, покупці vs. не покупці).
Для маркетингу класифікаційні моделі особливо цінні, оскільки вони допомагають отримати відповіді на практичні питання:
- Чи здійснить цей клієнт покупку упродовж наступних 30 днів?
- Чи є ризик того, що цей клієнт припинить користуватися нашими послугами?
Моделі досліджують послідовності у минулих кейсах клієнтів, які вже виконали\не виконали конкретні дії.
Як відбувається навчання системи
Система опрацьовує історичні дані для розуміння минулих закономірностей. Скажімо, якщо потрібно спрогнозувати, які клієнти здійснять покупку протягом місяця, модель вивчає дві групи клієнтів із минулого: тих, хто здійснив покупку протягом 30 днів, та тих, хто цього не зробив.
Для кожної групи вона аналізує сотні різних чинників: коли клієнт останній раз відвідував сайт, які сторінки переглядав, чи відкривав розсилки, як часто робить покупки та які товари обирає, як взаємодіє з брендом.
Поступово система починає розпізнавати, які комбінації цих факторів найточніше свідчать про майбутні покупки. Деякі патерни можуть бути зрозумілими (користувачі з частими відвідуваннями сайту мають вищу ймовірність покупки). Інші можуть бути складнішими та майже непомітними для ручного аналізу.
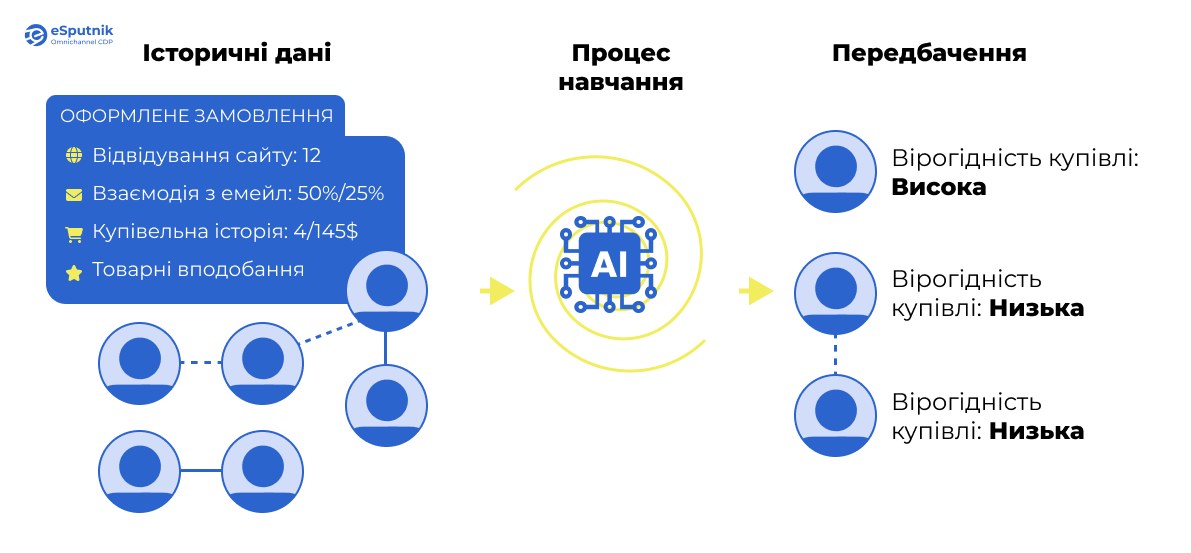
Перетворення патернів у прогнози
На цьому етапі входить у гру класифікація — метод, який розподіляє клієнтів у різні групи залежно від імовірності здійснення певної дії. Приміром, система eSputnik може класифікувати клієнтів наступним чином:
- «Дуже висока ймовірність купівлі» (80%+ ймовірності);
- «Висока ймовірність купівлі» (50-80% ймовірності);
- «Низька ймовірність купівлі» (20-50% ймовірності);
- «Мінімальна ймовірність купівлі» (менш як 20% ймовірності).
Ці показники формуються на основі подібності поточної поведінки клієнта до сценаріїв, які раніше призводили до покупок.
Система постійно оновлює ці прогнози. Наприклад, клієнт, якого минулого тижня класифікували як «низькоймовірного покупця», може потрапити до категорії «висока ймовірність купівлі» після активної взаємодії з вашою останньою email-кампанією.
Оцінка ефективності моделей
Для кращого розуміння оцінки предиктивних моделей уявіть наступну ситуацію: перед вами знаходиться величезний стіг сіна, у якому заховано голки різних форм і розмірів.
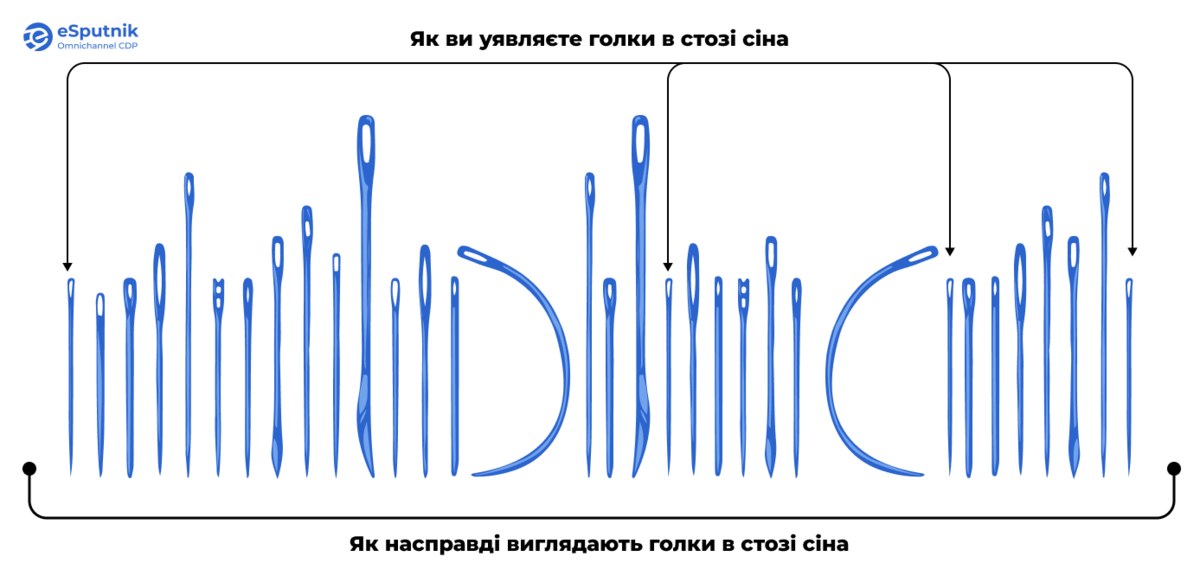
Для досягнення мети ви конструюєте спеціальне сито, яке просіює сіно та виявляє голки. Це, образно кажучи, ваша предиктивна модель. Однак, оскільки голки відрізняються за формою та розміром, а сіно не є однорідним, сито іноді залишатиме голки у сіні, а іноді пропускатиме сіно, помилково ідентифікуючи його як голки. Як розв’язати цю проблему?
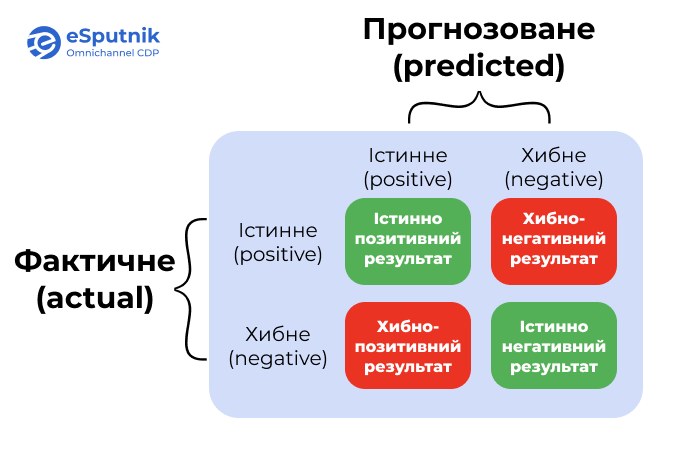
Матриця помилок (Confusion Matrix)
У предиктивному моделюванні для опису таких ситуацій застосовується матриця помилок (Confusion Matrix). Це таблиця 2×2, яка покриває всі можливі сценарії класифікації:
- Істинно позитивний результат: модель коректно передбачає позитивний клас. Це коли ваше сито правильно відфільтровує та знаходить голку.
- Хибнопозитивний результат: модель прогнозує позитивний результат там, де його немає. Це коли сито ідентифікує соломинку, помилково сприймаючи її як голку.
- Хибнонегативний результат: модель не виявляє позитивний клас, хоча він присутній. Це ситуація, коли сито не знаходить голку у сіні, хоча повинно було її відфільтрувати.
- Істинно негативний результат: модель коректно ідентифікує негативний клас. Ваше сито залишає соломинку там, де їй місце.
Ключові метрики оцінювання предиктивних моделей
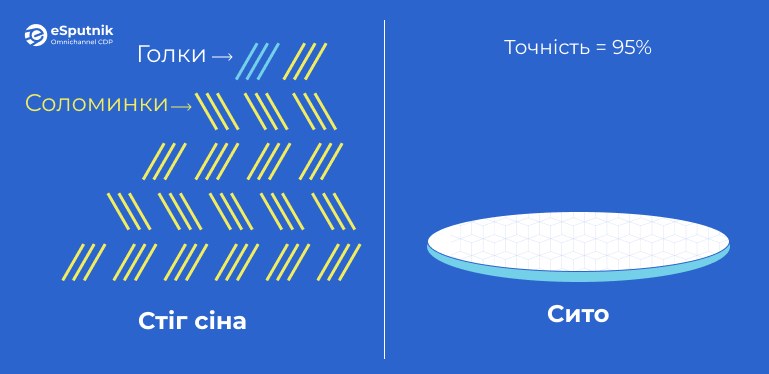
Загальна точність (Accuracy)
Загальна точність обчислюється як співвідношення коректно спрогнозованих значень до загальної кількості прогнозів.

Це формула, яка добре підходить для первинної оцінки та збалансованих наборів даних. Проте загальна точність не завжди підходить для складніших сценаріїв та незбалансованих наборів даних.
Розглянемо приклад: у вас є 5 голок і 95 соломинок. Модель може класифікувати все як соломинки, і загальна точність складе 95%. Хоча це виглядає як гарний результат, насправді ми не отримали жодної голки зі стогу.
Сфери застосування загальної точності:
- Збалансовані набори даних — метрика точності дає надійні результати, коли кількість позитивних і негативних прикладів у наборі приблизно однакова;
- Низька вартість помилок — якщо хибнопозитивні та хибнонегативні результати мають однакову важливість або не спричиняють серйозних наслідків (наприклад, фільтрація спаму);
- Первинна оцінка моделі — часто точність застосовується як первинний показник ефективності моделі, перш ніж перейти до глибшого аналізу з використанням прецизійності, повноти або F1-міри.
Прецизійність (Precision)
Прецизійність (precision, точність позитивних передбачень) — одна з двох найкритичніших метрик у процесі оцінювання моделі. Вона вимірює точність позитивних прогнозів і обчислюється як співвідношення усіх коректно передбачених позитивних випадків до загальної кількості випадків, які модель класифікувала як позитивні.
У більшості сценаріїв прецизійність є більш надійною метрикою, ніж загальна точність, особливо у ситуаціях, коли помилково позитивні результати є більш критичними.
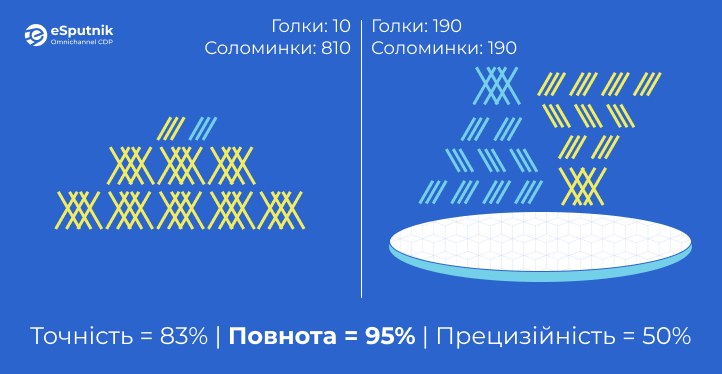
Повертаючись до прикладу зі стогом сіна: якщо наша модель ідентифікувала 100 предметів як голки, і насправді 90 з них виявилися справжніми голками, а 10 були соломинками, то точність позитивних класифікацій становить 90%.
Висока прецизійність використовується, коли потрібно мінімізувати кількість хибнопозитивних результатів.
Прецизійність важлива, коли хибнопозитивні результати є критичнішими за хибнонегативні. Приклади:
- Виявлення шахрайських операцій у фінансових системах — помилкове блокування легітимних транзакцій викликає незадоволення клієнтів.
- Спам-фільтрація — допомагає уникати позначення важливих листів як спаму.
- Пошукові системи — прецизійність гарантує, що користувачі бачать саме релевантні результати.
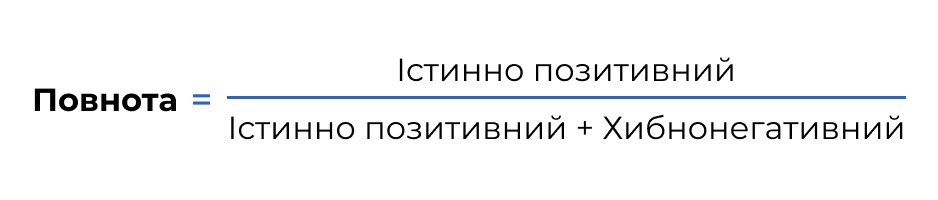
Повнота (Recall)
Повнота, яку ще називають чутливістю чи рівнем істинно позитивних результатів, вимірює спроможність моделі знаходити всі позитивні випадки та розраховується як співвідношення коректно передбачених позитивних випадків до всіх фактичних позитивних прикладів у наборі даних.
На відміну від точності позитивних класифікацій, яка концентрується на коректності позитивних прогнозів, повнота виявлення зосереджує увагу на ідентифікації якомога більшої кількості істинно позитивних випадків.
Якщо у стозі всього 200 голок, а ми знайшли лише 90 з них, то ми пропустили 110 голок, що означає повноту виявлення 45%. Ця модель неефективно справляється з ідентифікацією всіх позитивних випадків.
Чим вища повнота, тим більше голок ви ідентифікували
Між точністю позитивних класифікацій та повнотою виявлення існує компроміс: підвищення однієї часто призводить до зниження іншої.
Наприклад, в CDP eSputnik ми використовуємо повноту як основну метрика для оцінювання предиктивних моделей. Під час сегментації клієнтів помилка в ідентифікації когось як клієнта має мінімальні наслідки. Водночас пропуск потенційних покупців у маркетингових кампаніях може призвести до зниження доходу.
Повнота критична, коли пропуск справжніх позитивів неприпустимий:
- Медична діагностика: Для онко- та інших небезпечних хвороб важливо виявити максимальну кількість випадків, навіть ціною кількох хибнопозитивів.
- Маркетингові кампанії: Щоб охопити весь потенційний попит, бізнес готовий ризикувати розсилкою небажаним адресатам.
- Прогнозування катастроф: При землетрусах чи фінансових кризах краще помилково сповістити зайвий раз, ніж пропустити критичну подію.
Можна помітити, що висока прецизійність моделі автоматично означає низьку повноту, і навпаки.

F1-показник
F1-показник — це гармонійне середнє між точністю позитивних класифікацій та повнотою, яке допомагає оцінити баланс між ними. Він застосовується, коли важливо враховувати як помилково позитивні, так і помилково негативні прогнози.
F1-показник є найбільш цінним у випадках, коли точність позитивних класифікацій і повнота виявлення мають однакову важливість, та для незбалансованих наборів даних.
Предиктивна сегментація на практиці
Як приклад розберемо предиктивну сегментацію на базі української ІТ-компанії CDP eSputnik. Платформа надає передову модель машинного навчання для сегментації клієнтів на основі ймовірності здійснення покупки — найважливішого показника для електронної комерції.
Для створення цих прогнозів модель аналізує широкий спектр інформації, включаючи історію покупок, вартість і частоту минулих замовлень, дату останньої активності клієнта, поведінкові патерни, демографічні дані та інші чинники.

ШІ здатний аналізувати набагато більшу кількість даних та взаємозв’язків між ними
Такий підхід дозволяє обробляти та аналізувати більше інформації, ніж може опрацювати навіть найдосвідченіший маркетолог.
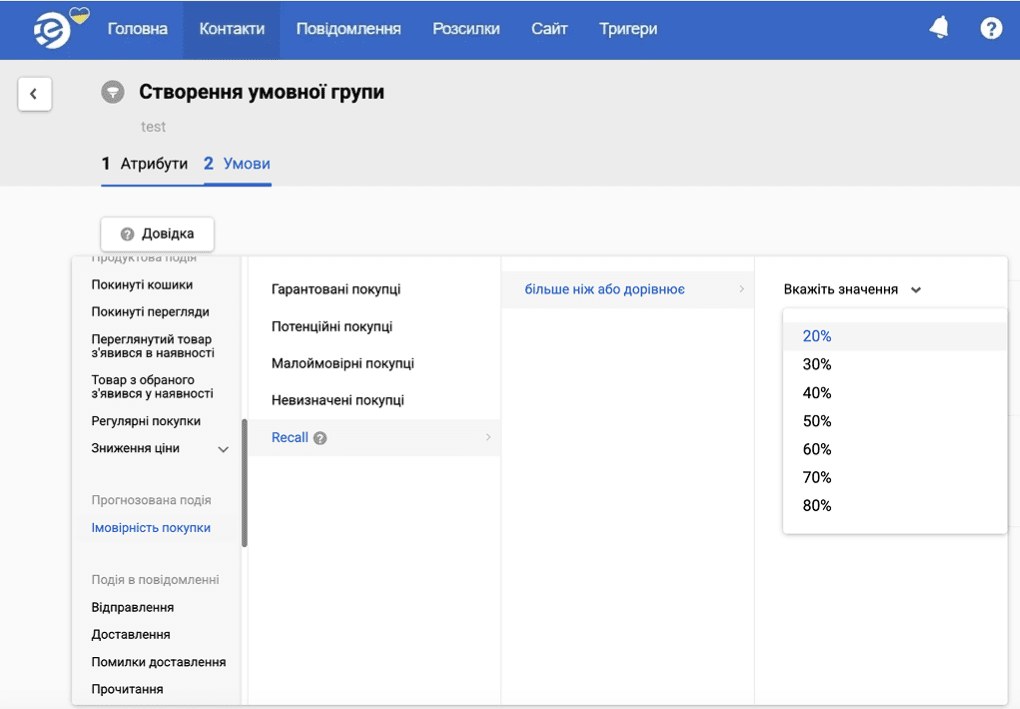
Для створення предиктивного сегмента можна обрати один із чотирьох готових пресетів, або встановити значення повноти вручну — від 20% до 80%.
Значення повноти визначає кількість потенційних покупців у сегменті:
- Нижчі значення (20-50%) формують вужчий сегмент із вищою точністю позитивних класифікацій, що означає краще співвідношення покупців до не покупців. Це ідеально підходить для високоточних кампаній або коли основна мета — досягти максимального ROMI.
- Вищі значення (60-80%) створюють ширший сегмент, який охоплює більше потенційних покупців, але має нижчу точність позитивних класифікацій. Застосовуйте цей підхід, якщо потрібно максимізувати охоплення та збільшити загальний дохід.
Щоб спростити створення предиктивних сегментів для маркетолога в системі eSputnik є готові пресети:
- Гарантовані покупці — з найвищою ймовірністю покупки, для цієї групи можна робити ексклюзивні пропозиції, преміальних товарів.
- Потенційні покупці — із помірною або високою ймовірністю покупки, добре реагують на сезонні розпродажі, запуск нових продуктів та персоналізовані рекомендації.
- Малоймовірні покупці — колишні клієнти, які тривалий час не здійснювали замовлень, їх можна повернути через кампанії повторного залучення.
- Невизначені покупці — користувачі з низькою або помірною ймовірністю покупки, їм варто пропонувати бонусні акції, освітній контент або запити на зворотний зв’язок.
Основні переваги предиктивних сегментів:
- Оперативність і легкість створення — предиктивні сегменти налаштовуються за декілька кліків
- Підвищена ефективність — алгоритми машинного навчання обробляють значно більші масиви інформації, аніж може маркетолог вручну, що дозволяє створювати більш точні сегменти.
- Оптимізація бюджету — кампанії на предиктивні сегменти особливо результативні у дорогих каналах, зокрема SMS та Viber, де критично важливо оптимізувати витрати на повідомлення.
- Інноваційні сценарії автоматизації — окрім підвищення конверсії, предиктивні сегменти сприяють виявленню інших критичних подій, наприклад відтоку клієнтів, що дає можливість розробляти кампанії з утримання аудиторії.
- Удосконалене A/B тестування — предиктивні сегменти забезпечують точніші результати, що робить їх ідеальними для тестування різних креативів, пропозицій та змінних кампаній.
Кейс застосування предиктивної сегментації: O.TAJE
Український бренд жіночого одягу O.TAJE суттєво покращив ефективність Viber-кампаній завдяки предиктивній сегментації. Протягом червня-серпня 2024 року команда тестувала предиктивні сегменти та порівнювала їх з сегментами створеними вручну маркетологом. Одна з предиктивних кампаній продемонструвала такі результати:
- Відкриття повідомлень: 57,83%, порівняно з 45,24% у ручному сегменті.
- Конверсія: 5,73%, порівняно з 5,14%.
- ROMI: 1010,89%, порівняно з 389,19%.
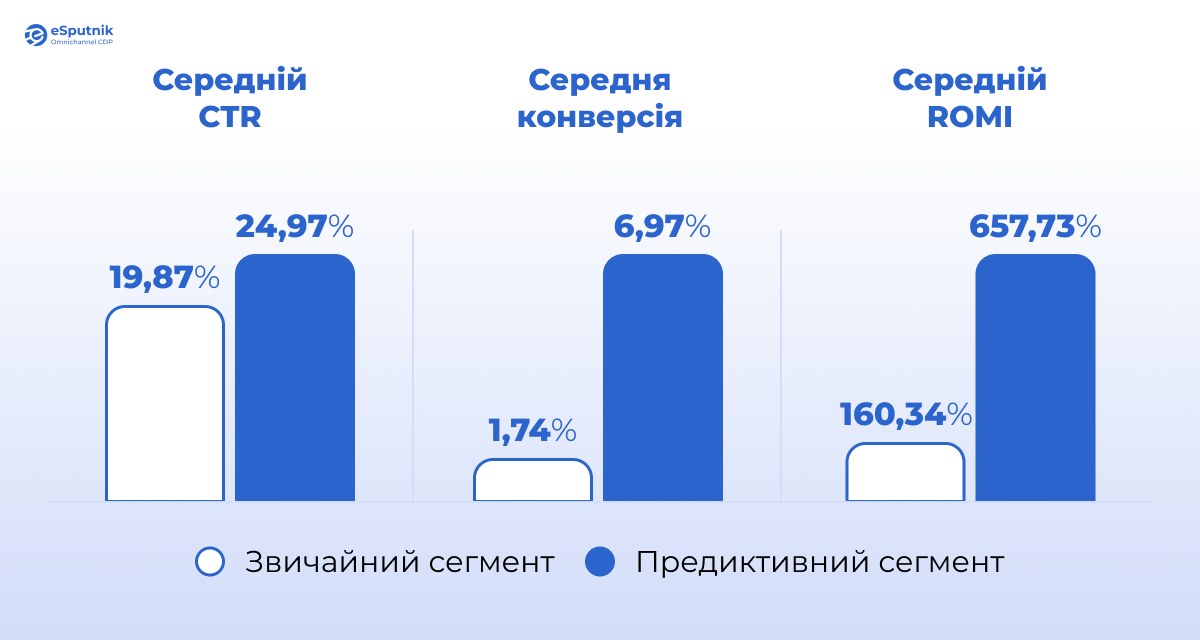
Загальні покращення показників при використанні предиктивних сегментів:
- +26% CTR
- +300% зростання конверсії
- +310% збільшення загального ROMI
Враховуючи ці результати, O.TAJE планує масштабувати предиктивну сегментацію та впроваджувати її в SMS-кампаніях.
Підсумки
Тепер ви маєте всі необхідні знання про технологію предиктивної сегментації. У статті ми розглянули:
- ключові відмінності між предиктивною та описовою сегментаціями;
- типи даних, що використовуються для прогнозування поведінки клієнтів;
- принципи роботи предиктивних моделей;
- способи оцінки їхньої ефективності.

Предиктивна сегментація — це стратегічний ресурс, який у поєднанні з AI-алгоритмами та можливостями CDP відкриває нові горизонти для аналітики, персоналізації та управління клієнтським досвідом. Інструмент дає змогу оптимізувати маркетингові кампанії, підвищити їхню результативність і глибше розуміти потреби вашої аудиторії. Застосування предиктивної сегментації не лише підвищує конверсії та скорочує витрати, а й сприяє зростанню лояльності клієнтів. Застосовуйте інноваційні технології для свого бізнесу та будьте попереду конкурентів!